
ODTrack论文阅读
一.Abstract:
连续视频帧之间的在线上下文推理和关联对于视觉跟踪中的实例感知至关重要。然而,目前大多数表现最好的跟踪器通过离线模式持续依赖于参考帧和搜索帧之间的稀疏时间关系。
a t − n , … , a t − 1 , a t {a_{t−n},…,a_{t−1},{a_t}} at−n,…,at−1,at
二.Introduction:
作者采用了One-Stream的框架,pipeline用的是OSTrack
- 使用了3张Template构建Template_list与一张Search构建融合特征
- 使用了2张Search,每张分别进行一次上述过程
- 在Test和Eval中,保存历史预测Box,并根据这个Box裁剪出相应的历史Template,便于后续帧序列的Template采样3张
图来自另外一个人的博客。
1.存在的问题:
but still exhibit the following drawbacks: (1) The sampling frames are sparse (i.e., using only one reference frame and one search frame).
- search和template图像对之间的采样是稀疏的,不足以充分表达目标的动态变化
- 在test和eval中,search和template之间的匹配是离线的(就是template或者search没有更新),这阻碍了其中互信息的表达
大多数离线方法(如图1a所示)只使用稀疏的时间帧进行跟踪(例如,一个参考帧和一个搜索帧)。现有方法通过图像对的匹配将目标信息从参考帧传播到搜索帧,但这种匹配仅限于当前帧,未能充分利用跨帧的连续关联。
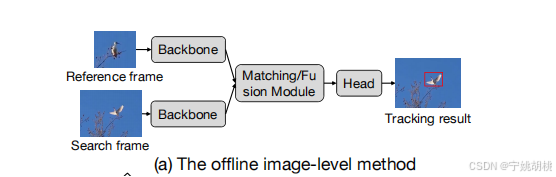
To incorporate temporal information into the model, some approaches commonly design online updating techniques, such as updating templates(Yan et al. 2021a; Cui et al. 2022) and updating model parameters(Bhat et al. 2019). Despite being successful, these methods still rely on sparse sampling frames (i.e., reference, search, and update frames) and do not effectively explore how information is propagated online across search frames. This inspired us to think: can our visual tracking algorithm densely associate and perceive an object in a video streaming context?(我们的视觉跟踪算法能否在视频流环境中密集地关联和感知一个对象?)
2.动机和解决方案:
动机:
提出ODTrack的动机:
- 为了解决上述问题,作者提出了一种新的视频级跟踪框架——ODTrack,其核心思想是将目标跟踪重新定义为一个令牌序列传播任务。
- ODTrack通过在线令牌传播的方式,在视频帧之间密集关联上下文关系,从而使模型能够捕捉到目标的时空轨迹,并通过视频流进行建模。
- 这种方式不仅可以更好地处理连续视频中的目标,还能简化复杂的在线更新策略,实现更高效的推理和更精准的目标定位。
解决方案:
使用token sequence propagation paradigm(这里的说法让人困惑,操作是在ViT的第3、6、9层block中,把注意力的嵌入向量进行最大值筛选, 把这个筛选的标准当成了token)
作者设计了两种简单而有效的时间令牌传播注意机制**(拼接令牌注意力机制(Concatenated Token Attention Mechanism)和分离令牌注意力机制(Separated token attention mechanism))**,可以通过压缩目标的判别特征,将其转化为令牌序列用于下一帧的推理。
在test或eval中把预测过的bbox存起来,并根据这个裁剪出用于更新的template,存在内存中,便于后面构成template_list,用于更新,如下图
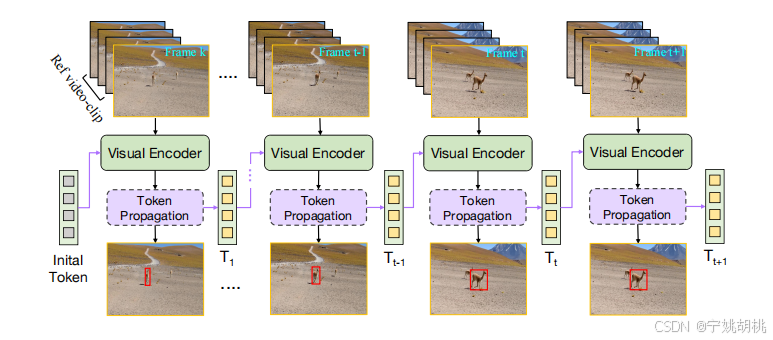
这里的Visual Encoder是论文提到的Vision Transformer, ViT
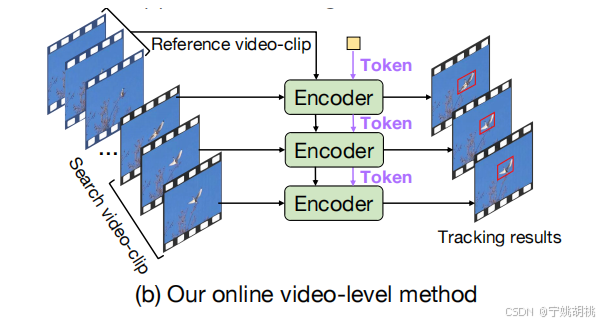
2.1. 输入部分(左侧):
- 图中左侧展示了一个参考视频片段和一个搜索视频片段。
- 参考视频片段(Reference video-clip)是用来初始化目标特征的,而搜索视频片段(Search video-clip)是模型需要在后续帧中找到并跟踪的目标。
2.2. 在线令牌传播(Token Propagation):
- 从参考视频片段中提取的目标特征被压缩成一个令牌(Token),如图中用紫色的方块所示。
- 该令牌通过每一帧之间在线传播,表示目标的外观、位置以及时空特征。
- 这些令牌作为未来帧推理的提示,帮助模型根据之前帧的信息定位后续帧中的目标。
2.3. 编码器(Encoder):
- 每一帧的视频数据都会经过一个编码器(Encoder),编码器将输入帧的视频信息转化为可供模型处理的特征表示。
- 随着视频的播放,令牌序列在每个时间步都会传递给下一个编码器,从而逐帧地传递上下文信息。
- 这些编码器将令牌与当前帧的视频特征进行关联,使得模型可以逐帧理解目标的时空轨迹。
2.4. 输出(右侧):
- 经过编码器处理后的结果将输出为跟踪结果(Tracking results)。模型在每一帧中根据累积的上下文信息来进行推理,从而实现目标在视频中的精确跟踪。
三.Related Work:
1. 传统跟踪框架(Traditional Tracking Framework):
该部分介绍了目前主流的跟踪方法,尤其是Siamese跟踪范式。Siamese跟踪器的核心思想是通过图像对匹配来实现目标跟踪,以下是具体的内容:
- Siamese跟踪的特点:
- 这类跟踪方法通过对参考帧和搜索帧进行匹配,来判断目标的运动情况。虽然Siamese网络在许多任务中取得了成功,但它的局限在于对时序信息的利用不足,仅能处理两帧之间的稀疏关联。
- 性能提升策略:
- 为了提高Siamese跟踪器的性能,研究者提出了多种改进策略,包括:
- 预测头网络(Prediction head networks),用于优化目标预测【如Li et al. 2018; Chen et al. 2020; Zhang et al. 2020】。
- 跨相关模块(Cross-correlation modules),提升了特征匹配的性能【如Han et al. 2021; Liao et al. 2020; Chen et al. 2021】。
- 更强大的骨干网络(Powerful backbone),通过改进深度学习特征提取【如Chen et al. 2022; Cui et al. 2022】。
- 注意力机制(Attention mechanisms),增强了特征间的交互【如Guo et al. 2021; Yu et al. 2020】。
- 为了提高Siamese跟踪器的性能,研究者提出了多种改进策略,包括:
- Transformer的引入:
- 最近引入的Transformer【Vaswani et al. 2017】为跟踪器提供了更强大的特征交互能力,推动了跟踪算法的显著进步【Yan et al. 2021a; Xie et al. 2022; Cui et al. 2022; Ye et al. 2022】。
- 问题与局限:
- 尽管这些方法在特征建模上有了很大的进展,但大部分方法依然基于离线模式和稀疏图像对策略,无法充分理解目标在时间维度上的运动状态。
- 相比这些方法,ODTrack重新将目标跟踪定义为令牌序列传播任务,并且旨在有效利用目标的时间信息,构建更强大的自回归(auto-regressive)机制。
2. 视觉跟踪中的时间建模(Temporal Modelling in Visual Tracking):
这部分回顾了现有方法在视觉跟踪中探索时间线索(temporal cues)的研究:
- 多目标跟踪:
- 多目标跟踪(MOT)通常通过识别和关联视频中的多个对象,并研究其轨迹信息。相较之下,单目标跟踪(SOT)对时空轨迹信息的研究相对较少。
- 在线更新方法:
- 为了在Siamese框架内探索时间线索,一些在线更新策略被设计出来:
- UpdateNet【Zhang et al. 2019】提出了一种自适应更新策略,利用自定义网络融合累积的模板特征并生成加权更新模板,用于视觉跟踪。
- DCF(离散余弦变换)跟踪器【Danelljan et al. 2019; Bhat et al. 2019】通过复杂的优化技术在线更新模型参数,提升了跟踪的鲁棒性。
- STMTrack 和 TrDiMP【Fu et al. 2021; Wang et al. 2021a】使用注意力机制提取时间维度的上下文信息,增强了时间推理能力。
- STARK 和 Mixformer【Yan et al. 2021a; Cui et al. 2022】设计了特定的目标质量分支,用于更新模板帧,帮助提升跟踪结果。
- 为了在Siamese框架内探索时间线索,一些在线更新策略被设计出来:
- 时空上下文的探索:
- 最近,一些研究开始从不同角度探索时间上下文的建模:
- TCTrack【Cao et al. 2022】引入了一种在线时间自适应卷积和自适应时间Transformer,在特征提取和相似性图细化两个层面上聚合时间上下文。
- VideoTrack【Xie et al. 2023】基于视频Transformer设计了一个新的跟踪器,利用简单的前馈网络编码时间依赖性。
- ARTrack【Xing et al. 2023】提出了一种新的时间自回归跟踪器,通过逐步估计目标的坐标序列来实现跟踪。
- 最近,一些研究开始从不同角度探索时间上下文的建模:
- 现有方法的局限:
- 尽管这些跟踪算法在一定程度上探索了时间信息,但仍存在一些局限性:
- 优化过程复杂,涉及专门的损失函数设计、多阶段训练策略和手动更新规则。
- 时间线索的传播未能在搜索帧之间得到充分研究,没有研究时间线索是如何在搜索框架中传播的。
- 尽管这些跟踪算法在一定程度上探索了时间信息,但仍存在一些局限性:
Further, we propose a new baseline approach, called ODTrack, focused on unlocking the potential of temporal modeling through the propagation of target motion/trajectory information.(重点是通过目标运动/轨迹信息的传播来释放时间建模的潜力)
四.Approach:
sample和template mask生成方法:
根据box而来,如下图:


采样:
if self.frame_sample_mode == 'causal':
# Sample test and train frames in a causal manner, i.e. search_frame_ids > template_frame_ids
while search_frame_ids is None:
base_frame_id = self._sample_visible_ids(visible, num_ids=1,
min_id=self.num_template_frames - 1,
max_id=len(visible) - self.num_search_frames)
prev_frame_ids = self._sample_visible_ids(visible, num_ids=self.num_template_frames - 1,
min_id=base_frame_id[0] - self.max_gap - gap_increase,
max_id=base_frame_id[0])
if prev_frame_ids is None:
gap_increase += 5
continue
template_frame_ids = base_frame_id + prev_frame_ids
if (not template_frame_ids is None) and (len(template_frame_ids) > 1):
template_frame_ids.sort(reverse=False) # Sort from small to large
search_frame_ids = self._sample_visible_ids(visible, num_ids=self.num_search_frames,
min_id=template_frame_ids[-1] + 1,
max_id=template_frame_ids[-1] + self.max_gap + gap_increase)
if (not search_frame_ids is None) and (len(search_frame_ids) > 1):
search_frame_ids.sort(reverse=False) # Sort from small to large
# Increase gap until a frame is found
gap_increase += 5

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
首先采样基准帧,基准帧数量1,min_id设置为num_template_frames - 1,是为了保证在casual模式下,使用过去帧预测未来帧的时候,有足够的模板帧(num_template_frames=3),也就是说至少要让第三帧作为基准帧,前两帧做模板帧。
max_id 被设定为 len(visible) - self.num_search_frames,这是因为在选择基准帧时,需要确保在其之后有足够的帧(即搜索帧)来满足 num_search_frames 的需求。比如,如果可见帧总数是 10,而 num_search_frames 是 2,那么 max_id 就是 10 - 2 = 8。这意味着基准帧的最大索引可以到 8,这样在基准帧之后就至少有 2 个帧可用。
采样2张search和3张template,search是列表输入到网络中,每张search会轮流对应采样的三张template进行预测。
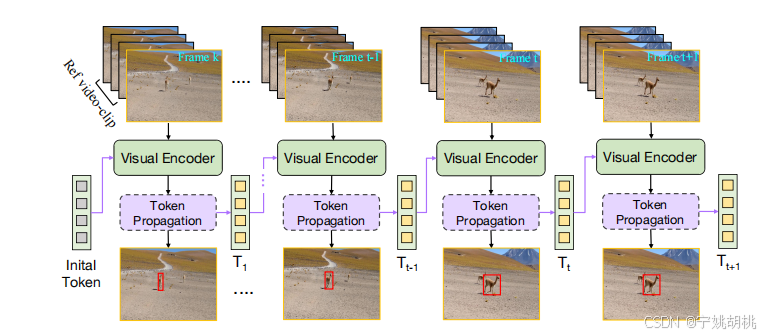
作者介绍了ODTrack,一种新的视频级框架,它使用令牌序列传播来进行可视化跟踪,如图。
1.回顾传统图像对匹配跟踪方法:
ODTrack的研究从回顾图像对匹配的跟踪方法开始,特别是主流的Siamese跟踪器和Transformer跟踪器:
(1)Siamese跟踪器:
-
输入:Siamese跟踪器处理一对视频帧,包括参考帧 R 和搜索帧 S。参考帧 R 表示包含目标的初始帧,而搜索帧 S 是当前帧,模型通过这两个帧的匹配来确定目标在搜索帧中的位置。
-
处理流程:
典型的Siamese跟踪器分为三个阶段:
- 特征提取:从参考帧和搜索帧中提取视觉特征。
- 特征融合:将参考帧和搜索帧的特征进行结合,学习到它们的相似度关系。
- 边界框预测:通过预测模型,输出目标在搜索帧中的边界框位置 BBB。
-
公式:整个过程可以被公式化为 B←Ψ:R,S,即跟踪器 Ψ 接受参考帧和搜索帧作为输入,输出边界框 B。
(2)Transformer跟踪器:
-
输入:Transformer跟踪器也处理参考帧和搜索帧,不过与Siamese跟踪器不同的是,Transformer不直接操作整个帧,而是将图像切割成一系列不重叠的图像补丁。
-
图像嵌入:每个图像补丁被嵌入到一个1D令牌序列中。参考帧和搜索帧的图像补丁分别生成两个1D图像令牌序列 fr 和 fs。
-
特征提取与关系建模:这些 1D 图像令牌随后被连接并输入到 L 层变换器编码器中进行特征提取和关系建模。每个变换器层 δ 包含多头自注意力机制和多层感知机。正向过程可以表示为:
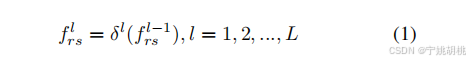
通过采用上述的建模方法,我们可以构建一个简洁、优雅的跟踪器来实现全帧跟踪。然而,这种建模方法有一个明显的缺点。所创建的跟踪器只专注于帧内目标匹配,并且缺乏建立跨视频流跟踪对象所需的帧间关联的能力。因此,这一局限性阻碍了视频级跟踪算法的研究。
本文旨在缓解这一挑战,并提出一种新的视频级跟踪算法设计范式。通过从图像对级别扩展输入到视频级别,实现时序建模。
引入时间令牌:
- 新的设计中引入了一个时间令牌/提示 T,旨在传播关于目标实例在视频序列中的外观、时空位置和轨迹的信息,正式公式如下:
B ← Ψ : { R 1 , R 2 , … , R k , S 1 , S 2 , … , S n , T } B←Ψ:\{R_1,R_2,…,R_k ,S_1,S_2,…,S_n,T\} B←Ψ:{R1,R2,…,Rk,S1,S2,…,Sn,T}
其中 {R1,R2,…,Rk}} 表示长度为 k 的参考帧,{S1,S2,…,Sn} 表示长度为 n 的搜索帧。T 作为一种时间令牌或提示,B是输出的边界框。
2.Video-Level Tracking Pipeline:
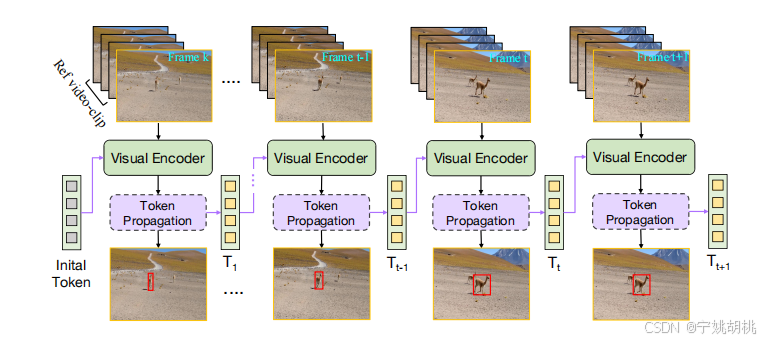
上图所示为新的视频级框架ODTrack的流程图。理论上,ODTrack将整个视频建模为一个连续的序列,并以自回归的方式逐帧解码目标的位置。首先,针对视频级模型的输入要求,提出了一种新颖的视频序列采样策略。随后,为了捕获视频序列中目标实例的时空轨迹信息,引入了两种简单而有效的时间令牌传播注意力机制。
输入视频片段:
- 图中展示了输入的视频帧,包括参考帧(reference frame)和多个搜索帧(search frame)。这些视频帧作为模型的输入,构成视频流,模型需要逐帧对其中的目标进行跟踪。
视觉编码器(Visual Encoder):
- 每个视频帧都会经过视觉编码器。这个编码器负责提取每个视频帧中的视觉特征,从而为后续的令牌传播和目标定位提供基础信息。
令牌传播(Token Propagation):
- 在每一帧视频中,ODTrack通过令牌传播机制(Token Propagation)来传递时空上下文信息。这个机制生成每个视频帧的时空令牌,并将它们传播到后续帧,帮助模型捕捉目标在视频中的运动轨迹。这些令牌包含目标的时空特征,可以看作是在时间维度上关联视频帧的桥梁。
自回归过程(Auto-Regressive Process):
- ODTrack通过自回归方式逐帧解码目标的位置。也就是说,当前帧的预测不仅依赖于当前帧的视觉特征,还依赖于之前帧的信息。通过这种方式,模型可以跨帧捕捉目标的运动信息,并实时更新目标的位置。
目标跟踪结果:
- 最后,模型会对每个视频帧中的目标进行定位,并通过预测边界框的方式输出目标的跟踪结果。
2.1 Video Sequence Sampling Strategy:
大多数现有的跟踪算法(例如Yan et al. 2021a; Cui et al. 2022; Ye et al. 2022)通常在较短的时间间隔内采样图像对(如50帧、100帧或200帧之间)。这种采样方式可能会有一个潜在的缺点,即这些跟踪器无法有效捕捉目标的长时间运动变化,从而限制了其在长期场景中的跟踪鲁棒性。
ODTrack的改进策略:(a larger sampling interval and randomly extract multiple video frames within this interval to form video clips)
- 长时间间隔采样
- 随机抽取多帧
- 任意长度片段 (it enables us to approximate the content of the entire video sequence. This is crucial for video-level modeling)
{ R 1 , R 2 , . . . , R k , S 1 , S 2 , . . . , S n } \{R_1, R_2, ..., R_k, S_1, S_2, ..., S_n\} {R1,R2,...,Rk,S1,S2,...,Sn}
2.2 Temporal Token Propagation Attention Mechanism:
**背景与设计理念:**传统的视频Transformer(如Xie等人2023年提出的架构)通常需要复杂的3D Transformer结构来处理视频内容,而ODTrack选择了一个更为简化的架构,即2D Transformer(ViT),并通过改进的时序注意力机制来扩展其对视频级特征的建模能力。
论文提出的核心在于:
- 扩展2D Transformer的能力:通过设计适合视频序列处理的机制,使其能捕捉和整合视频帧间的时序关系。
- 时空特征整合:为了在多个视频帧中捕捉目标的运动轨迹,论文设计了两种令牌注意力机制(拼接和分离),来帮助模型有效地提取视频序列中的丰富时空特征。
2.2.1拼接令牌注意力机制(Concatenated Token Attention Mechanism)
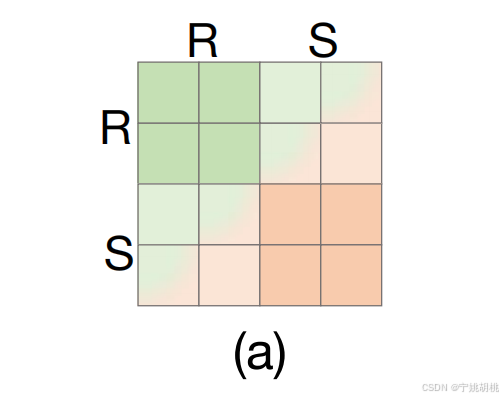
(a)描述了传统注意力机制是如何在图像对之间建模的:
传统的自注意力操作通常以图像对(例如参考帧R和搜索帧S)作为输入。
f
=
A
t
t
n
(
[
R
,
S
]
)
f =Attn([R, S])
f=Attn([R,S])
这种机制下,跟踪器只能在每对图像之间建立局部的关系,并且这些关系是相对独立的,没有更深层次的时序关联。
(b)展示了拼接令牌注意力机制的改进:
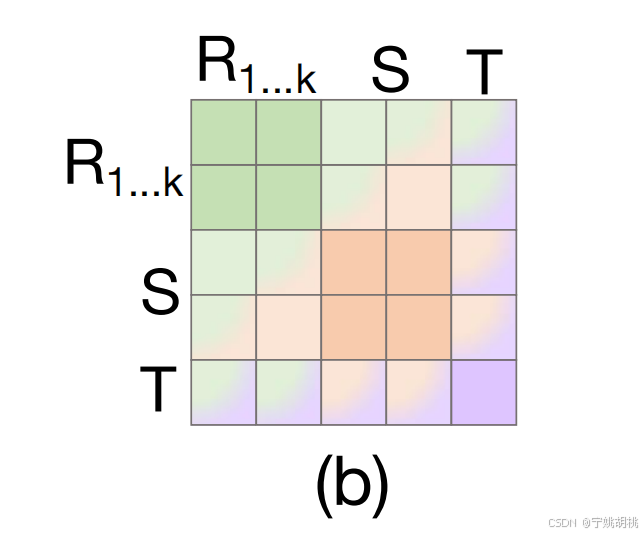
- 时空令牌拼接:为了增强跨帧的时序关联性,拼接令牌注意力机制将多个参考帧的令牌信息(如R1, R2, …, Rk)与当前帧的搜索帧St以及时序令牌Tt进行拼接,从而在更大的上下文中进行时空关系建模。
- 公式(3)描述了这种拼接的过程:
f t = A t t n ( [ R 1 , R 2 , . . . , R k , S t , T t ] ) = ∑ s ′ ′ t ′ ′ V s ′ ′ t ′ ′ ⋅ e x p ⟨ q s t , k s ′ ′ t ′ ′ ⟩ ∑ s ′ t ′ e x p ⟨ q s t , k s ′ t ′ ⟩ f_t=Attn([R_1,R_2,...,R_k,S_t ,T_t])=\sum_{s''t''}{V_{s''t''}}⋅\frac {exp⟨q_{st},k_{s''t''}⟩}{∑_{s't'}exp⟨q_{st},k{s't'}⟩} ft=Attn([R1,R2,...,Rk,St,Tt])=s′′t′′∑Vs′′t′′⋅∑s′t′exp⟨qst,ks′t′⟩exp⟨qst,ks′′t′′⟩
其中,Tt 是第t帧的时序令牌序列,⋅⋅⋅···⋅⋅⋅ 表示令牌的拼接,q_st,k_st,v_st,是拼接特征令牌的时空线性投影 (spatio-temporal linear projections)。通过拼接来自多个帧的信息,模型能够在整个视频序列上建立密集的时空关系。这种机制类似于自然语言处理中通过上下文建立联系的方式,增强了视频中不同时间帧之间的关联性。q_st表示第 t 帧中拼接特征序列的查询向量,k_s‘’t‘’表示参考帧或搜索帧的键向量,做内积计算相关性。
∑ s ′ t ′ e x p ⟨ q s t , k s ′ t ′ ⟩ ∑_{s't'}exp⟨q_{st},k{s't'}⟩ s′t′∑exp⟨qst,ks′t′⟩
分母的符号表示所有时空位置的键向量,与查询键进行相似度计算:
e x p ⟨ q s t , k s ′ ′ t ′ ′ ⟩ {exp⟨q_{st},k_{s''t''}⟩} exp⟨qst,ks′′t′′⟩
分子符号表示的是当前帧的键向量做内积,计算相似度。这个键向量通过与查询的相似度来决定对应的值向量 Vs′′t′′ 的加权程度。
ODTrack引入了一个时序令牌(temporal token)来为每一帧视频存储目标的轨迹信息:
-
目标信息压缩:当前帧的时空轨迹信息被压缩为一个令牌向量,这个向量不仅包含目标的外观信息,还包含目标的位置信息以及运动轨迹。
-
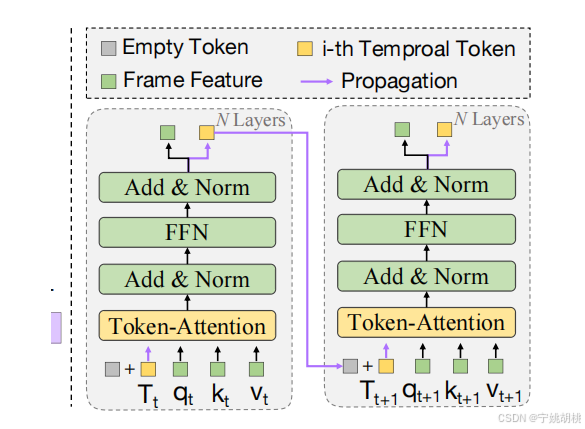
时序传播:在提取了当前帧的目标信息后,这个时序令牌会在自回归的基础上从第t帧传播到第t+1帧,如图所示。
Transformer模型中的前馈神经网络(Feed-Forward NeuralNetwork,FFN)通常采用“先升维“再降维”的设计,这个过程背后的原因主要与模型的表达能力和非线性变换“有关。
1.增加表达能力: FFN通常包含两个线性变换和一个非线性激活函数(如ReLU)之间的操作。通过先升维,将输入从原始维度
(d_model)扩展到更高维度(通常是4d_model),可以使网络在更高的维度空间中进行更加复杂的线性变换。这种升维操作允许模型在更大的特征空间内捕捉到输入的更复杂的模式和关系。2.引入非线性变换: 升维之后的线性变换通常伴随着一个非线性激活函数。非线性激活函数的引入打破了线性模型的限制,使得模型可以对数据进行更复杂的变换。降维操作将升维后的结果映射回原始维度,从而将这些非线性特征组合到最终的输出中。这种操作增强了模型的表达能力,使其能够表示更加复杂的函数关系。
3.计算和参数效率: 尽管升维增加了中间层的复杂性,但最终降维回原始维度可以控制模型的计算成本和参数数量。Transformer中使用的这种“升维-降维”结构是一种折衷方案,既增加了模型的复杂度和表达能力,又不会显著增加计算和存储的开销。
-
传播机制:
在第t帧,时序令牌 T_t被添加到第 t+1帧的空令牌 T_empty,从而更新了第 t+1帧的内容令牌 Tt+1。公式描述为:
T t + 1 = T t + T e m p t y T_{t+1}=T_{t}+T_{empty} Tt+1=Tt+Tempty
该令牌将作为输入传递给接下来的帧,形成一个递归的传播过程。 -
接下来,更新后的时序令牌 T_t+1 与新的参考帧和搜索帧一同被输入到注意力机制中:
f t + 1 = A t t n ( [ R 1 , R 2 , . . . , R k , S t + 1 , T t + 1 ) f_{t+1}=Attn([R_1,R_2,...,R_k,S_{t+1} ,T_{t+1}) ft+1=Attn([R1,R2,...,Rk,St+1,Tt+1) -
在这种新的设计范式中,ODTrack可以使用时间标记作为推断下一帧的提示,利用过去的信息来指导未来的推断。此外,模型通过在线令牌传播**隐式地(implicitly propagates)**传播目标实例的外观、定位和轨迹信息。这显著提高了视频级框架的跟踪性能。
2.2.2 分离令牌注意力机制(Separated token attention mechanism):
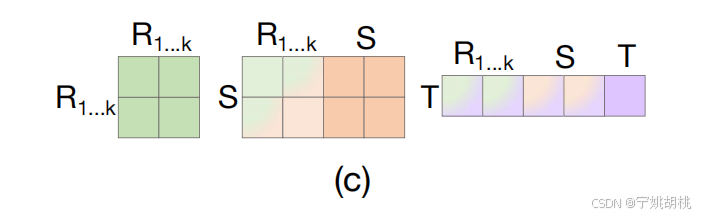
分离令牌注意力机制将注意力操作分解为三个子过程:
自信息聚合(self-information aggregation between reference frame)
交叉信息聚合(cross-information aggregation between reference and search frames)
时间令牌与视频序列之间的交叉信息聚合(cross information aggregation between temporal token and video sequences)
2.3 Prediction Head and Loss Function:
对于预测头网络的设计,ODTrack采用传统的分类头和边界框回归头来达到预期的结果。
采用Focal loss作为分类损失Lcls。
回归损失由两部分组成:L1 loss和GIoU loss作为回归损失。总损失L可表示为:
L
=
L
c
l
s
+
λ
1
L
1
+
λ
2
L
G
I
o
U
L=L_{cls}+λ_1L_1+λ_2L_{GIoU}
L=Lcls+λ1L1+λ2LGIoU
其中,正则化参数为 λ1=5和 λ2=2。每个视频帧的任务损失是独立计算的,最终的损失在搜索帧的长度上平均。
五.Experiments
1. Training
使用 ViT-Base 作为视觉编码器,该模型的参数通过 MAE(He et al. 2022)预训练参数进行初始化。ODTrack训练数据与过去工作对齐,使用LaSOT, GOT-10k, TrackingNet, 和COCO将包含三个192 × 192像素的参考帧和两个384 × 384像素的搜索帧的视频序列作为模型的输入。训练步数设置为300步。在每个历元内随机采样60000个图像对。该模型在一台拥有两块80GB Tesla A100 GPU的服务器上进行,并设置批大小为8
2. 推理(Inference)
- 推理阶段的设置:
- 推理时与训练设置保持一致,使用三个等间隔的参考帧。搜索帧和时间令牌向量则逐帧输入模型。
- 性能对比:
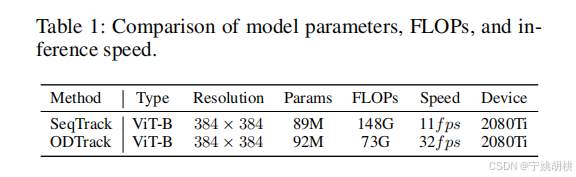
- 对模型参数、浮点运算量(FLOPs)和推理速度进行了比较实验。具体结果见表1。
- 使用 2080Ti 显卡测试所提的 ODTrack 模型,运行速度为 32 帧每秒(fps)。
关键点分析:
- 参数数量(Params):SeqTrack 和 ODTrack 的参数量接近,分别为 89M 和 92M,说明两者模型的复杂度相差不大。
- FLOPs(浮点运算量):ODTrack 的 FLOPs 为 73G,相比 SeqTrack 的 148G,几乎减少了一半。这意味着 ODTrack 需要的计算量大幅降低。
- 推理速度(Speed):在同样的 2080Ti 设备上,ODTrack 运行速度达到了 32 fps,远高于 SeqTrack 的 11 fps。这表明 ODTrack 更为高效,能在相同的硬件上实现更快的推理速度。
- 设备(Device):两者都在 2080Ti 上测试,确保了硬件环境的一致性,使得性能对比更加公平。
3. Comparison with the SOTA(与当前最先进方法(SOTA,State-of-the-Art))
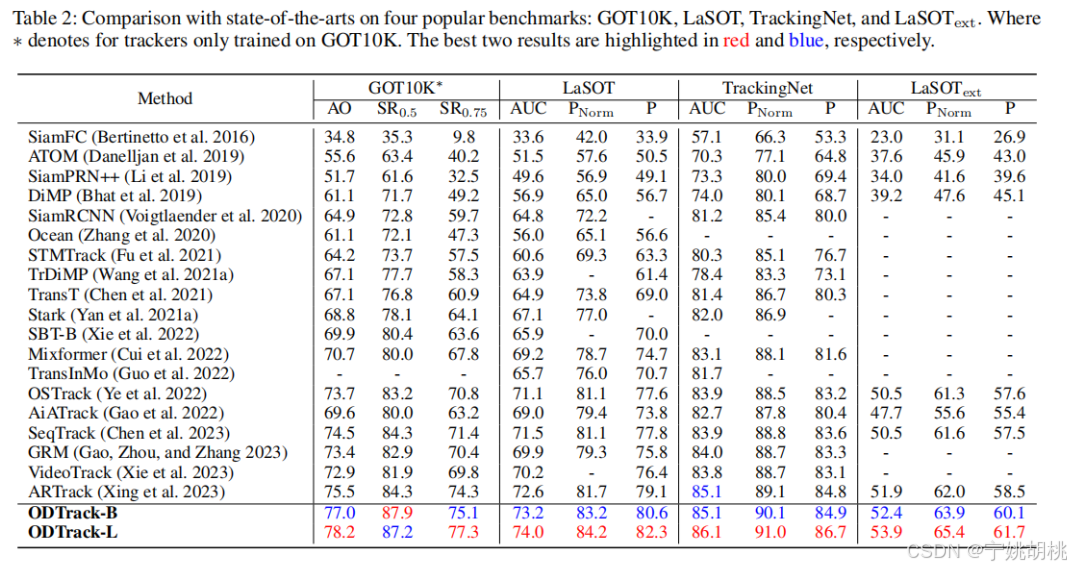
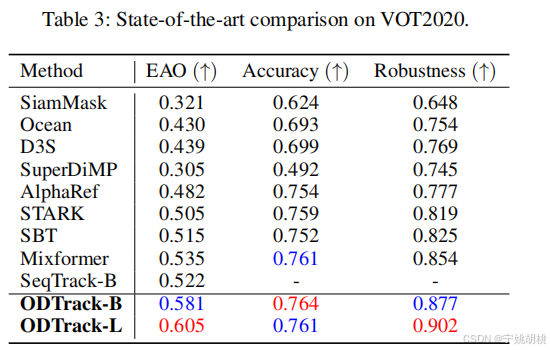
ODTrack 使用 Alpha-Refine 作为后处理网络,以预测视频中的分割掩码。Alpha-Refine 帮助进一步提升分割任务中的精度。
6. Ablation:
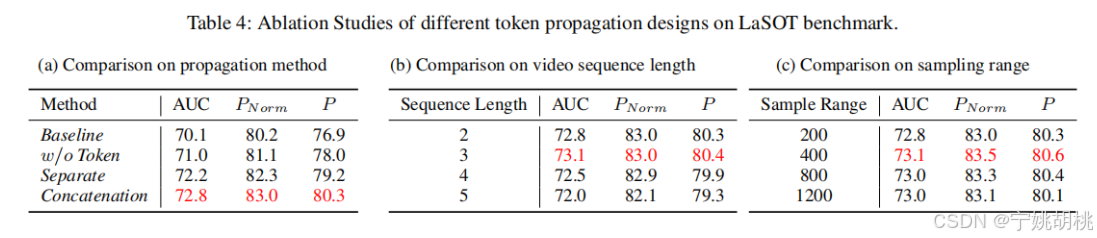
(1)令牌传播的重要性:
为了研究令牌传播的影响,表( a )中进行了时间令牌是否传播的实验。w / o令牌表示没有令牌传播的视频级采样策略的实验。从第2行和第3行可以观察到,令牌传播机制的缺失导致AUC得分下降了1.2 %。这一结果表明,令牌传播在跨帧目标关联中起着至关重要的作用。
(2)不同的令牌传播方法,分别是分离传播和拼接传播:
验证所提出的两种方法的有效性。单独和级联方法都取得了显著的性能提升,其中级联方法表现出略微更好的效果。这证明了两种注意力机制的有效性。
(3)搜索视频片段的长度:
如表 ( b )所示,实验了搜索视频序列长度对跟踪性能的影响。当视频片段长度从2增加到3时,AUC指标提高了0.3 %。然而,序列长度的持续增加并不会带来性能的提升,这表明过长的搜索视频片段会给模型带来学习负担。因此应该选择一个合适的搜索视频片段长度。
(4)采样范围:
为了验证采样范围对算法性能的影响,( c )中展示了视频帧的采样范围实验。当采样范围从200扩大到1200时,在AUC指标上有明显的性能提升,说明视频级框架可以从更大的采样范围中学习目标轨迹信息。
7. Visualization and Limitation:
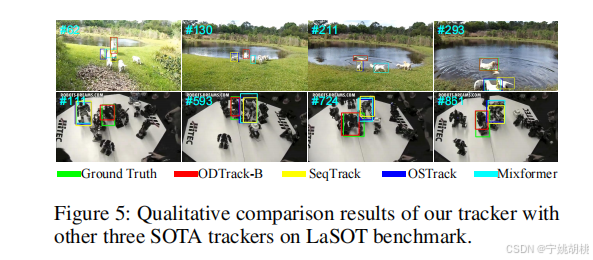
在LaSOT数据集上可视化ODTrack和三个先进的跟踪器的跟踪结果。由于其能够密集传播目标的轨迹信息,在这些序列上ODTrack远胜于最新的跟踪器SeqTrack。
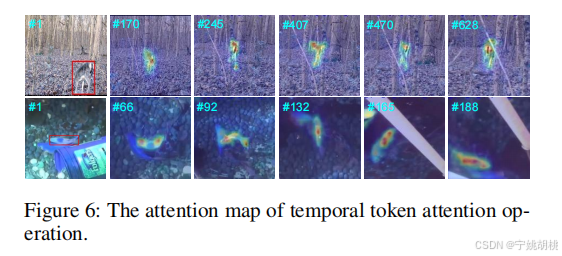
此外,可视化了时间令牌注意力操作的注意力图。可以观察到时间标记不断地传播并关注物体的运动轨迹信息,这有助于跟踪器准确地定位目标实例。
评论记录:
回复评论: