

对于程序员而言,编译和链接天天都在接触,每次用IDE一键Build的时候,内部的工具链都会走编译 & 链接的过程。
IDE和编译器已经给程序员提供了完善的封装,以至于大部分人不需要去深入探究什么是编译,什么是链接。
但如果长时间困在温室,当遇到莫名其妙的Build错误时,就会抓耳挠腮。这就是本章的意义,看看这个过程到底做了什么?
被隐藏了的过程
还是从最经典的Hello,World开始。
arduino 代码解读复制代码#include
当我们需要运行程序时,可以直接使用IDE比如Clion,点击右上角的绿色小标就跑起来了。
但是如果手动构建,需要怎么做的?
代码解读复制代码gcc hello.c
gcc是一款C语言编译器,这个命令的含义是输出一个可执行文件。

多了个 a.out,执行一下,直接输出Hello World!

这里面发生了很多事情,我们可以笼统的概括成下面一个流程图。
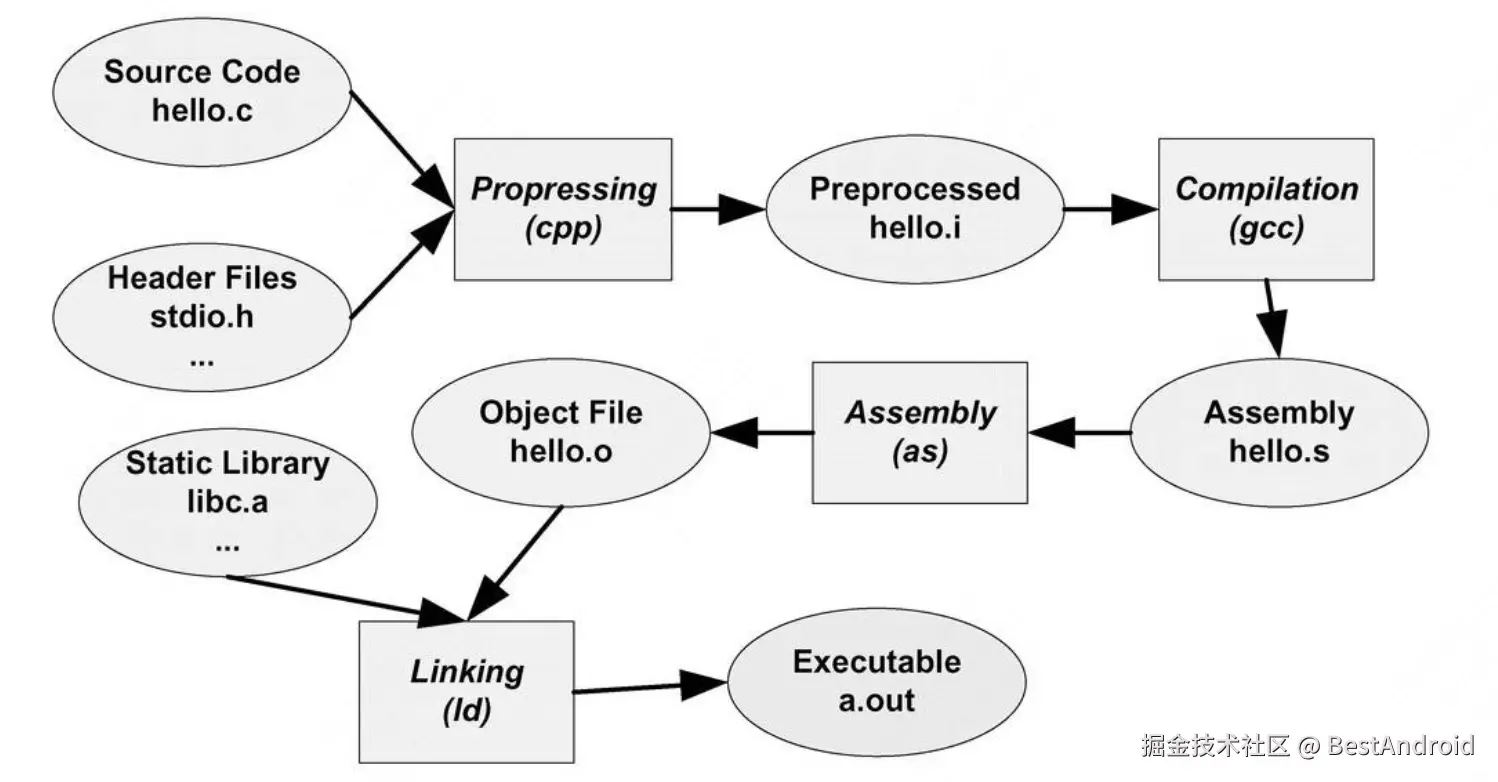
首先把源文件hello.c和源文件内声明的头文件 stdio.h经过预处理生成 hello.i,再经过编译,变成hello.s,再经过汇编,变成hello.o目标文件,把目标文件和静态库通过链接器链接,就得到了可执行文件a.out
预处理(预编译)
预处理的输入是源文件和文件内部的头文件,输出是hello.i文件。对应命令
代码解读复制代码gcc -E hello.c -o hello.i
-E 表示只进行预处理(-e 和 -E完全不一样, gcc是区分大小写的),-o 控制输出的文件名。
预处理主要处理源文件中以#开头的预编译指令,比如#include, #define 等,规则:
- 把头文件的内容,直接插入进来,比如
#include - 把宏定义展开,
#define - 处理条件编译指令,
#if,#ifdef,#elif,#else,#endif - 处理其他编译指令
#pragma,#error....
#pragma warning(disable: 4996) // 禁用警告C4996
#error 强制中断编译,并输出错误信息
- 删除所有的注释
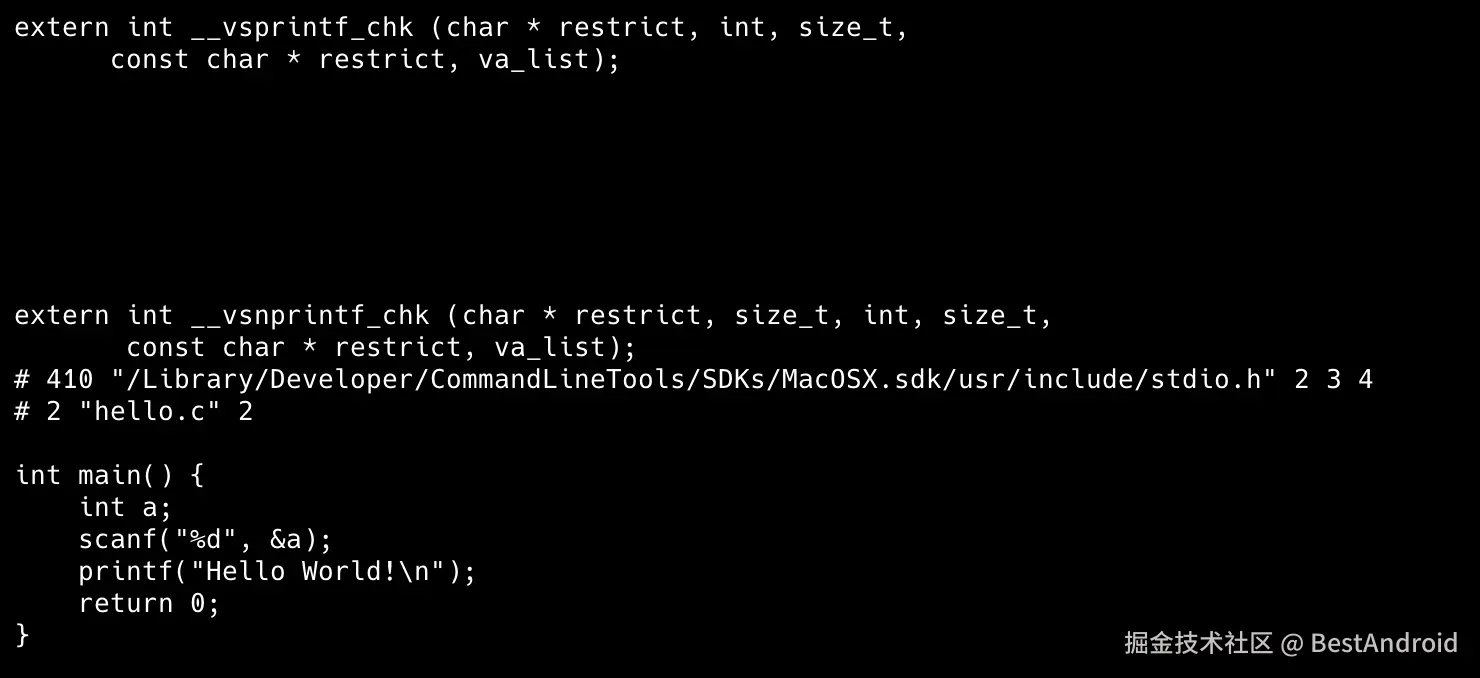
- 添加行号和文件名标识,比如 #2 "hello.c" 2,以便于编译器产生调试用的行号信息。
把hello.i里面最后一个片段截取出来,上面一堆#include展开的内容,可以看到已经被插入进来了,下面是源代码:
编译
编译的过程就是把预处理完的文件,进行一系列的词法分析,语法分析,语义分析,及优化后产生相应的汇编代码文件。
为什么这里的编译,产生的是个汇编的文件,后面不是还有一次汇编吗?有啥区别?
这里编译产生的是汇编语言的代码,也就是.s文件,后面的汇编是把汇编语言的代码转换成对应目标平台的机器码
编译命令
代码解读复制代码gcc -S hello.i -o hello.s
现代gcc把预处理和编译合并成一个步骤,使用一个叫cc1的程序来完成,可以直接 cc1 hello.c效果是一样的。
对于c++来说,也有对应的程序叫 cc1plus ,objective-c是 cc1obj,java是jc1。
jc1已经是历史产物,当年可以直接把java直接编译到对应的机器平台。目前已经不能这么搞了。
现代java已经跟gcc没关系了,靠javac去编译java
看下hello.s产物内容,果然,全是汇编代码。
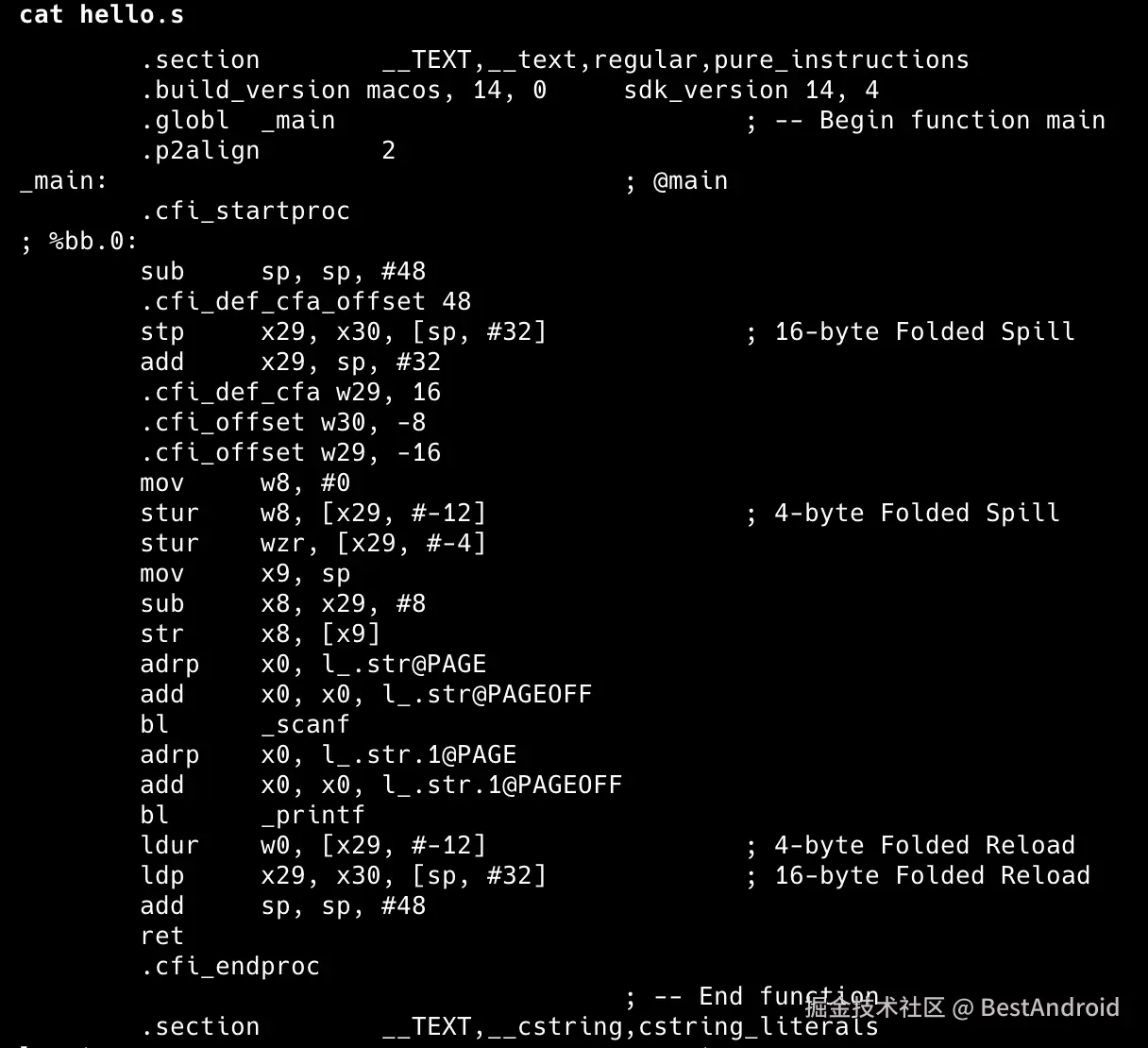
这一部分的详细内容涉及到编译原理的知识,这节没讲什么,只是强调一下这个编译的步骤而已,具体后面会讲。
汇编
汇编的作用是把编译阶段的产物也就是汇编代码变成机器可以执行的指令,每一个汇编语句几乎都一一对应着机器指令。所以汇编过程很简单,没有复杂的语法,没有语义,也不需要做什么优化,根据汇编指令和机器指令的对照表,翻译就行了。
这个对照表,就是芯片厂商的手册规范
汇编命令
r 代码解读复制代码gcc -c hello.s -o hello.o
可以看到,已经变成二进制文件了。
链接
链接主要功能:
- 符号解析,比如A文件中引用了B文件的函数。
- 地址重定位,确定函数在最终地址空间的位置,然后把函数调用地址修正。
- 段合并,把多个.o文件的
text段合并 - 生成可执行文件,安装ELF格式封装,设置入口点
_start
在目标文件和可执行文件中,代码和数据按功能分为不同的段,比如
.text代码段
为什么要合并多个文件的.text段?因为要统一代码布局,优化内存使用。
书上链接命令:
vbnet 代码解读复制代码ld -static /usr/lib/crt1.o /usr/lib/crti.o /usr/lib/gcc/i486-linux-gnu/4.1.3/crtbeginT.o -L/usr/lib/gcc/i486-linux-gnu/4.1.3 -L/usr/lib -L/lib hello.o --start-group -lgcc -lgcc_eh -lc --end-group /usr/lib/gcc/i486-linux-gnu/4.1.3/crtend.o /usr/lib/crtn.o
我用的mac,肯定不能这么写,现在mac都不支持静态链接了
mac上链接的命令:
bash 代码解读复制代码ld hello.o -o hello.out -lSystem -syslibroot $(xcrun --show-sdk-path) -arch arm64 -e _main
最终执行。

对于java来说预处理,编译,汇编,链接这些对应着什么
java没有显示的预处理阶段,但是可以通过注解处理器,来实现类型的预处理过程。
对于编译阶段,c语言是直接转换为.s的汇编代码。java是把.java文件编译为JVM字节码(.class文件)
汇编阶段,c语言是把.s的汇编代码变成.o的机器平台相关的机器码,java因为是跨平台语言,肯定不能直接编译成目前平台的机器码
所以他把这部分工作都交给了JVM。由jvm在运行时解释执行把中间代码一句句的翻译成机器平台的目标代码。
链接阶段,c语言是把多个目标文件合并成可执行文件,java是分为两个阶段。
- 在编译时做符号解析,确定类,方法和字段的合理性,不做内存地址的确定。
- 在运行时,做真正的链接操作,就是大家经常说的类加载过程,由JVM完成,核心就是解析字节码中的符号引用,然后替换为直接引用的内存地址。
编译器做了什么
直观角度,编译器就是把高级语言翻译成机器语言的一个工具。
对应到编译过程来说,有6步,扫描,语法分析,词法分析,源代码优化,代码生成和目标代码优化。
整个过程如图:
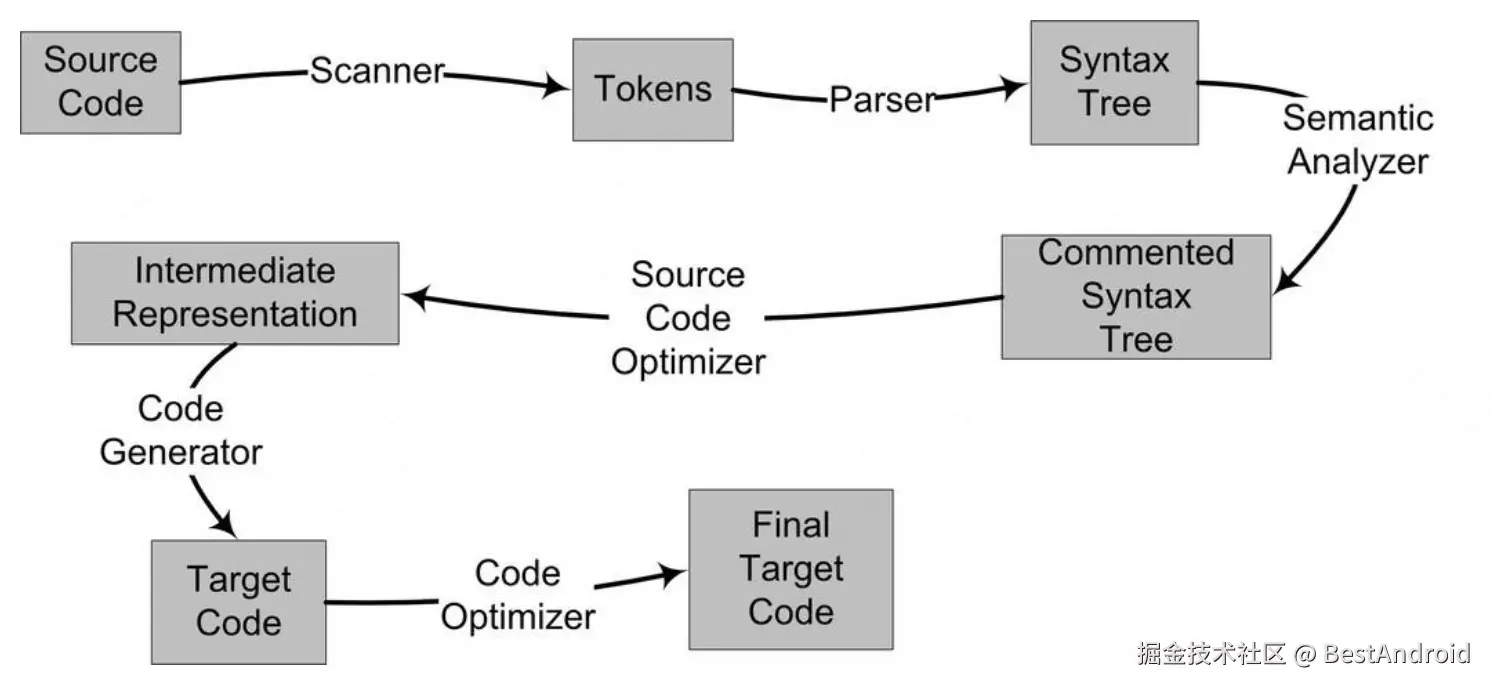
下面将结合图里面的这6步,讲述从源代码到最终目标代码的过程。
以一行简单的C语言代码为例。
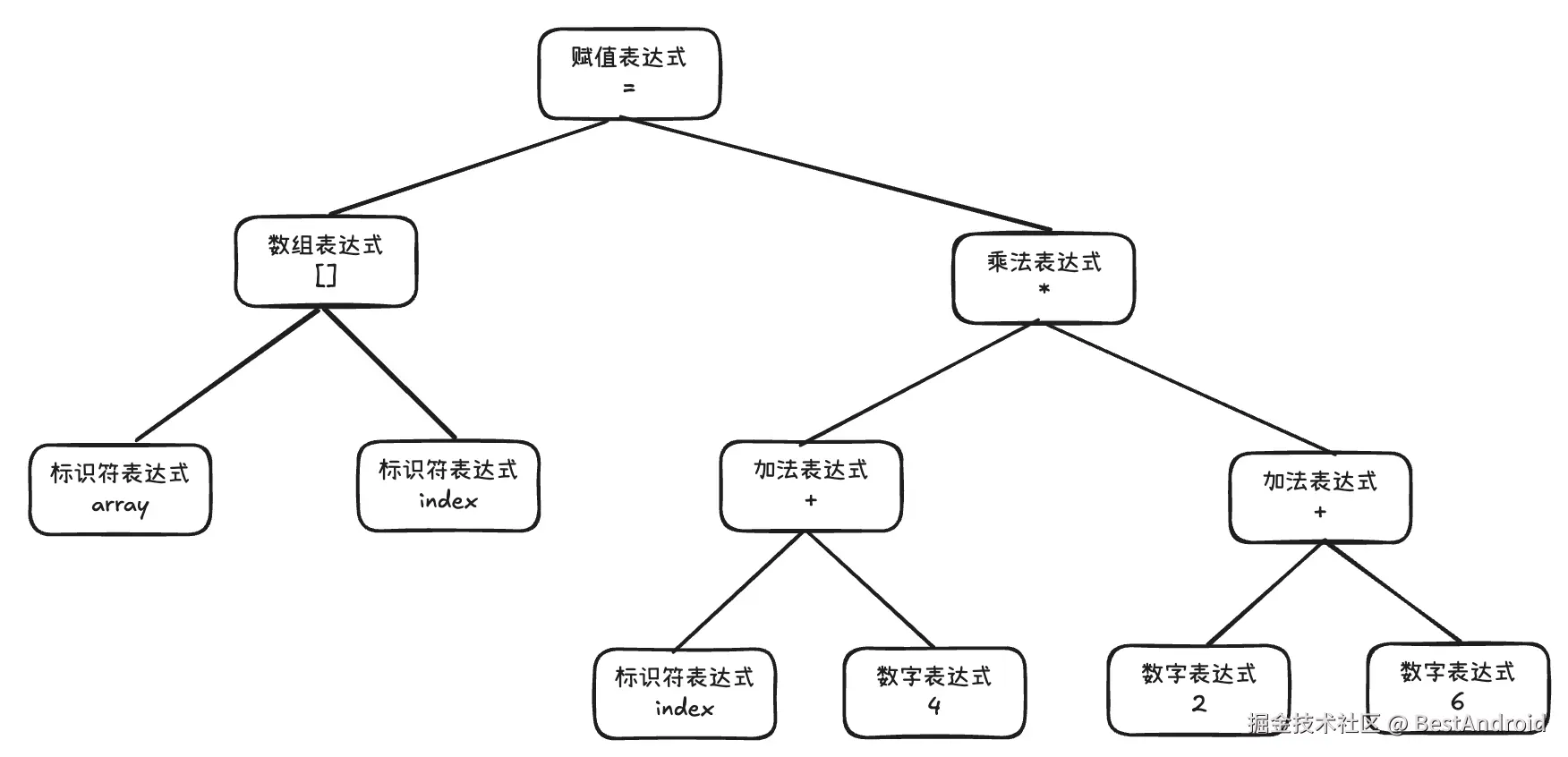
scss 代码解读复制代码array[index] = (index + 4) * (2 + 6)
词法分析
先描述这个东西是做什么的:
首先把源代码输入到扫描器(Scanner)中,扫描器进行词法分析,运用一种类似于有限状态机(Finite State Machine)的算法可以把源代码的字符串分割成一系列记号(Token)。
有限状态机是什么?
把有限这个词去掉,直接说状态机吧。
其实计算机的本质就是个状态机,定义初始状态(变量初始化),定义转移规则(if else for 分支,循环逻辑),定义结束条件。状态机做的所有事情,都是从上一个状态(变量),根据转移规则,计算出下一个状态,不断循环。
再来说有限这个词,他指的是,状态的数量是有限的,比如门,只有两种状态(开门,关门),所以他也能叫有限状态机hhh。
最后回到词法分析的有限状态机上来,就是定义了一系列的词法解析规则(转移规则),然后根据输入,不断的解析(得到下一个状态)的程序
结果如下:
| 记号(Token) | 类型 |
|---|---|
| array | 标识符 |
| [ | 方括号 |
| index | 标识符 |
| ] | 右方括号 |
| = | 赋值 |
| ( | 左圆括号 |
| index | 标识符 |
| + | 加号 |
| 4 | 数字 |
| ) | 右圆括号 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字 |
| + | 加号 |
| 6 | 数字 |
| ) | 右圆括号 |
可以看到,词法分析产生的记号分为几类:关键字,标识符,字面量(包含数字,字符串等),特殊符号(加号,减号)。在识别记号的同时,扫描器也会把标识符存放到符号表,将字面量(数字,字符串)存放到文字表
r 代码解读复制代码clang -c hello.c -o hello.o
代码解读复制代码nm hello.o
看下真实的符号表。
python 代码解读复制代码0000000000000000 T _main
U _printf
0000000000000034 s l_.str
0000000000000000 t ltmp0
0000000000000034 s ltmp1
0000000000000048 s ltmp2
有一个叫lex的程序可以实现自定义词法规则来制作词法扫描器。因此编译器的开发者就无须为每一个编译器开发独立的词法扫描器了,只需要定义词法规则
对于一些带预处理的语言,比如C语言的 #include ,它的宏替换和文件包含不归编译器管,由一个专门的预处理器去做。
语法分析
这一步,靠语法分析器(Grammer Parser) 来对输入的记号(Tokens) 使用上下文无关文法进行语法分析,最终产生语法树(Syntax Tree) 。
什么叫上下文无法文法??
先理解文法,就是指定了一组简单的规则,用来描述程序中的代码结构,比如主谓宾,也叫文法规则。
再来理解上下文无关文法,就是把每个程序按照文法的规则翻译之后,它们内部的关系是不需要理解的,比如“狗吃苹果”,“狗吃书”,都可以,因为上下文无关。
如果是上下文有关文法呢?“狗吃苹果”可以,因为苹果可以被吃,狗可以吃,“狗吃书”,不行,因为书不能被吃。
语法分析的结果是一棵语法树:
语法分析也有一个现成的工具叫yacc,它也像lex一样,只需要根据用户定义的语法规则对输入记号序列进行解析,就能构建出一棵语法树。对于不同的编程语言,编译器的开发者只需要改变语法规则就能重新适配新的语言了!
所以它也叫编译器的编译器
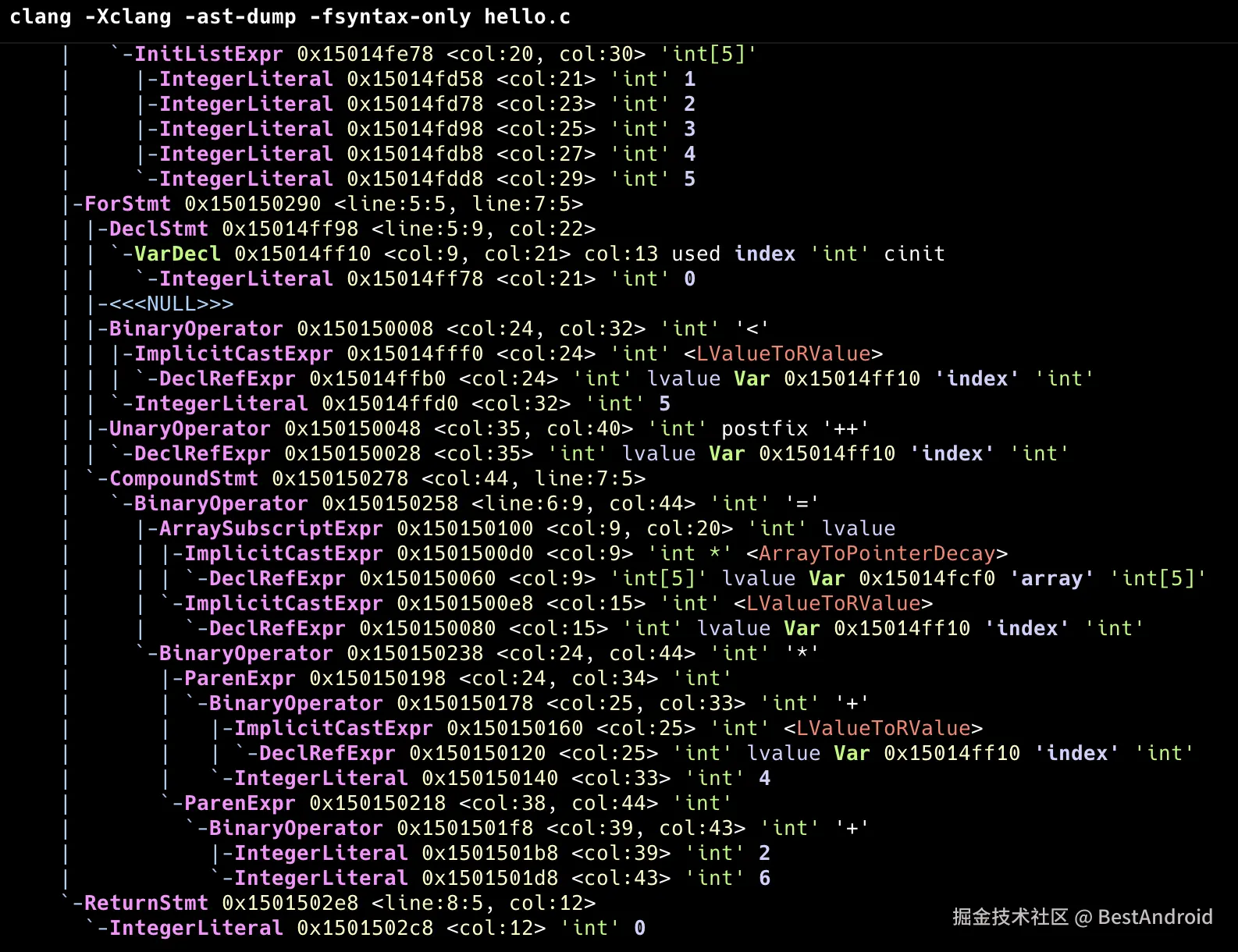
看一下语法树的到底是什么?
lua 代码解读复制代码clang -Xclang -ast-dump -fsyntax-only hello.c
语义分析
同样,语义分析,也需要一个语义分析器来完成。前面的语法分析,只是完成了对表达式语法层面的分析,但是它并不了解这个语句是否真正有意义。
比如C语言中对两个指针做乘法是没有意义的,但是这个语句在语法上是合法的。
编译器所能分析的语义是静态语义指编译阶段就能检查的语义规则。主要关注程序的合法性和一致性。它与语法(Syntax) 的区别在于:语法关注代码的结构是否符合形式规则(例如括号匹配、关键字顺序),而静态语义关注代码的逻辑正确性(例如类型是否匹配、变量是否声明)。
比如:
ini 代码解读复制代码int x = 10;
x = "hello"; // 错误:整型变量不能赋值为字符串
如果是运行期间才能确定的语义,也就是动态语义,就没办法确定了,比如
ini 代码解读复制代码int a = 0 / 3; // 0 作为除数是一个运行期的语法错误
经过语义分析阶段之后,整棵语法树的表达式都被标记了类型,如果有些类型需要做隐式转换,语义分析程序会在语法树中插入相应的转换节点。
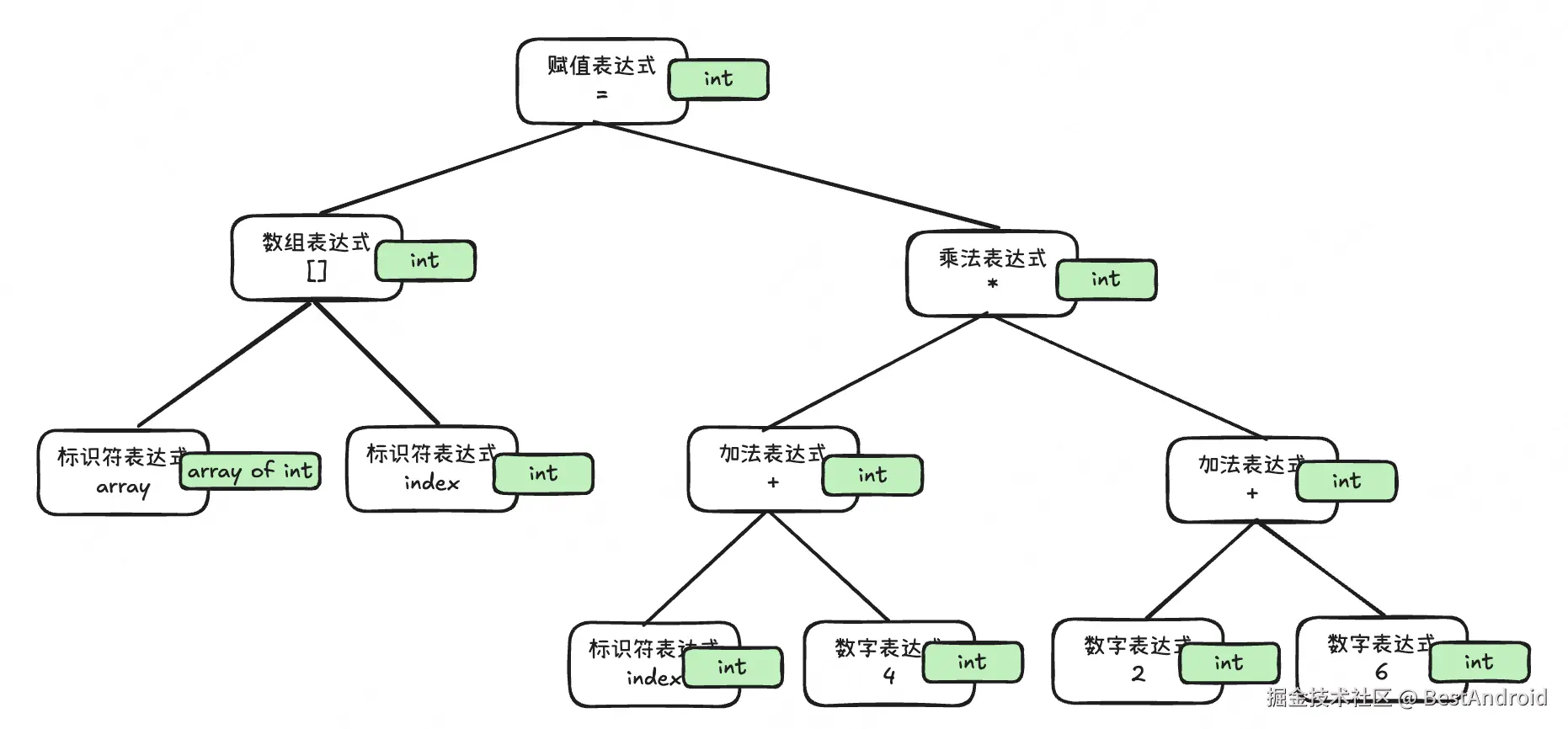
这个例子中,所有的类型,都是整形的。
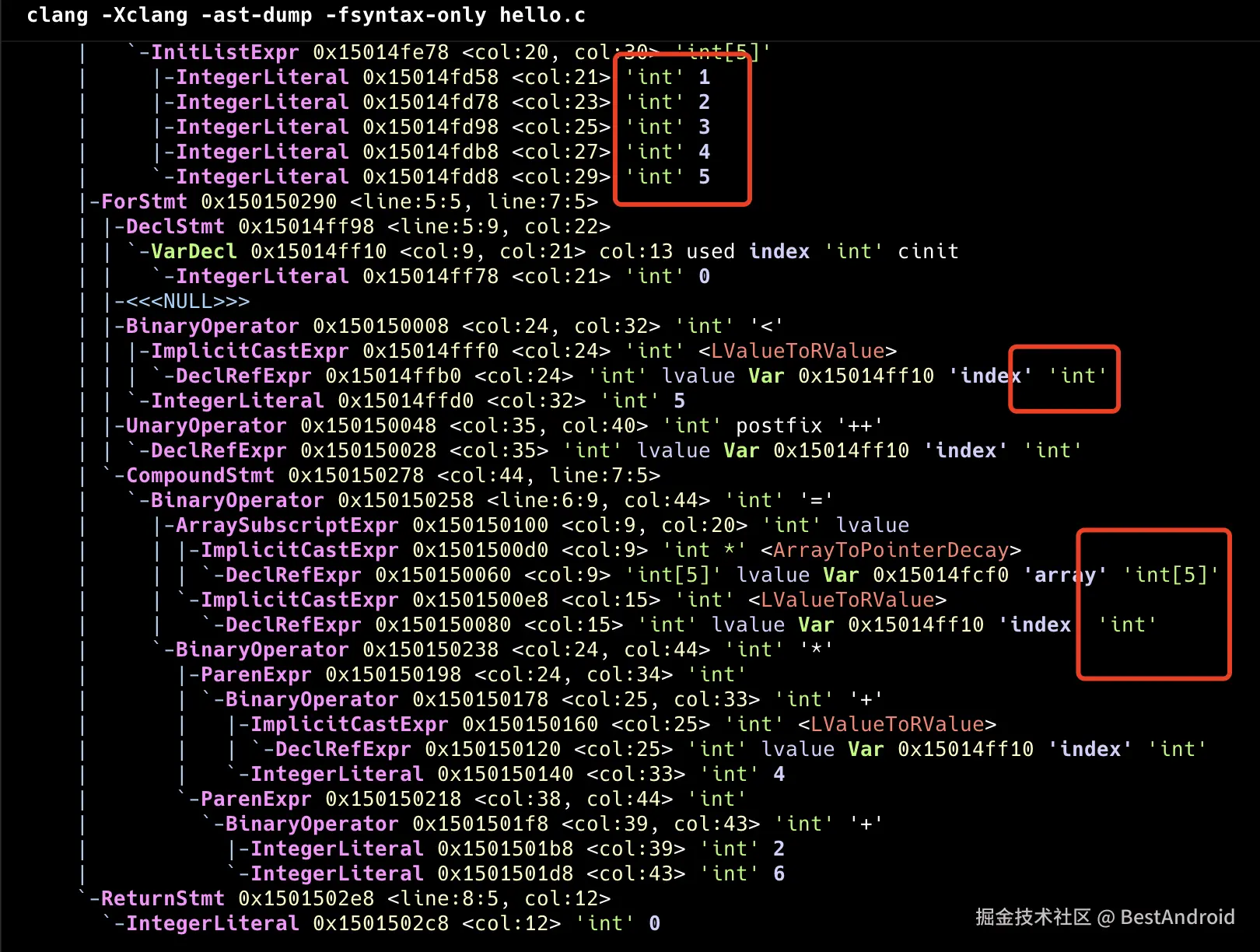
看一下真实环境下的语义信息:
中间代码生成
现代编译器有着很多层次的优化,其中一点就是对源代码的优化。这个过程会使用源码优化器来处理。
gcc本身可以支持多种语言,c,c++,go,d,fortran..。这些语言都需要针对源代码进行优化。
聪明的你肯定想到了再加一个中间层解决这些适配问题,所以编译器的整个工具链,就有了中间代码生成这一步骤,用来生成无关语言的中间代码IR (Intermediate Representation) ,然后再针对这个中间代码使用源码优化器进行优化,这样就可以对所有语言都进行统一优化了。
中间代码有多种类型,常见的有三地址码,P-代码
三地址码
三地址码贴近机器指令,结构简单,适合编译型语言。
最基本的三地址码是这样的:
ini 代码解读复制代码x = y op z
这个式子代表,把y和z进行op操作的结果赋值给x。
这里的op可以代表算数操作符,也能代表控制流转,内存访问,函数调用等等。
因为这种表示方式,每条指令最多包含三个操作数,而被称为三地址码。
按照刚才的例子
scss 代码解读复制代码array[index] = (index + 4) * (2 + 6)
转换成三地址码后,对应如下
ini 代码解读复制代码t1 = 2 + 6
t2 = index + 4
t3 = t2 * t1
array[index] = t3
可以看到,为了符合三地址码的要求,会通过临时变量t1,t2,t3来表示。
P-代码
P-代码(Pascal Code)最初是给Pascal语言设计的基于栈的中间代码表示结构,可以很好的用于跨平台(没错,jvm的字节码指令也是栈结构的,类似于这种形式)。
把例子转换成P-代码形式。
perl 代码解读复制代码LOD index 将变量 index 的值压入栈顶
LIT 4 将常量 4 压入栈顶
ADD 弹出 index 和 4,计算 index + 4,结果压回栈顶
LIT 2 将常量 2 压入栈顶
LIT 6 将常量 6 压入栈顶
ADD 弹出 2 和 6,计算 2 + 6 = 8,结果压回栈顶
MUL 弹出 (index + 4) 和 8,计算 (index + 4) * 8,结果压回栈顶
LDA array 将数组 array 的基地址压入栈顶
LOD index 再次加载 index 的值到栈顶
ADD 弹出基地址和 index,计算 array[index] 的内存地址
STO 弹出地址和计算结果,将值存入 array[index]
什么叫基于栈?,为什么编译时的代码跟运行时的栈有联系?,基于栈就能跨平台了吗?
看P-代码的每一句,都是在操作栈,栈内部的元素内存地址都可以通过栈指针偏移量计算,这样就大大简化了地址计算的复杂度,减少了对物理地址的依赖。
总结
不管用什么,聪明的你已经发现了,这一步可以明显的把2+6优化成8。
通过中间代码,可以把编译器分为前端和后端。
编译器前端负责产生机器无关的中间代码,后端负责将中间代码转换成目标机器代码。
对于一些可以跨平台的编译器而言,它们可以针对不同的平台使用同一个前端和针对不同机器平台的数个后端。
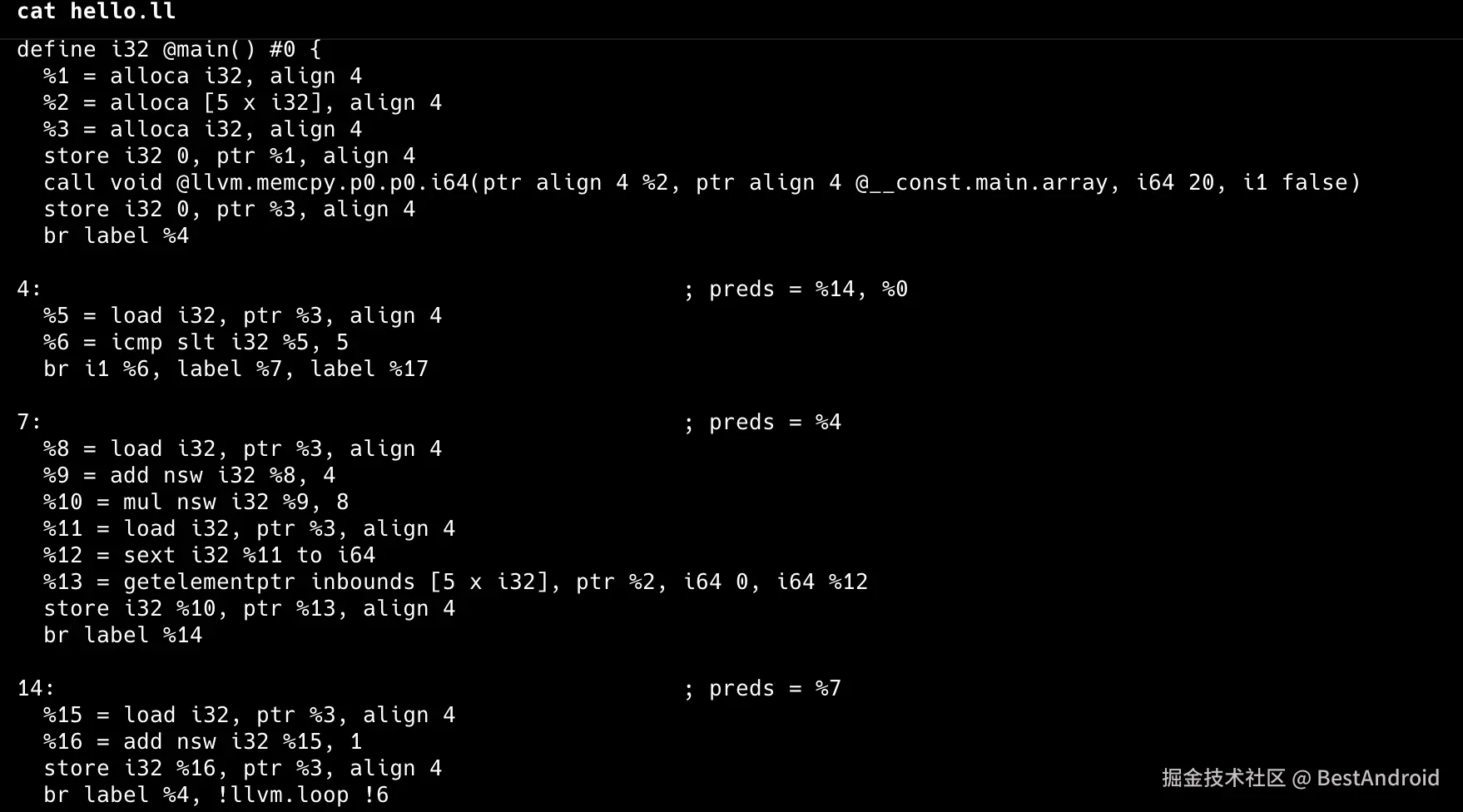
看一下真实的中间代码,先用clang生成没有优化之前的中间代码。
代码解读复制代码clang -S -emit-llvm -O0 -Xclang -disable-O0-optnone hello.c
目标代码生成与优化
从编译器的前端生成中间代码开始,后续操作都属于编译器后端。
编译器后端主要包括,代码生成器,目标代码优化器。
代码生成器是将中间代码转换成目标机器代码,这个过程依赖于目标机器,因为不同的机器有不同的字长,寄存器,数据类型等等。
对于上面的例子来说,如果用x86的汇编语言来表示,假设index为int,array为int型数组
perl 代码解读复制代码movl index, %ecx ; 将内存变量index的值加载到ECX寄存器
addl $4, %ecx ; ECX寄存器值加4(立即数寻址)
mull $8, %ecx ; ECX寄存器值乘以8(注意:实际应使用imul指令)
movl index, %eax ; 将内存变量index的值加载到EAX寄存器
movl %ecx, array(,eax,4) ; 将ECX值存入数组array[EAX]位置
; 寻址计算:array基地址 + EAX*4字节(适用于32位整型数组)
最后通过目标代码优化器进行优化,比如选择合适的寻址方式,使用位移代替乘法等等。
perl 代码解读复制代码movl index, %edx
leal 32(,%edx,8), %eax
movl %eax, array(,%edx,4)”
在这个例子中,把乘法4*8的指令优化成了leal指令。
经过一系列的语法分析,语义分析,源代码优化,代码生成和目标代码优化,编译器终于被编译成了目标代码。但是还有一个关键问题:index和array的地址还没有确定。如果我们使用汇编器编译成真正能够在机器上执行的指令,那么index和array的地址应该从哪里得到呢??
缺少的这一部分就需要靠链接器来完成。
链接器年龄比编译器长

在最开始的时期,编程都是直接在纸带上打孔的,穿孔代表0,没有穿孔代表1。
假如有这种程序
css 代码解读复制代码计算 a
计算 b
跳转到 第五条指令
4
5
如果突然要在a和b的计算之间插入c的计算,那就会导致跳转到 第五条指令这段代码出现Bug!。
因为程序的修改,导致整个纸条上的地址访问出现错乱,我们把重新计算这个第五条指令的位置,称为重定位(Relocation)。这还仅仅是一条纸带,如果纸带越来越大,程序越来越庞大,改一次代码就得疯。
为了解决这个问题,人们发明了汇编语言,通过jmp foo代表跳转到foo处,我们把刚才的代码改一下
css 代码解读复制代码计算 a
计算 b
jmp foo
4
5
这样子,不管在foo之前插入多少个语句都不怕,因为我们可以使用汇编器去统一修改所有foo的地址,达到正确的引用。这个地址可能是一段函数的开始地址,也可能是一个变量的起始地址。
有了汇编之后,生产力大大提高,但是软件也越来越庞大,人们开始考虑把代码按照功能或性质来划分成不同的模块来解耦。
比如C语言,可以把变量,函数都放到一个.c文件中,java可以把不同的变量和文件放到一个.java文件中。
随着程序越来越大,肯定不只有一个文件。
针对一个程序内部的多个文件,如何把他们组合起来形成一个单一程序呢?不同文件之间运行时如何通信?A文件中怎么使用B文件的函数和变量?
这些问题都需要链接器解答。
模块拼装 静态链接
当我们把每个单独的文件通过编译完之后,需要按照一定的要求把它们组装起来,这个组装不同文件的过程就是链接(Linking)。
链接的主要内容就是把各个文件之间相互引用的部分都处理好。比如上文提到的A文件引用B文件的函数,变量等。
从本质上来说链接器做的工作,跟程序员人工手动调整地址是一样的,就是把一些指令对其他符号地址的引用修正。但是现代高级语言有很多特性和功能,会让编译器和链接器变的越来越复杂,所以要单独搞一个工具来完成这一步步操作。
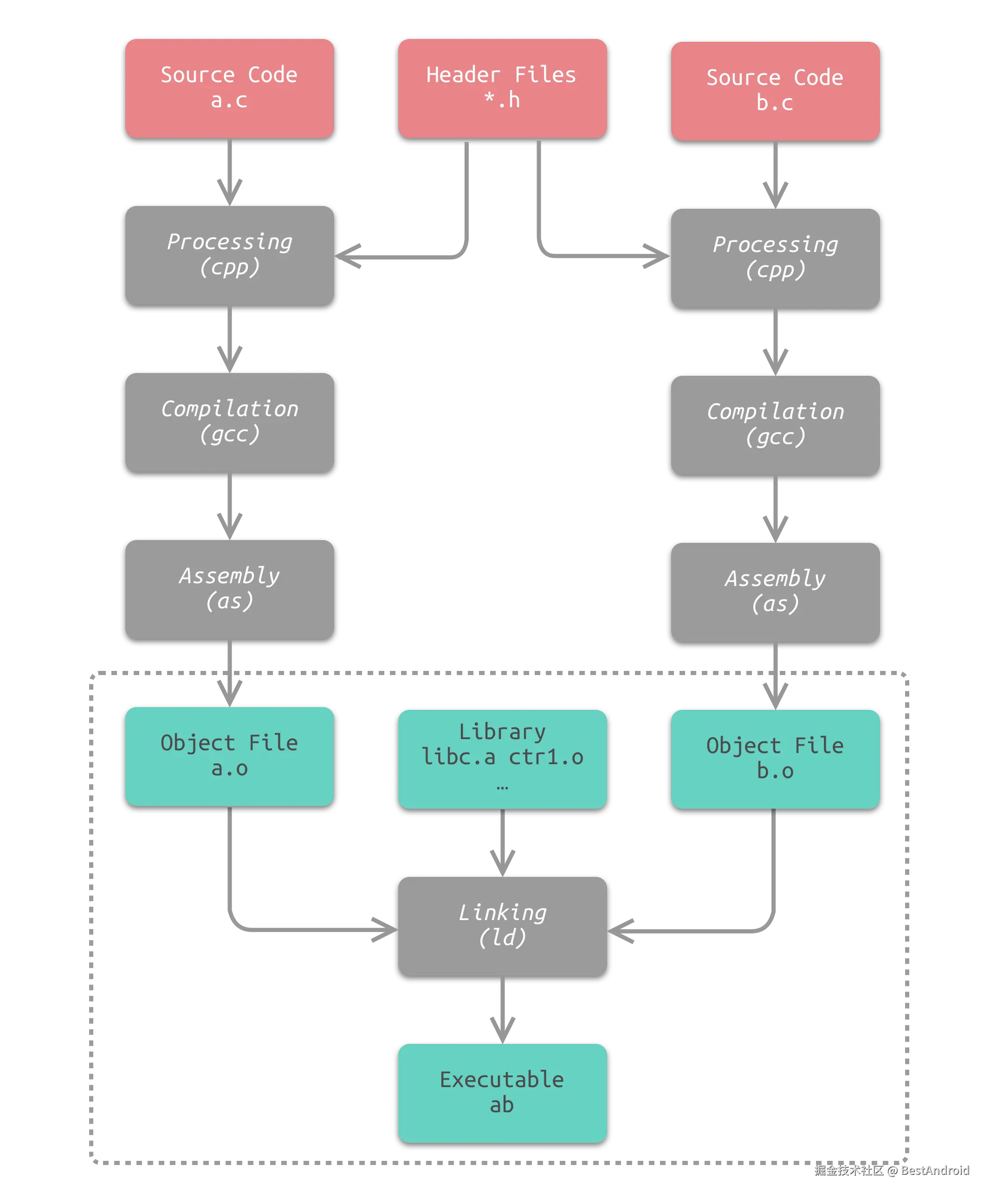
链接的主要有两步:地址和空间分配,符号解析和重定位,看最后的虚线框。
地址和空间分配 是指,把多个目标文件(.o文件)合并成一个可执行文件时,怎么安排这些目标文件在内存中的顺序(也就是布局),通常会合并目标文件中的同类段(比如代码段,数据段),然后再给段的起始位置分配一个地址,最终确认每一个段的位置。
符号解析和重定位 是指,解决符号引用关系,让互相调用的目标文件内部的变量地址变成实际的地址(就是把最开始说的汇编器foo的地址修改对)。
其中符号引用就是检查遍历的过程,是为后续的重定位修改去服务的。
在图上的虚线框里面除了目标文件,中还有一些.o的文件,是运行时库,一些常用库的集合。
本章小结
本章讲述了从源代码到最终可执行文件的四个步骤:预编译,编译,汇编,链接,分析了他们之间的关系和作用。对程序的编译,链接有了初步的理解。
后续我打算写个简单的编译器,来加深一下理解,大家有好的教程或者学习资料可以互相交流~。
参考
chuquan.me/2018/06/03/… pandolia.net/tinyc/ pku-minic.github.io/online-doc/… arcsysu.github.io/YatCC/#/
评论记录:
回复评论: