
介绍
基于卷积神经网络(CNN)的猫狗图片分类项目是机器学习领域中的一种常见任务,它涉及图像处理和深度学习技术。以下是该项目的技术点和流程介绍:
技术点
- 卷积神经网络 (CNN): CNN 是一种专门用于处理具有类似网格结构的数据的神经网络模型,比如时间序列数据或二维的图像数据。CNN 的核心组件包括卷积层、池化层和全连接层。
- 卷积层: 卷积层使用滤波器(或称内核)在输入图像上滑动,并计算局部加权和来检测图像中的特征,如边缘、纹理等。
- 激活函数: 激活函数(如ReLU, Sigmoid等)引入非线性因素,使得网络可以学习到更复杂的模式。
- 池化层: 通常采用最大池化或平均池化操作,用于减少空间尺寸,降低参数数量,同时保留最重要的信息。
- 全连接层: 在最后几层,CNN 会将多维的特征图展平为一维向量,并通过全连接层进行分类预测。
- 损失函数与优化算法: 使用交叉熵作为损失函数,通过反向传播和梯度下降等优化算法来更新网络权重。
- 正则化技术: 包括L2正则化、Dropout等,以防止过拟合。
- 数据增强: 通过对原始图像进行旋转、翻转、缩放等变换生成更多的训练样本,增加模型的泛化能力。
- 预训练模型: 可以利用已经在大规模数据集上训练好的模型(如VGG16, ResNet等),并在此基础上进行迁移学习。
流程
- 数据收集: 收集大量标注好的10种物体的图片作为训练集和测试集。
- 数据预处理: 对图像进行标准化(如调整大小、归一化像素值)以及可能的数据增强。
- 构建模型: 设计CNN架构,选择合适的层数、滤波器大小和其他超参数。
- 训练模型: 使用训练数据集对CNN进行训练,调整模型参数以最小化损失函数。
- 评估模型: 在验证集或独立的测试集上评估模型性能,检查准确率、召回率等指标。
- 调优模型: 根据评估结果调整模型架构或超参数,重复训练和评估过程直至满意。
- 部署模型: 将最终训练好的模型部署到生产环境中,实现对新图像的实时分类。
- 持续改进: 随着时间推移,可能会有新的数据加入,或者发现模型表现不佳的地方,这时就需要不断迭代和改进模型。
10种物体识别
基于卷积神经网络(CNN)的10种物体识别项目可以是一个非常有趣且具有挑战性的任务,适用于教育、研究或商业应用。下面将介绍一个典型的项目框架,并列举可能涉及的10种类别物体。
项目概述
-
目标:开发一个深度学习模型,使用卷积神经网络来识别和分类图像中的10种不同类型的物体。
-
数据集:为了训练和测试模型,需要收集或使用现有的标记数据集,其中包含每个类别的大量样本图像。常用的数据集如ImageNet、CIFAR-10等可以作为起点,但为了确保涵盖特定的10种类别,你可能需要定制自己的数据集。
工具和技术
- 编程语言:Python
- 深度学习框架:TensorFlow, Keras, PyTorch
- 预处理工具:OpenCV, PIL/Pillow
- 硬件加速:GPU (NVIDIA CUDA)
- 评估指标:准确率、召回率、F1分数、混淆矩阵等。
10种类别物体
对于这个项目,我们可以选择以下10种类别的物体:
- 猫 - 家养宠物之一。
- 狗 - 另一家养宠物。
- 汽车 - 交通工具。
- 飞机 - 空中交通工具。
- 自行车 - 非机动车。
- 椅子 - 日常用品。
- 桌子 - 日常用品。
- 苹果 - 水果。
- 瓶子 - 容器物品。
- 书本 - 学习用品。
项目步骤
- 数据收集与准备
收集每种类别至少几千张图片。
对图片进行标注,确保类别标签正确无误。
将数据分为训练集、验证集和测试集(例如按照7:1:2的比例)。 - 数据增强
使用数据增强技术(如旋转、缩放、裁剪、翻转等)来扩充数据集,提高模型泛化能力。 - 构建CNN模型
设计或选择预训练的CNN架构(如VGG16, ResNet, Inception等)。
根据具体需求调整网络结构,比如增加或减少层数、改变滤波器大小等。 - 训练模型
使用适当的优化算法(如Adam, SGD)和损失函数(如交叉熵损失)。
在训练过程中监控过拟合问题,必要时采用正则化方法(如Dropout)。 - 模型评估
在验证集上评估模型性能,根据结果调参以改进模型。
使用测试集最终评估模型的表现,并记录各项评价指标。 - 模型部署
将训练好的模型导出为可以在实际环境中运行的形式。
如果是Web应用程序,则可以通过Flask/Django等框架部署;如果是移动应用,则考虑转换为轻量级格式如TensorFlow Lite。
导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
- 1
- 2
- 3
- 4
加载数据
(x_train_all, y_train_all), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
x_valid.shape
- 1
- 2
- 3
- 4
- 5
- 6
(5000, 32, 32, 3)
- 1
x_train.shape
- 1
(45000, 32, 32, 3)
- 1
x_test.shape
- 1
(10000, 32, 32, 3)
- 1
y_test.shape
- 1
(10000, 1)
- 1
plt.imshow(x_test[0])
plt.title(y_test[0][0])
- 1
- 2
Text(0.5, 1.0, '3')
- 1

x_test[0]
- 1
array([[[158, 112, 49],
[159, 111, 47],
[165, 116, 51],
...,
[137, 95, 36],
[126, 91, 36],
[116, 85, 33]],
[[152, 112, 51],
[151, 110, 40],
[159, 114, 45],
...,
[136, 95, 31],
[125, 91, 32],
[119, 88, 34]],
[[151, 110, 47],
[151, 109, 33],
[158, 111, 36],
...,
[139, 98, 34],
[130, 95, 34],
[120, 89, 33]],
...,
[[ 68, 124, 177],
[ 42, 100, 148],
[ 31, 88, 137],
...,
[ 38, 97, 146],
[ 13, 64, 108],
[ 40, 85, 127]],
[[ 61, 116, 168],
[ 49, 102, 148],
[ 35, 85, 132],
...,
[ 26, 82, 130],
[ 29, 82, 126],
[ 20, 64, 107]],
[[ 54, 107, 160],
[ 56, 105, 149],
[ 45, 89, 132],
...,
[ 24, 77, 124],
[ 34, 84, 129],
[ 21, 67, 110]]], dtype=uint8)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
归一化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 32, 32, 3)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 32, 32, 3)
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 32, 32, 3)
- 1
- 2
- 3
- 4
- 5
- 6
构建网络
卷积层与池化层
模型由多个卷积层和最大池化层交替组成,每一组卷积层后面跟着一个最大池化层以减少特征图的空间维度。
- 第一组:
- Conv2D(32, (3, 3), padding=‘same’, activation=‘relu’):应用 32 个 3x3 的滤波器进行卷积操作,保持输入图像大小不变(padding=‘same’),激活函数采用 ReLU。
- 第二个 Conv2D 层同样设置,进一步提取特征。
- MaxPool2D(pool_size=2):对前一层输出应用 2x2 的最大池化,将空间尺寸减半。
- 第二组:
- 类似地,两个 Conv2D 层分别有 64 个滤波器,然后是一个 MaxPool2D 层。
- 第三组:
- 两个 Conv2D 层各有 128 个滤波器,之后是另一个 MaxPool2D 层。
随着网络深度增加,滤波器数量逐渐增多,以便在网络较深的地方捕捉到更为复杂的模式。
全连接层
在所有卷积和池化层之后,使用 Flatten() 将多维特征图展平成一维向量,准备送入全连接层。
- Dense(256, activation=‘relu’):第一个全连接层包含 256 个神经元,使用 ReLU 激活函数。
- Dense(10, activation=‘softmax’):最后一层是输出层,包含 10 个神经元(对应于 CIFAR-10 数据集中的 10 类别),使用 Softmax 激活函数来计算每个类别的概率分布。
# 定义卷积神经网络.
model = tf.keras.models.Sequential()
# 2次卷积, 一次池化, 总共3层.
model.add(tf.keras.layers.Conv2D(filters=32,
kernel_size=3,
padding='same',
activation='relu',
input_shape=(32, 32, 3)))
model.add(tf.keras.layers.Conv2D(filters=32,
kernel_size=3,
padding='same',
activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=2))
model.add(tf.keras.layers.Conv2D(filters=64,
kernel_size=3,
padding='same',
activation='relu',
))
model.add(tf.keras.layers.Conv2D(filters=64,
kernel_size=3,
padding='same',
activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=2))
model.add(tf.keras.layers.Conv2D(filters=128,
kernel_size=3,
padding='same',
activation='relu',
))
model.add(tf.keras.layers.Conv2D(filters=128,
kernel_size=3,
padding='same',
activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=2))
# 展平
model.add(tf.keras.layers.Flatten())
# 全连接
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
# 配置网络
model.compile(loss='sparse_categorical_crossentropy',
optimizer='sgd',
metrics=['acc'])
- 1
- 2
- 3
- 4
model.summary()
- 1
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 64) 18496
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 128) 73856
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 128) 147584
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 2048) 0
_________________________________________________________________
dense (Dense) (None, 256) 524544
_________________________________________________________________
dense_1 (Dense) (None, 10) 2570
=================================================================
Total params: 814,122
Trainable params: 814,122
Non-trainable params: 0
_________________________________________________________________
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
训练
history = model.fit(x_train_scaled, y_train, epochs=10,
validation_data=(x_valid_scaled, y_valid))
- 1
- 2
Epoch 1/10
1407/1407 [==============================] - 23s 7ms/step - loss: 2.0446 - acc: 0.2523 - val_loss: 1.5073 - val_acc: 0.4620
Epoch 2/10
1407/1407 [==============================] - 8s 6ms/step - loss: 1.4460 - acc: 0.4779 - val_loss: 1.3928 - val_acc: 0.4978
Epoch 3/10
1407/1407 [==============================] - 9s 6ms/step - loss: 1.2067 - acc: 0.5725 - val_loss: 1.2788 - val_acc: 0.5326
Epoch 4/10
1407/1407 [==============================] - 9s 6ms/step - loss: 1.0413 - acc: 0.6353 - val_loss: 1.0222 - val_acc: 0.6352
Epoch 5/10
1407/1407 [==============================] - 9s 6ms/step - loss: 0.8863 - acc: 0.6892 - val_loss: 0.9801 - val_acc: 0.6566
Epoch 6/10
1407/1407 [==============================] - 9s 6ms/step - loss: 0.7900 - acc: 0.7238 - val_loss: 1.1513 - val_acc: 0.6224
Epoch 7/10
1407/1407 [==============================] - 9s 6ms/step - loss: 0.6945 - acc: 0.7588 - val_loss: 1.0648 - val_acc: 0.6648
Epoch 8/10
1407/1407 [==============================] - 9s 6ms/step - loss: 0.6145 - acc: 0.7862 - val_loss: 0.9035 - val_acc: 0.6846
Epoch 9/10
1407/1407 [==============================] - 9s 6ms/step - loss: 0.5239 - acc: 0.8180 - val_loss: 0.9660 - val_acc: 0.6902
Epoch 10/10
1407/1407 [==============================] - 8s 6ms/step - loss: 0.4609 - acc: 0.8407 - val_loss: 0.7780 - val_acc: 0.7456
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
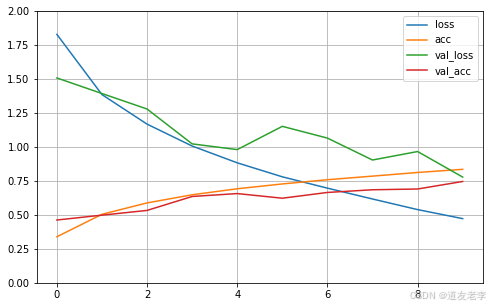
history.history
- 1
{'loss': [1.8281360864639282,
1.3848625421524048,
1.1676044464111328,
1.0064343214035034,
0.8828362822532654,
0.7799011468887329,
0.696526050567627,
0.6166756749153137,
0.5386707782745361,
0.47219154238700867],
'acc': [0.33882221579551697,
0.5040444731712341,
0.5877777934074402,
0.6477555632591248,
0.6919999718666077,
0.7274444699287415,
0.7585333585739136,
0.78493332862854,
0.8118444681167603,
0.8349999785423279],
'val_loss': [1.5073190927505493,
1.392819881439209,
1.278789758682251,
1.0222294330596924,
0.9801304936408997,
1.151273488998413,
1.0647720098495483,
0.9035186767578125,
0.9659541845321655,
0.7779567241668701],
'val_acc': [0.4620000123977661,
0.49779999256134033,
0.5325999855995178,
0.635200023651123,
0.6565999984741211,
0.6223999857902527,
0.6647999882698059,
0.6845999956130981,
0.6901999711990356,
0.7455999851226807]}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid()
plt.gca().set_ylim(0, 2)
plt.show()
- 1
- 2
- 3
- 4
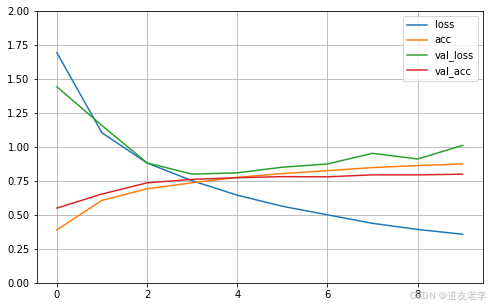
加入dropout减轻过拟合现象.
# 加入dropout减轻过拟合现象.
model = tf.keras.models.Sequential()
# 2次卷积, 一次池化, 总共3层.
model.add(tf.keras.layers.Conv2D(filters=32,
kernel_size=3,
padding='same',
activation='relu',
input_shape=(32, 32, 3)))
model.add(tf.keras.layers.Conv2D(filters=32,
kernel_size=3,
padding='same',
activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=2))
model.add(tf.keras.layers.Conv2D(filters=64,
kernel_size=3,
padding='same',
activation='relu',
))
model.add(tf.keras.layers.Conv2D(filters=64,
kernel_size=3,
padding='same',
activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=2))
model.add(tf.keras.layers.Conv2D(filters=128,
kernel_size=3,
padding='same',
activation='relu',
))
model.add(tf.keras.layers.Conv2D(filters=128,
kernel_size=3,
padding='same',
activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=2))
# 展平
model.add(tf.keras.layers.Flatten())
# 全连接
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.AlphaDropout(0.3))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
history = model.fit(x_train_scaled, y_train, epochs=10,
validation_data=(x_valid_scaled, y_valid))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
Epoch 1/10
1407/1407 [==============================] - 10s 7ms/step - loss: 2.0416 - acc: 0.2821 - val_loss: 1.4422 - val_acc: 0.5498
Epoch 2/10
1407/1407 [==============================] - 9s 7ms/step - loss: 1.1730 - acc: 0.5812 - val_loss: 1.1576 - val_acc: 0.6530
Epoch 3/10
1407/1407 [==============================] - 9s 7ms/step - loss: 0.9152 - acc: 0.6794 - val_loss: 0.8822 - val_acc: 0.7354
Epoch 4/10
1407/1407 [==============================] - 9s 6ms/step - loss: 0.7615 - acc: 0.7283 - val_loss: 0.7998 - val_acc: 0.7612
Epoch 5/10
1407/1407 [==============================] - 9s 6ms/step - loss: 0.6454 - acc: 0.7755 - val_loss: 0.8090 - val_acc: 0.7732
Epoch 6/10
1407/1407 [==============================] - 9s 7ms/step - loss: 0.5455 - acc: 0.8102 - val_loss: 0.8505 - val_acc: 0.7812
Epoch 7/10
1407/1407 [==============================] - 9s 7ms/step - loss: 0.4962 - acc: 0.8244 - val_loss: 0.8744 - val_acc: 0.7798
Epoch 8/10
1407/1407 [==============================] - 9s 7ms/step - loss: 0.4079 - acc: 0.8583 - val_loss: 0.9528 - val_acc: 0.7944
Epoch 9/10
1407/1407 [==============================] - 9s 7ms/step - loss: 0.3728 - acc: 0.8690 - val_loss: 0.9108 - val_acc: 0.7942
Epoch 10/10
1407/1407 [==============================] - 9s 7ms/step - loss: 0.3297 - acc: 0.8826 - val_loss: 1.0115 - val_acc: 0.7992
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid()
plt.gca().set_ylim(0, 2)
plt.show()
- 1
- 2
- 3
- 4
评论记录:
回复评论: