
前言
深度学习就是把输入转换成一个高维的向量,之后利用这个向量去完成分类、回归等任务。
深度学习特征工程知识图谱
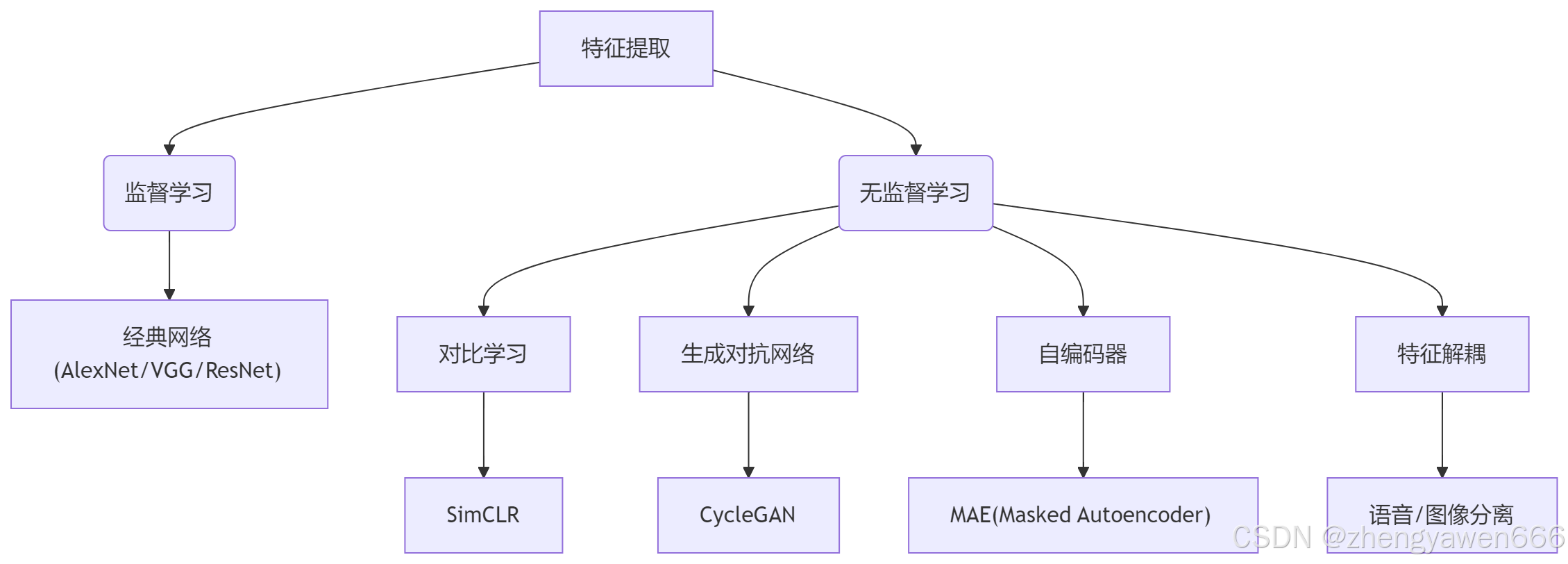
1. 特征提取的本质
核心目标:将原始数据→高维语义特征向量
监督驱动:标签决定特征提取方向
典型架构:
AlexNet:首个深度CNN突破
VGG:统一卷积核设计
ResNet:残差学习框架
2. 无监督学习三大范式
| 方法 | 原理 | 典型应用 |
|---|---|---|
| 对比学习 | 拉近正样本距离,推远负样本 | SimCLR、MoCo |
| 生成对抗网络 | 生成器-判别器博弈,生成逼真数据 | 图像生成、风格迁移 |
| 自编码器 | 重构输入数据,学习有效特征表示 | MAE、VAE |
这个表格总结了三种主要的自监督学习方法及其关键特征和应用场景。每种方法都利用未标记的数据来训练模型学习有用的特征表示,这些特征表示可以用于多种下游任务,如分类、聚类和生成任务。
-
对比学习:通过正样本对和负样本对的设计,让模型学习区分相似和不相似的样本,从而提取有用的特征。
-
生成对抗网络(GAN):通过生成器和判别器的对抗训练,模型学习生成新的数据,同时学习数据的特征表示。
-
自编码器:通过重构输入数据,模型学习到数据的有效特征表示,这在特征提取和降维中特别有用。
3. 关键技术创新
CycleGAN:跨域转换的双向一致性约束
MAE:掩码自编码实现高效预训练
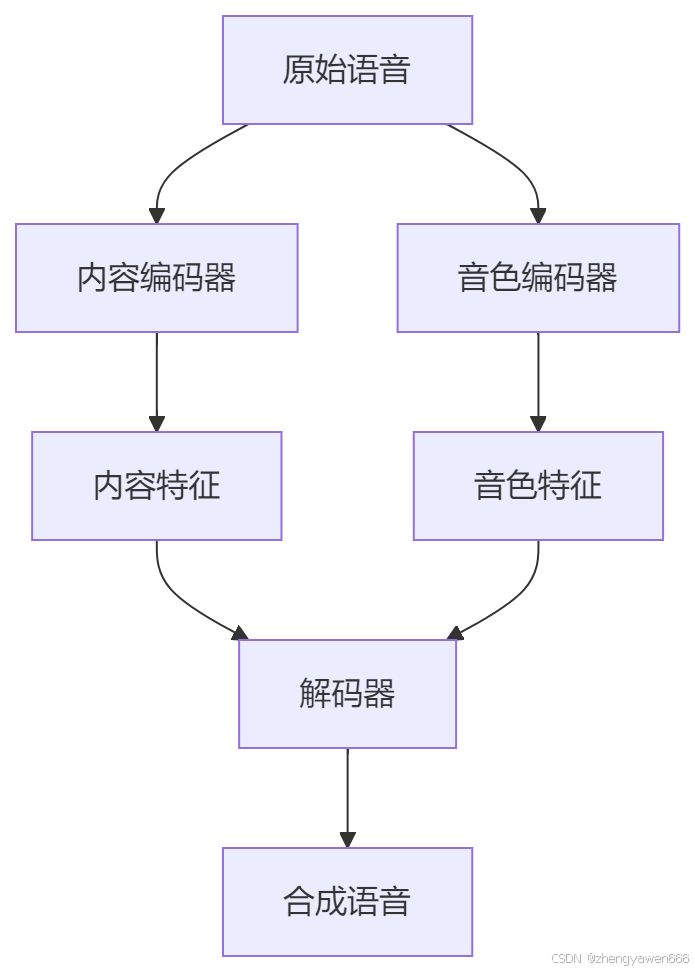
特征解耦:分离内容与风格特征
语音:内容vs说话人特征
图像:物体vs纹理特征
4. 自监督学习优势
数据效率:利用海量未标注数据
迁移能力:预训练模型适配下游任务
典型流程:
无标注预训练 → 少量标注微调 → 目标任务
无监督学习
对比学习
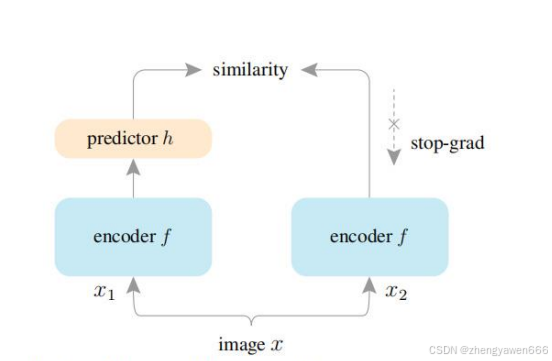
SimSiam(Simple Framework for Contrastive Learning of Visual Representations)是一种用于无监督学习的对比学习方法,旨在通过对比学习框架学习图像的特征表示。SimSiam 的核心思想是通过对比正样本对(即同一个图像的不同增强版本)和负样本(即不同图像的增强版本)来学习特征表示,从而使得模型能够捕捉到图像的内在结构。
SimSiam 的核心思想
SimSiam 的目标是学习图像的特征表示,使得同一个图像的不同增强版本在特征空间中更接近,而不同图像的增强版本在特征空间中更远离。这种方法不需要标签信息,因此属于无监督学习。
SimSiam 的关键组件
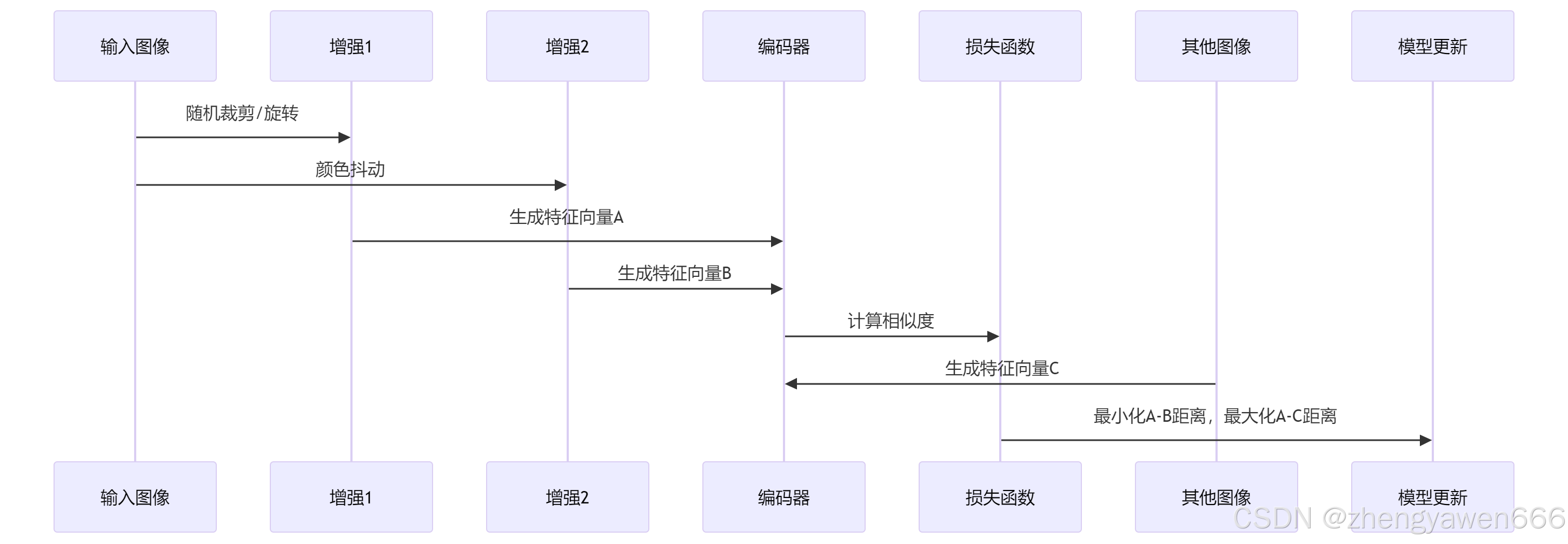
1. 数据增强
SimSiam 使用数据增强技术生成正样本对。具体来说,对于每个输入图像,SimSiam 会生成两个不同的增强版本,这两个版本被称为正样本对。常见的数据增强技术包括随机裁剪、颜色失真、高斯模糊等。
2. 对比学习框架
SimSiam 通过对比学习框架来训练模型。具体来说,模型的目标是最小化正样本对之间的距离,同时最大化负样本之间的距离。这可以通过对比损失函数(如 InfoNCE 损失)来实现。
3. 无监督学习
SimSiam 是一种无监督学习方法,不需要标签信息。它通过对比学习框架学习图像的特征表示,使得模型能够捕捉到图像的内在结构。
SimSiam 的训练过程
1. 数据准备
对于每个输入图像,生成两个不同的增强版本,形成正样本对。
2. 特征提取
使用一个编码器(通常是一个卷积神经网络,如 ResNet)提取输入图像的特征表示。
3. 对比学习
通过对比损失函数(如 InfoNCE 损失)来训练模型。具体来说:
-
正样本对:同一个图像的不同增强版本,目标是最小化它们之间的距离。
-
负样本:不同图像的增强版本,目标是最大化它们之间的距离。
4. 无监督训练
SimSiam 不需要标签信息,因此属于无监督学习。通过对比学习框架,模型可以学习到图像的特征表示,使得同一个图像的不同增强版本在特征空间中更接近,而不同图像的增强版本在特征空间中更远离。
SimSiam 的优势
-
简单高效:SimSiam 的框架相对简单,易于实现和训练。
-
无监督学习:不需要标签信息,适用于大规模无标签数据集。
-
特征表示质量高:通过对比学习,SimSiam 可以学习到高质量的特征表示,适用于多种下游任务(如分类、聚类等)。
SimSiam 的应用场景
SimSiam 主要用于无监督学习中的特征提取。通过学习图像的特征表示,SimSiam 可以应用于以下场景:
-
图像分类:通过微调预训练的模型,可以提高分类任务的性能。
-
聚类:学习到的特征表示可以用于聚类任务,将相似的图像分到同一类别。
-
迁移学习:学习到的特征表示可以迁移到其他任务,提高模型的泛化能力。
总结
SimSiam 是一种无监督学习的对比学习方法,通过对比正样本对和负样本来学习图像的特征表示。SimSiam 的核心思想是通过数据增强生成正样本对,通过对比学习框架训练模型,使得同一个图像的不同增强版本在特征空间中更接近,而不同图像的增强版本在特征空间中更远离。SimSiam 的优势在于其简单高效,适用于大规模无标签数据集,可以学习到高质量的特征表示,适用于多种下游任务。
生成对抗网络
GAN 总体逻辑
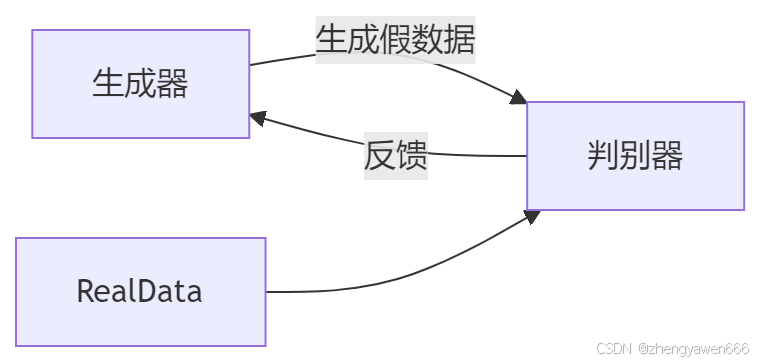
生成对抗网络(GAN,Generative Adversarial Networks)是一种深度学习模型,它包含两个主要部分:生成器(Generator)和判别器(Discriminator)。GAN 的目的是通过生成器生成逼真的数据,同时判别器尝试区分生成的数据和真实数据。两者在训练过程中相互竞争,从而提高生成数据的质量。
GAN 的工作原理
-
生成器:接收随机噪声作为输入,尝试生成与真实数据分布相似的数据。
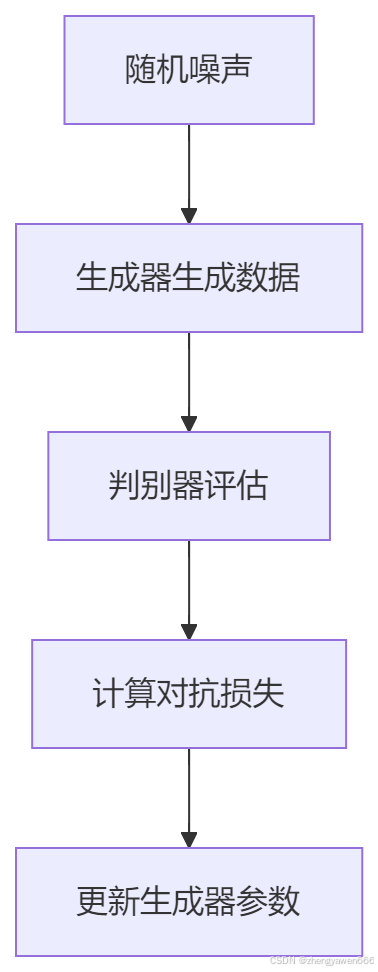
-
判别器:接收生成的数据和真实数据,尝试区分两者。
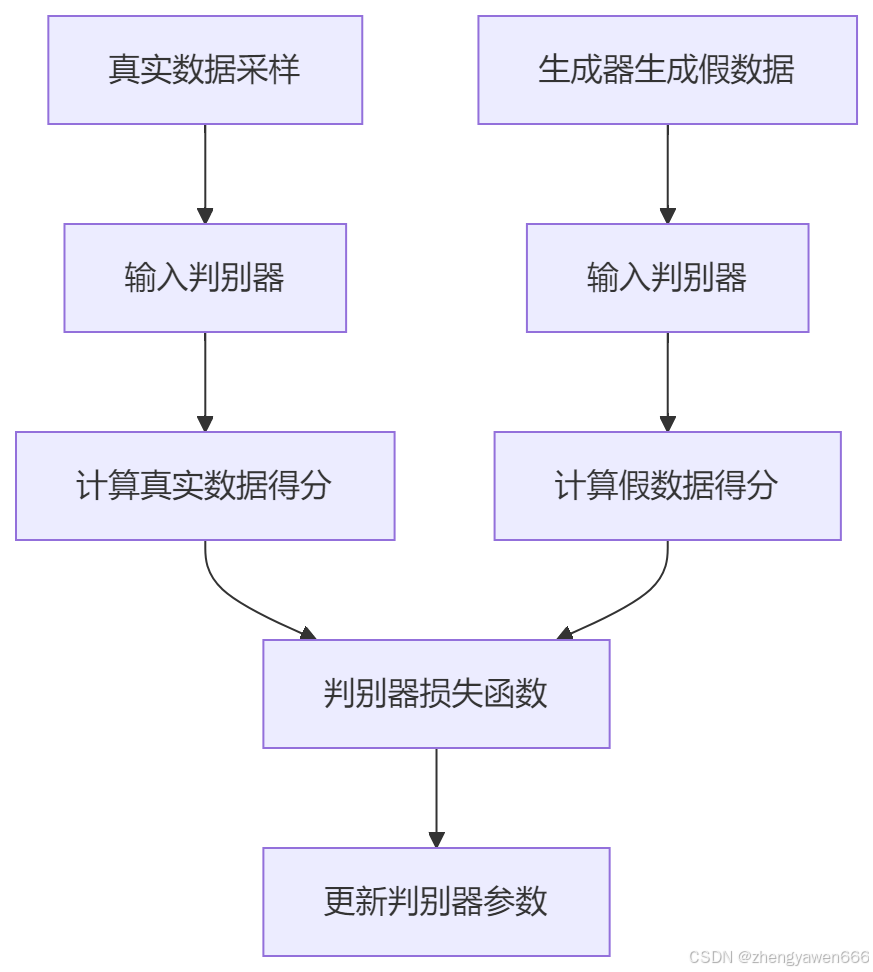
-
对抗训练:生成器和判别器通过对抗训练相互竞争,生成器学习生成更逼真的数据,判别器学习更准确地区分真假数据。
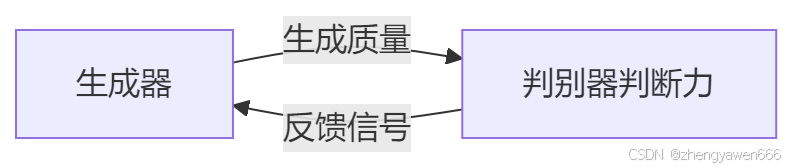
GAN 的优势
-
数据生成:GAN 可以生成新的数据实例,如图像、音频等,这在数据增强、数据合成等方面非常有用。
-
风格迁移:GAN 可以用于风格迁移任务,如将一种艺术风格应用到另一幅图像上。
-
多样性:GAN 能够生成多样化的数据,增加数据集的多样性。
GAN 的缺点
数据非配对问题
在传统的 GAN 中,生成器的目标是生成逼真的数据,而判别器的目标是区分生成的数据和真实数据。然而,GAN 通常需要成对的训练数据,即每个生成的图像都有一个对应的真图像。在实际应用中,成对的训练数据往往难以获取,这限制了 GAN 的应用范围。
信息丢失问题
生成器在生成数据时,可能会丢失一些重要的信息。例如,生成器可能只关注某些特征,而忽略其他特征,导致生成的数据不完整或不准确。
作弊问题
生成器可能会找到一些“捷径”来欺骗判别器,而不是真正学习数据的分布。例如,生成器可能通过添加噪声或模糊来生成图像,而不是生成高质量的数据。这种现象被称为“作弊”。
Cycle-GAN
循环一致性(Cycle Consistency)
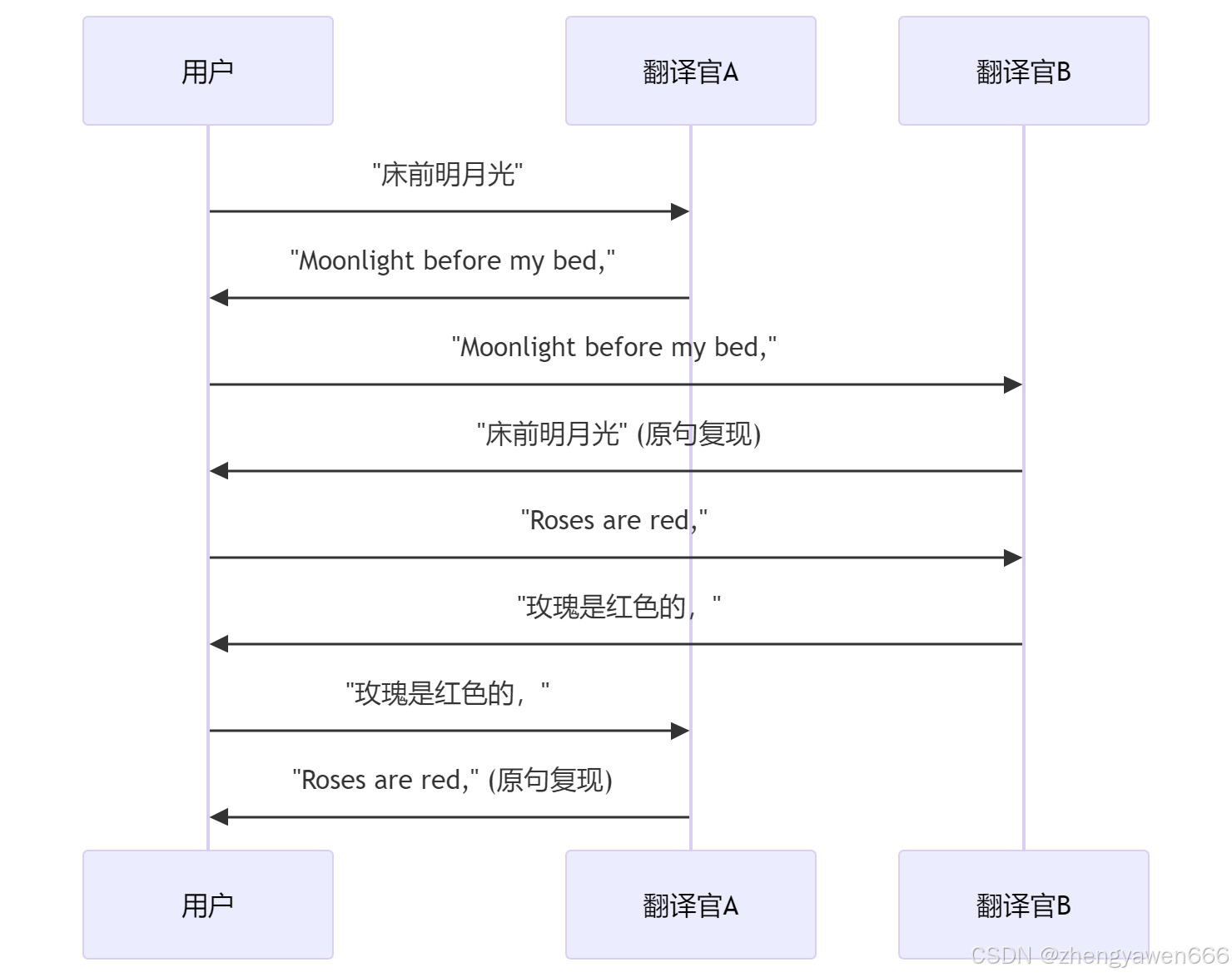
核心要求:
- 翻译要地道(对抗损失)
- 来回翻译保持原意(循环一致性)
CycleGAN 引入了循环一致性约束,确保生成器的转换是可逆的。具体来说:
-
如果将一个域 A 的图像
x转换为域 B 的图像y,然后再将y转换回域 A 的图像x',那么x'应该尽可能接近原始图像x。 -
同理,如果将一个域 B 的图像
y转换为域 A 的图像x,然后再将x转换回域 B 的图像y',那么y'应该尽可能接近原始图像y。
循环一致性约束通过以下方式解决 GAN 的问题:
-
解决数据非配对问题:CycleGAN 不需要成对的训练数据,因为循环一致性约束确保了生成器的转换是可逆的。
-
减少信息丢失:循环一致性约束确保生成器在转换过程中保留了重要的信息,因为生成器必须能够将转换后的图像还原回原始图像。
-
防止作弊:循环一致性约束迫使生成器生成高质量的数据,而不是通过“作弊”来欺骗判别器。
双向转换能力
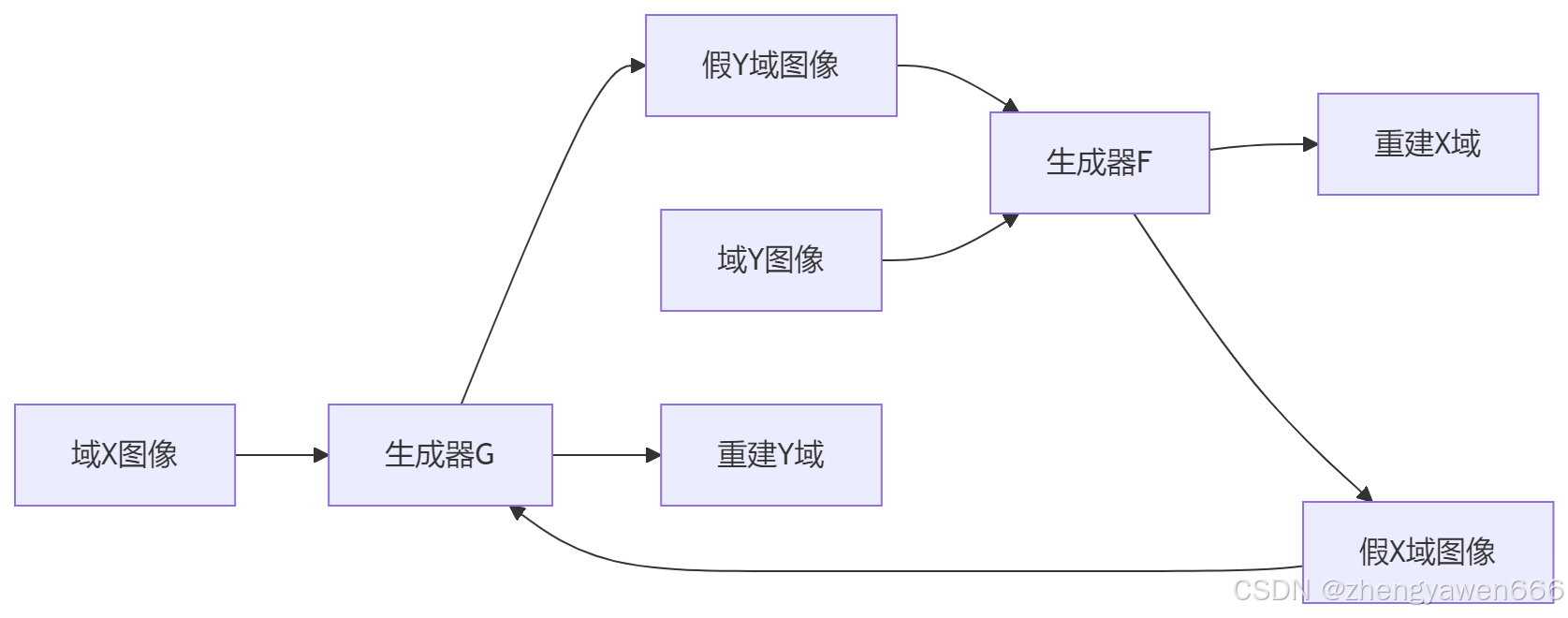
CycleGAN 引入了两个生成器:
-
G:将域 A 的图像转换为域 B 的图像。 -
F:将域 B 的图像转换为域 A 的图像。
这种双向转换能力不仅提高了生成数据的质量,还确保了生成器的转换是可逆的。通过双向转换,生成器必须学习到两个域之间的双向映射关系,从而生成更高质量的数据。
图像转换的具象例子
案例:苹果变橘子
| 原始数据 | 转换过程 | 结果验证 |
|---|---|---|
| 苹果照片→ | 生成器G:苹果→橘子 | 橘子要逼真(骗过判别器) |
| 生成的橘子→ | 生成器F:橘子→苹果 | 变回的苹果≈原苹果 |
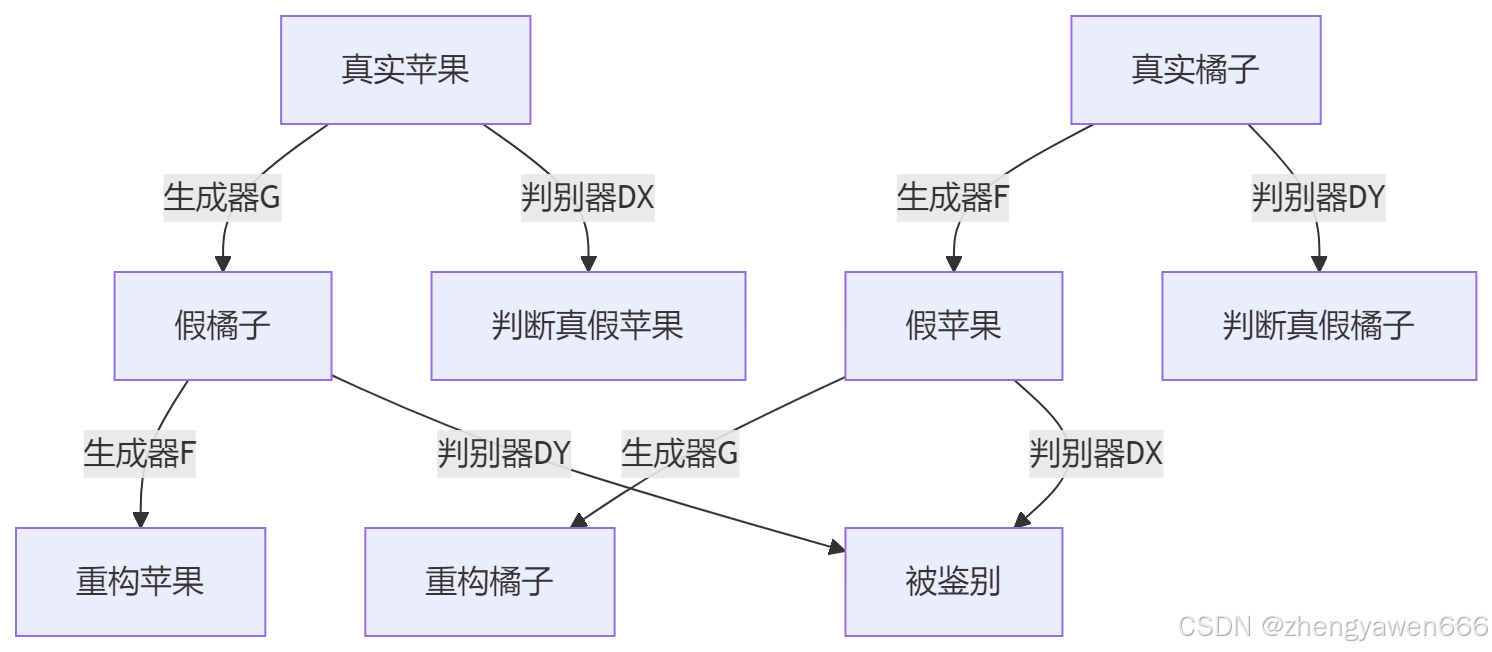
关键验证:
- 假橘子和真实橘子混在一起难以区分
- 苹果→橘子→苹果 几乎不变形
双生成器的必要性
- 生成器G专注学习"如何变形成目标风格"
- 生成器F专注学习"如何恢复原始特征"
- 互相监督,避免乱改内容
为什么 CycleGAN 有效?
-
无需成对数据:CycleGAN 不需要成对的训练数据,这在实际应用中非常有用,因为成对的训练数据往往难以获取。
-
循环一致性:通过循环一致性约束,确保生成器的转换是可逆的,从而减少信息丢失,防止作弊。
-
双向转换能力:通过引入两个生成器,确保生成器学习到两个域之间的双向映射关系,从而生成更高质量的数据。
生成式自监督学习
生成式自监督学习提供了一种框架,特征分离是目标,而自编码器是实现这些目标的常见工具
核心思想
生成式自监督学习的核心思想是让模型自己生成训练数据的一部分,然后使用这些生成的数据来训练模型。这种方法通常涉及到重构任务,即模型需要学习如何从输入数据中提取特征,以便能够重建或生成原始输入。
关键组件
-
编码器(Encoder):将输入数据编码成一种紧凑的表示形式。
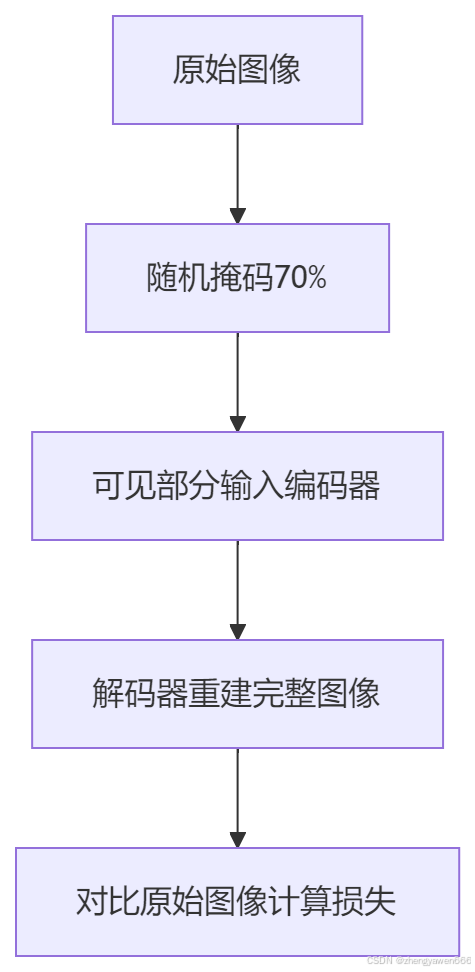
-
解码器(Decoder):从编码表示中重建原始数据。
-
损失函数:通常涉及到重构误差,即输入数据和重建数据之间的差异。
常见方法
自编码器(Autoencoder):一种简单的生成式自监督学习方法,其中模型被训练来最小化输入和输出之间的差异。
变分自编码器(Variational Autoencoder, VAE):通过引入随机性来学习更丰富的特征表示。
对比学习(Contrastive Learning):通过对比相似和不相似的样本来学习特征表示。
生成对抗网络(GAN):虽然GAN 主要用于生成任务,但它也可以用于自监督学习,通过生成器和判别器的对抗训练来学习特征。
优势
-
无需标签:不需要外部标签信息,适用于标签获取成本高或不可行的情况。
-
特征学习:能够学习到数据的有用特征表示,这些特征可以迁移到其他任务,如分类、检测等。
-
灵活性:可以应用于各种类型的数据,如图像、文本、音频等。
挑战
-
评估困难:由于缺乏标签,评估生成式自监督学习的性能可能更加困难,通常需要设计特定的评估指标或依赖于定性任务的表现。
-
训练稳定性:某些生成式自监督模型可能难以训练,特别是当涉及到复杂的数据分布时。
总结
生成式自监督学习是一种强大的自监督学习方法,它通过让模型自己生成训练数据的一部分来学习数据的特征表示。这种方法在处理无标签数据时特别有用,可以学习到的特征表示可以迁移到多种下游任务。
特征分离
评论记录:
回复评论: