

本文使用的是 Ubuntu20.04 的 MySQL5.7 版本,对于该系统对于的该版本的MySQL,可以借鉴这篇博客,一步到位!!:【MySQL】Ubuntu 20.04 下安装 MySQL 5.7_ubuntu20.04安装mysql5.7-CSDN博客
1、什么是数据库
1.1 什么是数据库
存储数据用文件就可以了,为什么还要弄个数据库?
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理(重点)
- 文件不利于存储海量数据
- 文件在程序中控制不方便(重点)
数据库存储介质:
- 磁盘
- 内存
为了解决上述问题,专家们设计出更加利于管理数据的东西——数据库,它能更有效的管理数据。数据库的水平是衡量一个程序员水平的重要指标。
1.2 重点理解:数据库是一种数据管理和处理系统
当我们登录 MySQL 后,再新打开一个终端可以使用 ps 命令查看 MySQL 相关运行进程:

从输出结果中,我们不仅看到了 mysql 进程,还看到了 mysqld 进程。MySQL 不是一个单一软件吗,为什么会有两个?
我们常把“MySQL 数据库”称为“MySQL”,并且启动时使用的是程序也是 mysql,所以我们可能下意识地认为“MySQL = mysql”。实际上,这种认知是不正确的。
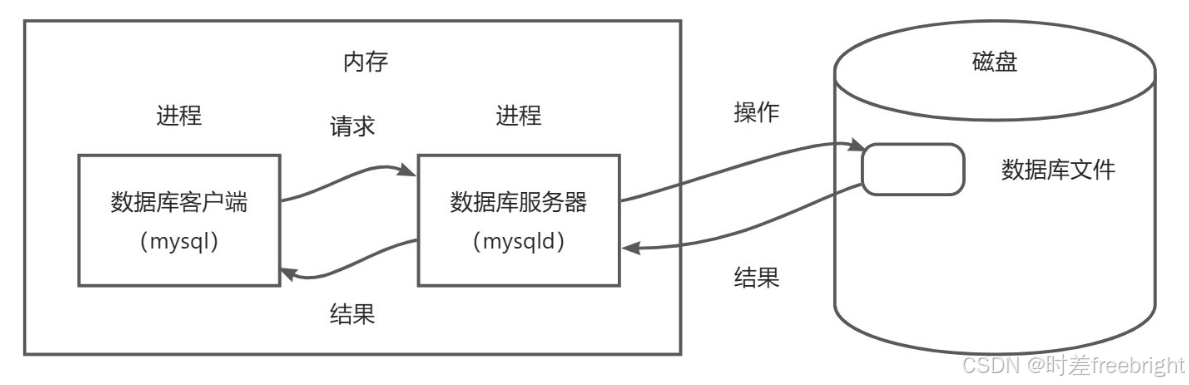
从宏观的整体角度来看,MySQL 或者说数据库是一套专注于解决数据的高效存储、检索和管理问题的系统。
以 MySQL 为例,数据库系统通常包含以下核心部分:
-
客户端程序 (Client)
客户端是用户与数据库交互的工具。在 MySQL 中,客户端程序 mysql 就是一个典型代表。用户通过它向数据库服务端发送 SQL 语句,从而完成对数据的操作,如查询、插入和删除等。 -
服务端程序 (Server)
服务端程序是数据库的核心,负责实际的数据管理任务。在 MySQL 中,服务端程序 mysqld 作为守护进程运行,负责处理客户端请求、执行 SQL 语句、维护数据的一致性和安全性等。 -
数据库文件 (Files)
数据最终以文件的形式存储在硬盘或内存上,具体存储的特定结构组织的数据。MySQL 的服务端将用户的数据组织成特定格式的文件(如 .ibd 文件、事务日志文件等),以便高效地存取和管理。
结论:数据库是一个协作系统,客户端和服务端共同完成数据的交互,而数据库文件则作为数据的持久化载体。
简单来说,MySQL客户端程序 mysql 就是用于发送数据处理和操作请求,MySQL服务端程序 mysqld 则接收解析客户端的请求,数据库存储文件则是用于特定结构化的存储数据(便于服务端及时存取和管理数据)。例如,客户端发送一个查找数据库中某人的身份信息的请求,服务端则接收该请求,并借助数据库存储文件取出相关的信息,然后将信息发送给客户端
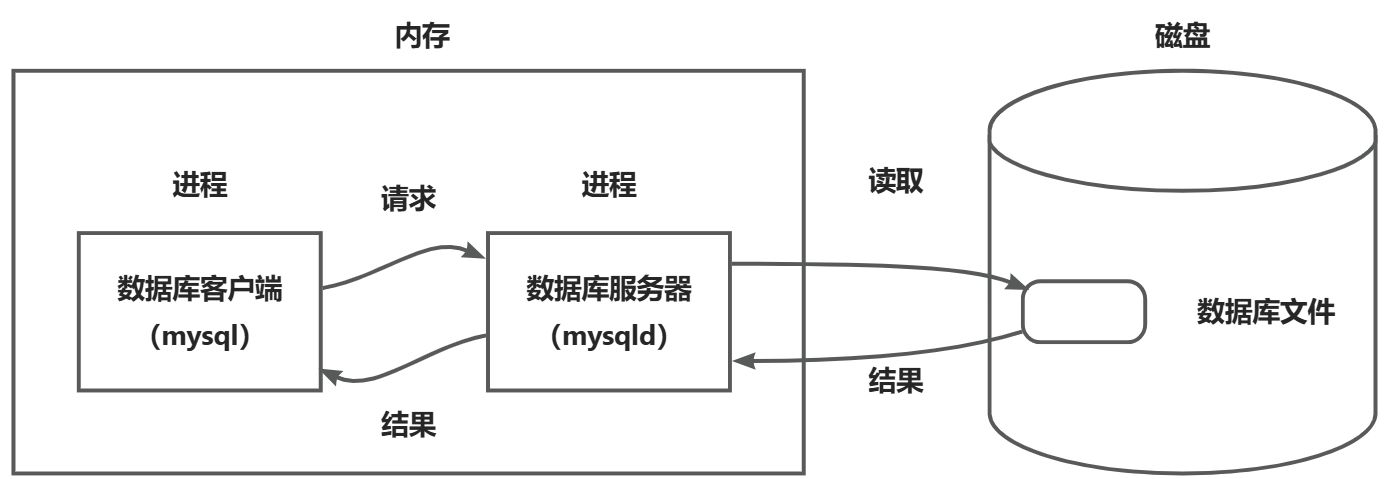
数据库客户端和数据库服务端有可能会跨主机进行网络通信,所以有时候我们也会把数据库系统称为网络服务,可以说,MySQL的本质,是基于C(mysql) S(mysqld)模式的一种网络服务
2、常见客户端登录选项
| 选项 | 含义 |
|---|---|
-u 或 --user | 指定要登录的用户名,例如 -u root |
-p 或 --password | 用于提示输入密码。如果后面直接跟着密码,会在命令行中显示,但通常推荐不直接使用,以保护安全,例如 -p123123 |
-h 或 --host | 指定要连接的 MySQL 服务器的主机名或 IP 地址,例如 -h 127.0.0.1 |
-P 或 --port | 指定 MySQL 服务器的端口号,默认是 3306 |
-protocol | 指定连接协议,可以是 TCP、UNIX 或 MEMORY,默认为 TCP |
-default-character-set | 设置客户端的默认字符集,例如 --default-character-set=utf8 或 --default-character-set=utf8mb4 |
-D 或 --database | 在登录时指定要使用的数据库,例如 -D DatabaseName |
-ssl-mode | 指定 SSL 连接的模式,例如 DISABLED(禁用)、PREFERRED(首选)等 |
例如:在本地登录MySQL客户端,指定要连接的服务器主机IP地址与端口号,指定登录数据库的用户名…
mysql -h 127.0.0.1 -P 3306 -u root -P
- 1
3、数据库的简单使用:快速认识数据库
3.1 目标
- 建立一个数据库 - 查数据库、建库的 SQL 语句
- 建立一张表结构 - 查表、建表的 SQL 语句
- 插入一些数据 - 插入、查询的 SQL 语句
- 观察一下以上操作在 Linux 文件中如何表现以加深对于 MySQL 数据库的了解
3.2 准备工作
我们需要启动两个终端窗口,一个用于输入并执行SQL语句,一个用于在系统层面观察数据库的变化(如目录或文件的增删)
启动终端 1
- 目的:输入并执行SQL语句
在 mysql> 提示符下我们输入的命令叫做 SQL 指令或者 SQL 语句。(注意:SQL 语句一定要以 ; 结束,否则不被视为一句完整的 SQL 语句)
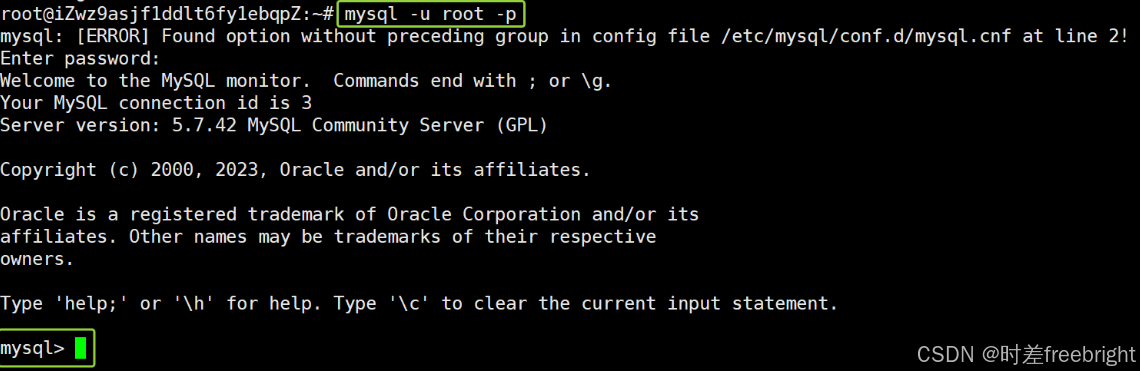
然后在终端1输入 show databases; 能够查看到当前数据库下已经存在的所有数据库。
启动终端 2
-
目的:观察数据库在Linux中的存在形式。
-
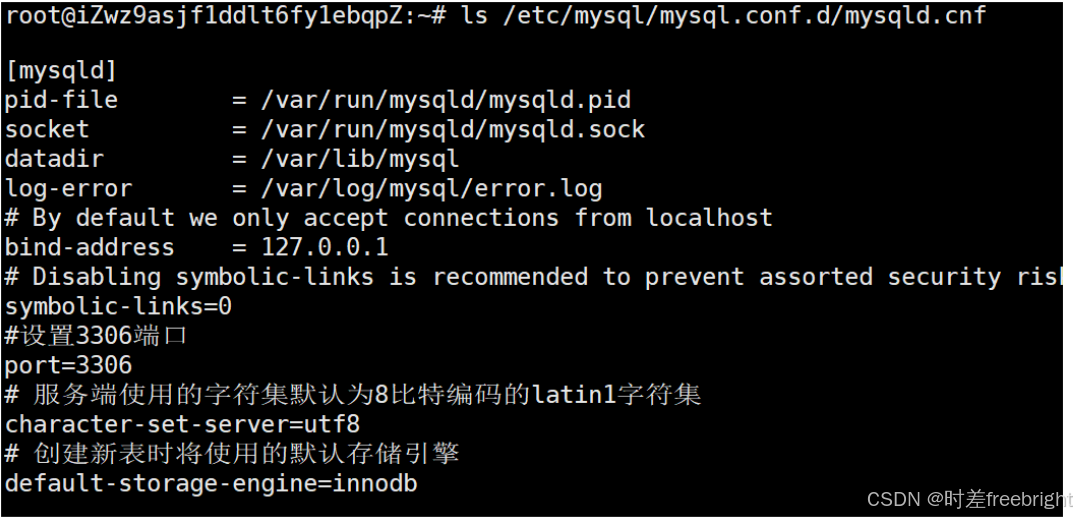
配置文件位置:
- MySQL相关的配置文件一般位于
/etc/mysql目录下。 - 由于发行版不同配置文件的结构稍有不同,在Ubuntu-20.04中,MySQL服务端的配置文件是
/etc/mysql/mysql.conf.d/mysqld.cnf。 - 在配置文件中,存在有许多条数据库配置信息,如默认端口号 3306等等
- MySQL相关的配置文件一般位于
-
数据库文件存放目录
-
目录位置:配置文件中包含
datadir = /var/lib/mysql这一项,是 MySQL 网络服务的数据库文件存放位置。在数据库命令行中使用show databases;语句查到的各个数据库就是存放在这个目录中。 -
访问方法:普通用户无法直接使用
cd命令进入/var/lib/mysql目录,因为需要超级用户权限。我们需要在终端 2 的Bash中输入su -并输入密码切换成超级用户。切换为超级用户后,进入/var/lib/mysql目录,并使用ls命令查看该目录下的内容。
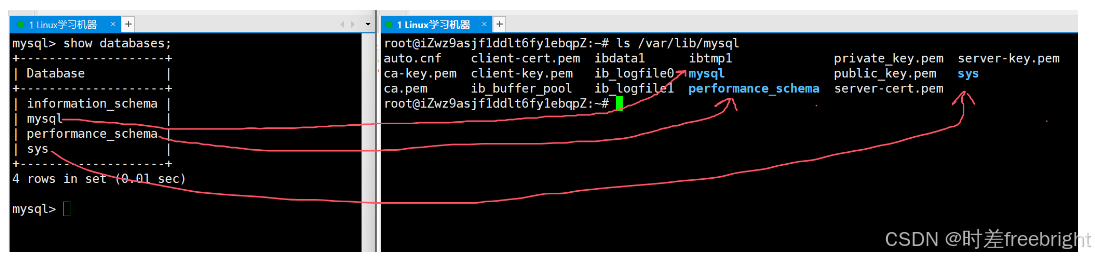
对比show databases;语句的结果和ls /var/lib/mysql命令的结果我们就可以发现,MySQL中的数据库在Linux文件系统中以目录的形式存在。
-
3.3 建库
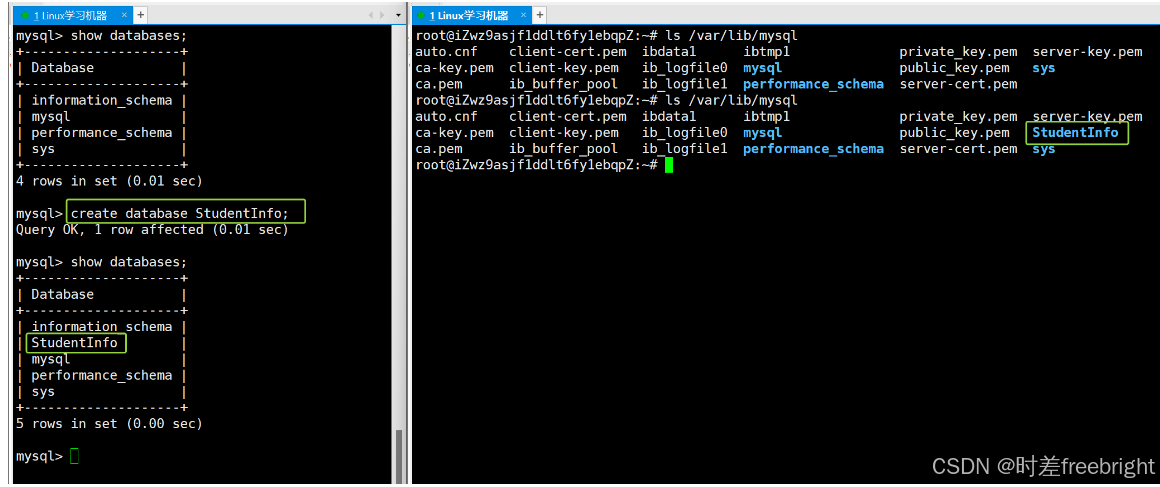
在终端1,输入SQL语句 create database StudentInfo;创建一个名字为 StudentInfo 的新数据库。
再输入show databases;能够看到新创建好的 StudentInfo 数据库出现在数据库列表上。
在终端2,输入命令 ls /var/lib/mysql,可以发现该目录下多了一个叫做 StudentInfo 的目录,由此可以证明在 MySQL中建立数据库的本质就是在Linux下新建一个目录。
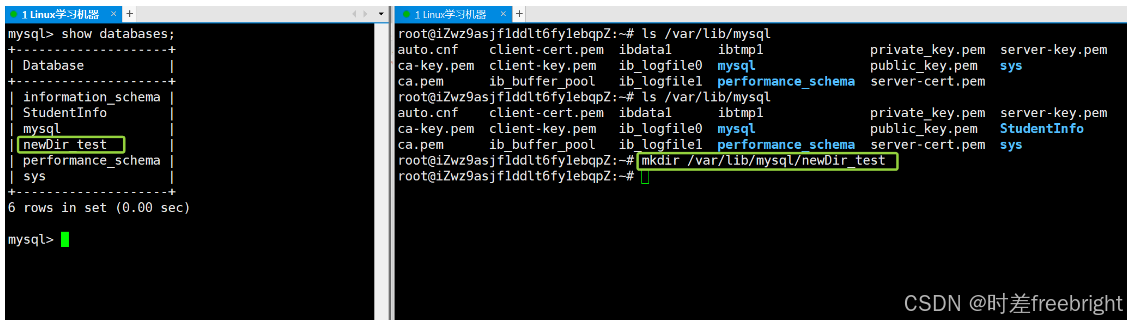
反向证明
我们在 /var/lib/mysql 目录下创建一个叫做 newDir_test 的目录,然后可以发现在 MySQL客户端中能够找到一个叫做 newDir_test 的数据库,这不就能反向说明数据库是一个目录吗!!
3.4 建表
1、选择数据库(切换数据库):
- 在MySQL中,表结构是在特定的数据库中建立的。(类似于在目录中创建一个文件)
- 在MySQL客户端上输入SQL语句
use 数据库名;用于选择一个数据库。(类比于文件创建,创建一个文件之前需要选择一个特定的目录) - 例如,如果要在
StudentInfo数据库中创建表,需要先输入 SQL 语句use StudentInfo;。
2、执行SQL语句:
-
将以下SQL语句复制并粘贴到MySQL客户端中:
use StudentInfo;- 1
-
如果没有输出结果,可以再按一下回车键确认命令已执行。
3、创建一张表
create table student(
name varchar(32),
age int,
gender varchar(32)
);
- 1
- 2
- 3
- 4
- 5
在终端 2 中,通过 ls 命令,可以观察 StudentInfo 目录的变化
在建表之前:可以发现 StudentInfo 目录下只有一个 db.opt 这个配置文件
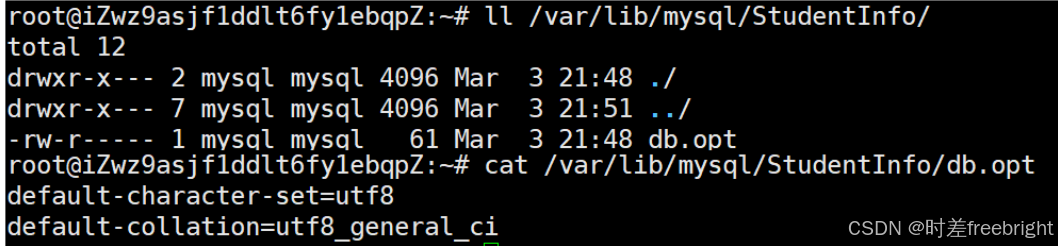
建表之后,可以发现 StudentInfo 目录下多了student.frm和student.ibd这两个文件
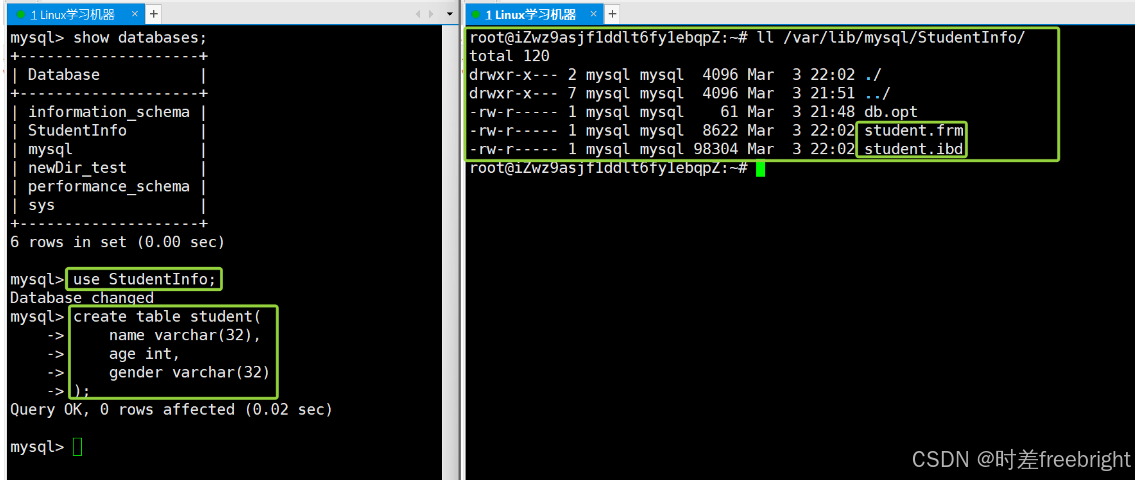
这两个文件具体什么作用现在没法讲,但是能够确定的是,在MySQL中的某个数据库里建立表结构的操作实际上就是在这个数据库对应的Linux目录下建立一批特定结构的文件。
3.5 插入数据
对 StudentInfo 数据库中的 student 表进行数据的插入。
通过 insert 语句插入一些具体数据信息,通过 select 查询指定表结构
可以看到,我们的信息插入后,自动整理成了有着清晰的行列结构的表,这不就是一种对数据的逻辑存储吗!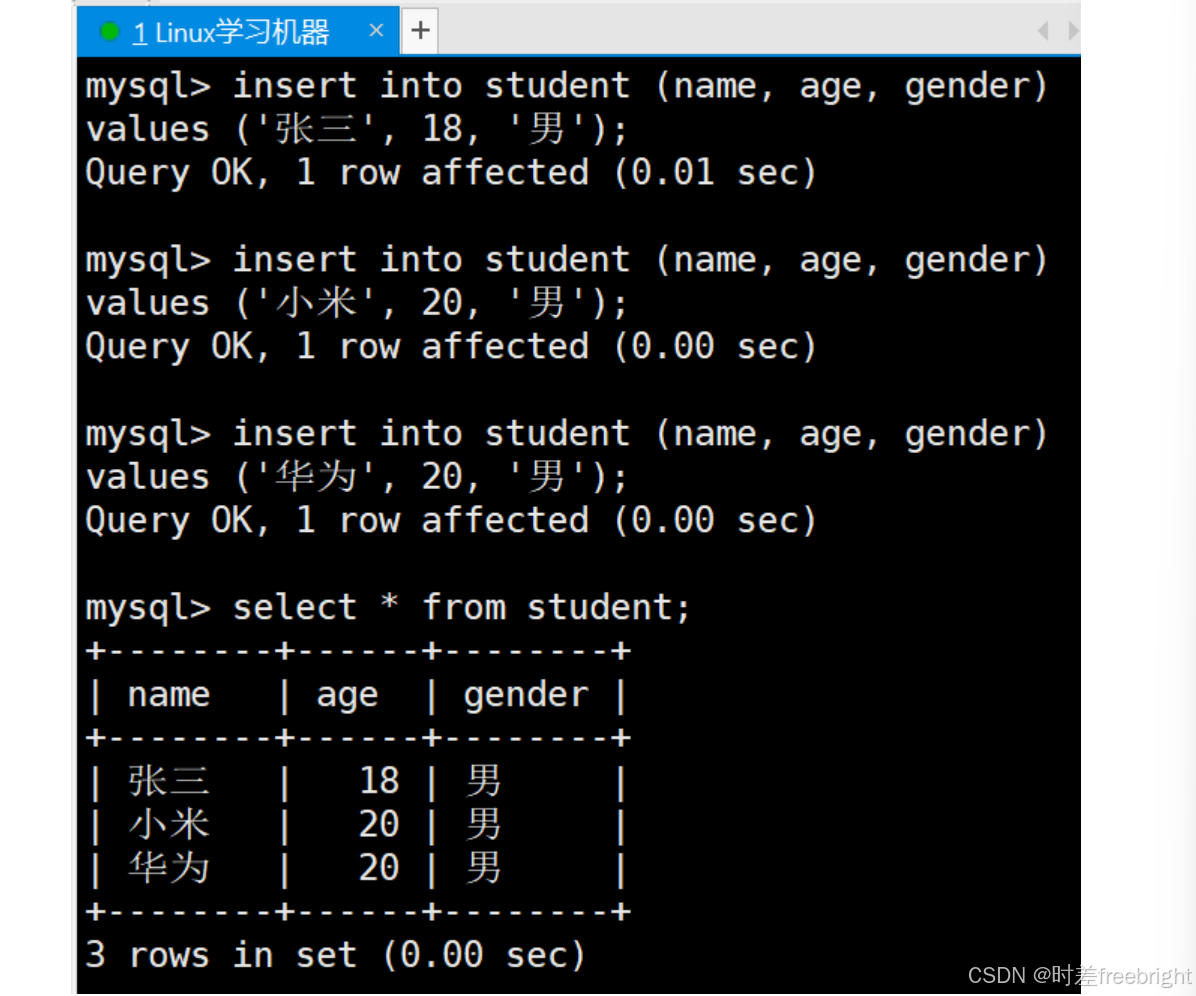
3.6 总结
在对MySQL数据库的建库、建表以及插入数据等操作有了一定了解后,我们可以进一步探讨一个关键问题:为什么数据库能够为程序员提供高效的数据存储、检索和查询能力?
首先,我们需要明确一个问题:我们前面在MySQL客户端发送的建库、建表以及插入数据SQL语句,背后的具体操作究竟是由谁来完成的?答案是数据库服务(也就是数据库服务端程序)。尽管数据库文件具有特殊的结构,但它们本质上仍然是文件。如果没有数据库服务的存在,程序员就需要自己编写代码来实现文件的遍历、读取以及写入操作,这无疑会大大增加开发的复杂度。
幸运的是,许多专家已经为我们设计并实现了一整套成熟的数据库服务。作为使用者,我们只需将业务需求转化为SQL语句,并通过数据库客户端提交这些语句即可。数据库客户端会负责将SQL语句传递给数据库服务,而数据库服务则承担起执行文件读写操作的任务。至于数据的具体管理方式,例如索引的创建、事务的控制以及并发的处理等,我们都无需过多关心,因为这些复杂的任务完全由数据库服务自行处理。
正是由于数据库服务的存在,程序员得以从繁琐的底层细节中解脱出来,专注于更高层次的应用逻辑开发。这也是为什么使用数据库能够显著提升数据存储、检索和查询效率的原因所在。通过将复杂的文件操作封装为简洁的SQL接口,数据库不仅简化了开发流程,还极大地提高了系统的性能与可靠性。
4、主流数据库
关系型数据库
| 数据库 | 特点 |
|---|---|
| SQL Server | 微软开发,适合中大型项目,尤其受.NET程序员欢迎。 |
| Oracle | 甲骨文公司开发,适合大型项目和复杂的业务逻辑,但在并发性能上一般不如MySQL。 |
| MySQL | 甲骨文公司开发,世界上最受欢迎的数据库,适合电商、SNS和论坛,处理简单SQL效果好。 |
| PostgreSQL | 加州大学伯克利分校开发,支持私用、商用和学术研究,免费使用、修改和分发。 |
| SQLite | N/A。轻量级ACID关系型数据库,适合嵌入式设备,资源占用极低。 |
| H2 | N/A,用Java开发的嵌入式数据库,可以直接嵌入到应用项目中。 |
非关系型数据库
| 数据库 | 特点 |
|---|---|
| MongoDB | 文档数据库,灵活的模式,适合处理大规模数据,支持水平扩展。 |
| Cassandra | 分布式列存储,适合高写入负载和高可用性,支持多数据中心部署。 |
| Redis | 内存键值存储,速度极快,支持丰富的数据结构,常用于缓存和实时分析。 |
| Couchbase | 文档存储,结合了键值和文档数据库的特点,支持强一致性和灵活查询。 |
| Neo4j | 图数据库,适合处理复杂关系的数据,提供高效的图查询语言。 |
| DynamoDB | 亚马逊提供的完全托管的键值和文档数据库,具备高可用性和可扩展性。 |
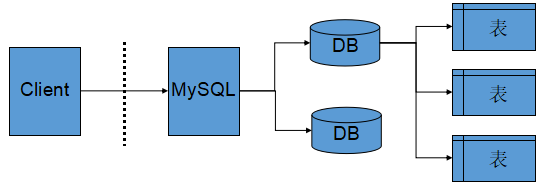
5、服务器、数据库、表的关系
- 所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
- 数据库服务器、数据库和表的关系如下:
6、MySQL架构
这部分的关键在于理解 mysqld 的构成。
MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和 Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。
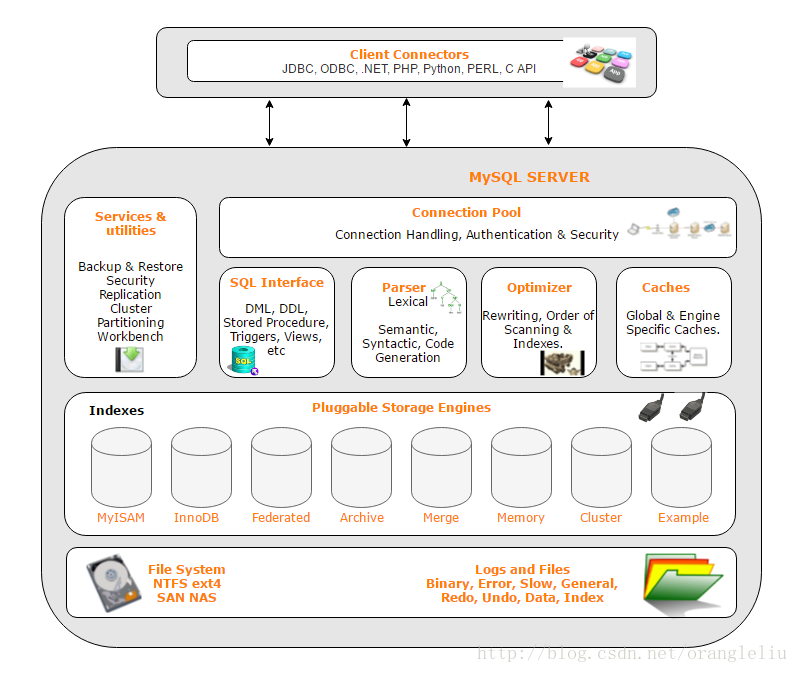
我们可以将MySQL的架构大致分为三层来理解:安全管理层、词法解析层和存储引擎层。这样的分层设计不仅清晰地划分了功能模块,还体现了MySQL的高度灵活性和可扩展性。
-
第一层:安全管理层
这一层是MySQL架构的基础,负责安全管理、用户认证以及连接池管理。当用户通过SQL语句访问某个数据时,本层会严格检查用户是否具备相应的权限,从而确保数据库的安全性。此外,这一层还会处理诸如连接复用、身份验证等任务,减少系统开销并提升性能。 -
第二层:词法解析层
在这一层,用户的SQL语句会被进行词法分析、语法解析,并生成执行计划。优化器是这一层的核心组件,它会对查询进行调优,选择最佳的执行路径以提高查询效率。经过处理后,SQL语句会被交给第三层的存储引擎进行进一步解释和执行。值得注意的是,这一层的缓存机制(如查询缓存)也能够显著提升重复查询的性能。 -
第三层:存储引擎层
存储引擎层是MySQL架构中最灵活的部分,类似于驱动程序,负责直接与底层文件系统交互,访问具体的文件和数据。MySQL支持多种存储引擎,每种引擎都有其特定的用途和优势。例如:- MyISAM:适合于大段文本的插入操作,适用于读多写少的场景。它的简单性和高效性使其在某些特定场景中依然有很高的价值。
- InnoDB:擅长快速索引和事务处理,适用于需要高并发和数据一致性的场景。它是目前大多数MySQL部署中的默认存储引擎,尤其是在涉及复杂事务的应用中表现优异。
用户可以根据实际需求选择合适的存储引擎(在图中用两个插头图标表示这些存储引擎类似于“热插拔”设备,可以灵活切换)。上层用户可以通过配置指定使用哪种存储引擎,以满足不同数据存储和处理的需求。
7、SQL语句的分类
SQL语句通常可以划分为以下五类:
1、数据定义语言(DDL, Data Definition Language):
- 用于定义和修改数据库结构,如创建、修改和删除表及其他数据库对象。
- 代表性语句:
CREATE、ALTER、DROP。 - 示例:
CREATE TABLE users (id INT PRIMARY KEY, name VARCHAR(50), age INT);(创建表)ALTER TABLE users ADD email VARCHAR(100);(修改表结构)DROP TABLE users;(删除表)
2、数据操作语言(DML, Data Manipulation Language):
-
用于对数据进行插入、更新和删除操作。
-
代表性语句:
INSERT、UPDATE、DELETE。 -
示例:
INSERT INTO users (name, age) VALUES ('Alice', 30);(插入数据)UPDATE users SET age = 31 WHERE name = 'Alice';(更新数据)DELETE FROM users WHERE name = 'Alice';(删除数据)
3、数据查询语言(DQL, Data Query Language):
- DML下的一个分支。
- 主要用于从数据库中检索数据。
- 代表性语句:
SELECT。 - 示例:
SELECT * FROM users;(查询用户表中的所有数据)
4、数据控制语言(DCL, Data Control Language):
- 用于控制对数据的访问权限和安全性。
- 代表性语句:
GRANT、REVOKE。 - 示例:
GRANT SELECT ON users TO user1;(授予权限)REVOKE SELECT ON users FROM user1;(撤销权限)
5、事务控制语言(TCL, Transaction Control Language):
- 用于管理数据库事务,确保数据的一致性和完整性。
- 代表性语句:
COMMIT、ROLLBACK、SAVEPOINT。 - 示例:
COMMIT;(提交事务)ROLLBACK;(回滚事务)SAVEPOINT savepoint_name;(设置保存点)
这几个SQL的分类其实非常容易理解。我们可以用学习数据结构中的链表来类比:
- 在建立一个链表并定义其基本结构时,我们并没有向其中填充实际内容,这一步骤对应的就是DDL(Data Definition Language,数据定义语言),主要用于定义或修改数据库对象(如表、索引等)的结构。例如,创建表、修改表结构或删除表都属于DDL的范畴。
- 接下来,根据实际需求,我们可能会对链表中的节点进行插入、删除或更新操作,这些操作与**DML(Data Manipulation Language,数据操纵语言)**相对应。DML专注于对表中数据的具体操作,比如插入数据(
INSERT)、更新数据(UPDATE)以及删除数据(DELETE)。 - 而**DCL(Data Control Language,数据控制语言)**则有所不同,它更偏向于权限管理和事务控制。例如,通过
GRANT和REVOKE语句管理用户对数据库的访问权限,或者使用COMMIT和ROLLBACK来控制事务的提交或回滚。
8、MySQL存储引擎
存储引擎:数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。MySQL的核心就是插件式存储引擎,支持多种存储引擎。
举个比较浅显的例子,你可以把存储引擎看做成一个类,不同的存储引擎就是不同的类,每个类的内部都定制有属于自己的一套存储和管理数据的方案。
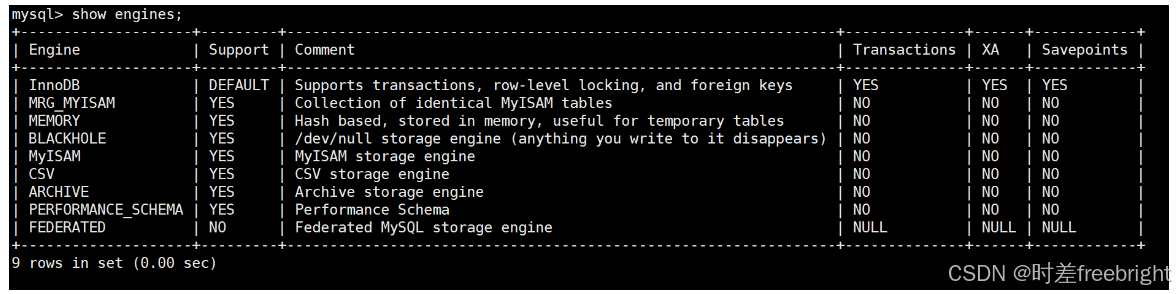
查看存储引擎的SQL语句
show engines;
- 1
执行示例
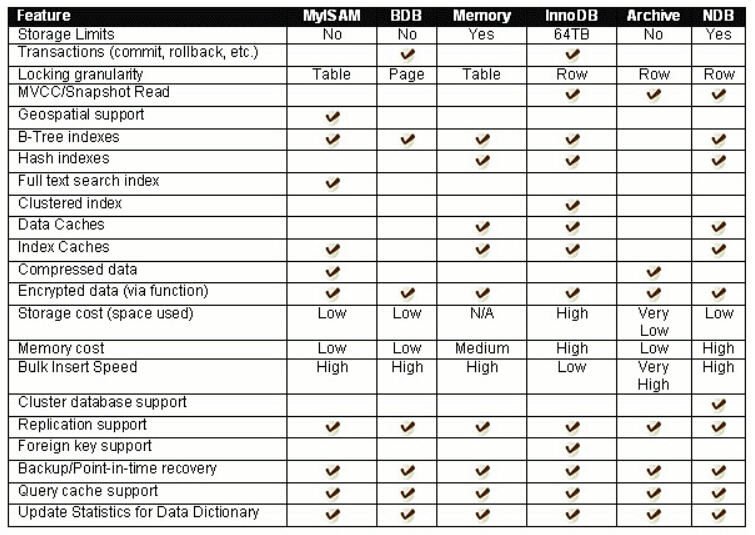
存储引擎的对比图
注:本文借鉴此篇博客 https://blog.csdn.net/ljh1257/article/details/144963440, 在此基础上加入我的一些想法和见解,以及对一些语言表达和逻辑进行优化
评论记录:
回复评论: