
1.论文阅读与理解
论文实现了一种完全自主的探索系统,用于在无需人工控制或环境先验信息的情况下导航至全局目标。从机器人的紧邻区域提取兴趣点,对其进行评估,并选择其中一个作为路径点。路径点引导基于深度强化学习的运动策略朝向全局目标,从而减轻局部最优解问题。然后基于该策略执行运动,而无需对周围环境进行完全映射。
1.设计了用于目标驱动探索的全局导航和路径点选择策略
2.开发了基于TD3架构的移动机器人导航神经网络。
3.将深度强化学习运动策略与全局导航策略相结合,以减轻未知环境探索中的局部最优问题,并进行了广泛的实验来验证所提出的方法。
为了在未知的环境中实现自主导航和探索,我们提出了一种导航结构,该结构由两部分组成:从兴趣点中选择最优路径点并进行映射的全局导航;基于深度强化学习的局部导航。从环境中提取兴趣点,并根据评估标准选择最优路径点。在每一步中,路径点以相对于机器人位置和航向的极坐标形式提供给神经网络。根据传感器数据计算动作,并朝向路径点执行。在朝着全局目标在路径点之间移动的同时进行地图绘制。
1.1全局导航
为了使机器人朝着全局目标导航,需要从可用的兴趣点中选择用于局部导航的中间路径点。由于没有关于环境的初始信息,无法计算最优路径。因此,机器人不仅需要被引导向目的地,还需要在沿途探索环境,以便在遇到死胡同时识别可能的替代路线。由于没有先验信息,可能的兴趣点需要从机器人的紧邻周围获取并存储在内存中。
我们实现了两种获取新兴趣点的方法:
如果两个连续激光读数之间的差值大于阈值,则添加一个兴趣点,这使得机器人能够通过假定的间隙进行导航。
由于激光传感器具有最大量程,超出此量程的读数将返回为非数值类型,表示环境中的自由空间。如果连续激光读数返回非数值,则在环境中放置一个兴趣点
- 从环境中提取POI。蓝色的圆圈表示用各自的方法提取的POI。绿色的圆圈表示当前的路径点。(a)蓝色POI是由激光读数之间的间隙获得的。从非数值激光读数中提取的(b)蓝色POI
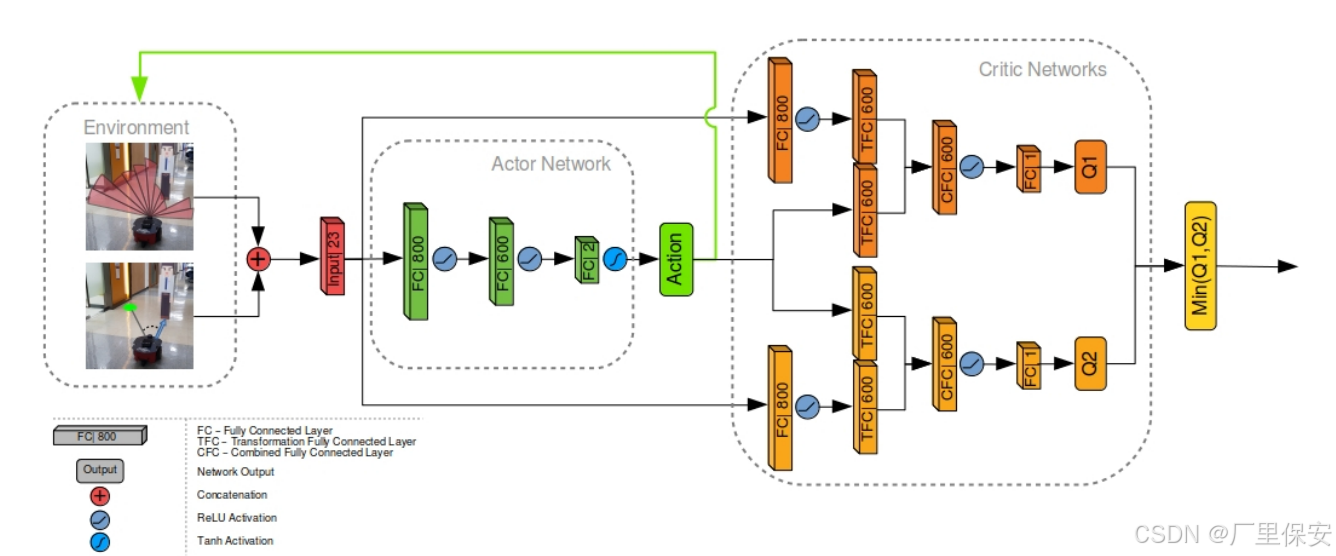
TD3 网络结构,包括行动者(actor)和评论家(critic)部分。各层内描述了层类型及其各自的参数数量。TFC 层指转换全连接层,CFC 层指组合全连接层 Lc 。
如果在后续步骤中发现任何兴趣点位于障碍物附近,则将其从内存中删除。机器人已经访问过的地方不会从激光读数中获取兴趣点。此外,如果一个兴趣点被选为路径点,但经过多个步骤仍无法到达,则将其删除并选择一个新的路径点。
TD3 是一种类似于 DDPG 的演员-评论家类型的网络。这意味着有一个 “actor” 网络来计算要执行的作,而 “critic” 网络则估计这个作有多好。简单来说,TD3 架构是 DDPG 架构的延伸,解决了高估 Q 值的问题。它通过在循环中引入第二个 critic 网络并从产生较低 Q 值估计的 critic 网络中选择输出来实现此目的。因此,我们需要创建一个 actor 网络,将环境状态作为机器人要采取的输入和输出作。此外,我们需要创建两个批评者网络,它们将环境状态以及参与者网络中的动作作为输入,并输出这个状态-动作对的估计值。
actor网络
要创建一个 actor 模型,我们只需要创建一个解码器,它将 state input 映射到 action。

我们创建一个 actor 类,它由 3 个线性、完全连接的层组成。在类初始化中,我们定义将在 forward pass 中使用的层。第一层的输入将是一个单维向量,表示环境状态为 state_dim。我们将这个状态嵌入 800 个参数。由于各层将按顺序调用,因此我们必须确保前一层中的参数数量与下一层中的参数数量相同。因此,下一层输入需要相同数量的 800 个参数。然后我们会将它们映射到 600 个参数。在最后一层中,我们将 600 个参数直接映射到机器人action_dim将具有的可控动作数量。在我们的例子中,我们将控制一个地面移动机器人,该机器人将具有可控的线速度和角速度。由于我们的机器人具有有限的最大和最小可能速度,因此神经网络的输出需要限制在最小-最大范围内。我们可以通过定义 Tanh 激活函数来实现这一点。Tanh 函数将输出限制在 -1, 1 范围内。
在前向传递中,我们定义序列、层的调用方式以及值如何通过它传播。首先,我们调用第一个定义的层,对其应用 ReLU 激活,然后对第二个层执行相同的作。之后,我们调用第三个线性层并应用 Tanh 函数以强制输出在 -1, 1 范围内。这个简单的 actor 网络的输出将成为我们机器人的线性速度和角速度的基础。
critic网络
同样,我们将创建一个评论家网络。如前所述,我们需要 2 个批评者来减轻 Q 值高估。幸运的是,这两个 critic 总是同时工作,因此它们可以由单个 critic 类定义。

在这里,Q 值的解码器与我们在 actor 类中看到的解码器非常相似。然而,由于我们需要评估的不是状态,而是行为者对它的反应,我们不仅需要状态信息,还需要来自行为者网络的行动作为我们批评网络的输入。从本质上讲,我们将状态和行动视为批评家网络的不同输入。将状态信息嵌入到单个线性中,分别穿过第二层的状态嵌入和 action 值,将它们组合在一起,得到最后一层的值估计。由于我们将使用单个类创建两个批评者网络,因此我们需要在初始化中定义这些层两次。图层 1、2、3 属于第一个批评者,第 4、5、6 层属于第二个批评者。请注意,图层 2_a 和 4_a 使用输入大小作为action_dim,因为这将是将嵌入作的第一个图层。
在 forward pass 中,我们定义传播将如何发生。首先,只有状态输入通过第一层,并对其应用 ReLU 激活。然后,它通过第二层。同时,动作值也会通过具有相同输出大小的单个层传递。State embedding 和 action 乘以相应第二层的权重。每次乘法将输出具有相同大小且具有 600 个参数的张量。然后可以对这些张量求和,也可以将第二个动作层的偏差添加到它们上。(这种将动作输入注入神经网络的方法在实践中效果很好)之后,我们使用最后一层将这个组合的状态-动作对嵌入映射到 Q 值估计。请注意,这里没有激活函数,因为 Q 值没有最小值或最大值,因此不需要上限。作为输出,我们将获得两个评论家网络的两个 Q 值。
TD3网络
最后,我们可以实施完整的 TD3 网络,它将是我们的演员和评论家网络的组合。我们可以定义一个 TD3 类,并在其中创建我们的 actor 和 critics。
在 TD3 网络中,我们将实现一种称为软更新的东西。每次优化网络参数时,我们只会选择一个数据子集,称为 batch。这意味着每个网络的优化参数都将根据这些样本进行高度调整。然而,这并不意味着我们将为所有可能的情况找到最佳参数。事实上,如果我们直接使用这些优化的参数,我们的学习将非常不稳定,因为每次网络参数都会针对不同的集合进行优化。这就是为什么我们将为每个网络设置一个控制或目标网络的原因。在每个训练周期中,我们将优化我们的基础网络并获得新的参数。然后,我们将向目标网络注入来自基础网络的少量优化参数,并将基础网络重置为具有与新更新的目标网络相同的参数。这样,在每次更新时,目标网络都会在(希望)最佳策略的大致方向上略微推动,同时保持训练过程稳定。这就是为什么在 TD3 类的初始化中,不仅需要调用我们的 actor 和 critic 类,还需要创建 actor_target 和 critic_target 调用。之后,我们加载可能已经为每个类保存的所有参数,并为每个类设置 Adam 优化器。接下来,我们设置最大可能的作值,创建一个写入器来记录我们的数据以进行 Tensorboard 可视化,并在 iter_count中设置训练迭代计数器。
从可用的兴趣点中,使用基于信息的距离受限探索(IDLE)评估方法选择在时间步 t 的最优路径点。IDLE方法通过以下公式评估每个候选兴趣点的适用性
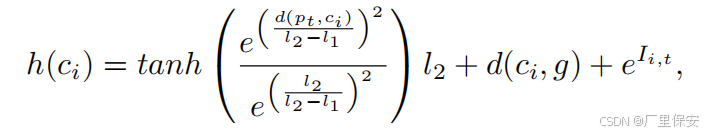
其中每个候选点ci的得分h是三个分量的总和。机器人在时刻t的位置pt与候选点之间的欧几里得距离分量d(pt,ci)表示为双曲正切tanh函数。
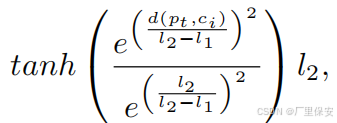
其中e是自然常数,l1和l2是两个步长的距离限制,用于对得分进行折扣。这两个步长距离限制是根据强化学习训练环境的面积大小设置的。第二个分量d(ci,g)表示候选点与全局目标g之间的欧几里得距离。最后,在t时刻的地图信息得分表示为
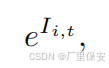
其中Ii,t的计算如下
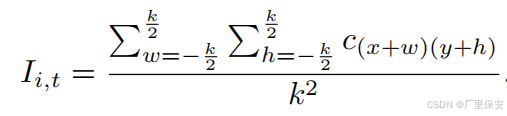
k是用于计算候选点坐标x和y周围信息的内核大小,w和h分别表示内核宽度和高度。
从公式中具有最小IDLE得分的兴趣点被选为局部路径导航的最优路径点。
1.2局部规划
在基于规划的导航栈中,局部运动是根据局部规划器执行的。在我们的方法中,我们用神经网络运动策略取代了这一层。我们使用深度强化学习在模拟环境中单独训练局部导航策略。
使用基于双延迟深度确定性策略梯度(TD3)的神经网络架构来训练运动策略。TD3 是一种行动者 - 评论家网络,允许在连续动作空间中执行动作。局部环境由机器人前方 180° 范围内的激光读数表示。该信息与相对于机器人位置的路径点极坐标相结合。组合后的数据作为 TD3 的行动者网络的输入状态 s。行动者网络由两个全连接(FC)层组成。在每个层之后应用修正线性单元(ReLU)激活函数。最后一层连接到具有两个动作参数 a 的输出层,这两个参数分别表示机器人的线速度 a1和角速度 a2 。在输出层应用 tanh 激活函数,将其限制在(-1, 1)范围内。在环境中应用动作之前,通过最大线速度 Vmax和最大角速度 Wmax 对其进行缩放,如下所示:
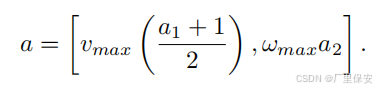
由于激光读数仅记录机器人前方的数据,因此不考虑向后运动,并且线速度被调整为仅为正值。
状态 - 动作对 (Q(s, a) 的 Q 值由两个评论家网络评估。两个评论家网络具有相同的结构,但它们的参数更新是延迟的,以允许参数值的差异。评论家网络将状态 s 和动作 a 作为输入。状态 s 被馈送到一个全连接层,随后是 ReLU 激活,输出为 Ls 。该层的输出以及动作分别被馈送到两个大小相同的转换全连接层(TFC)tau1 和 tau2 。然后,这些层按如下方式组合:
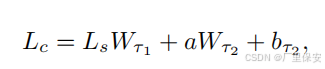
其中 Lc是组合全连接层(CFC),Wtau1 和 Wtau2分别是 tau1 和 tau2的权重,btau2是层 tau2的偏置。然后对组合层应用 ReLU 激活函数。之后,它连接到具有 1 个参数的输出层,表示 Q 值。选择两个评论家网络的最小 Q 值作为最终的评论家输出,以限制对状态 - 动作对值的高估。完整的网络架构如下图所示。
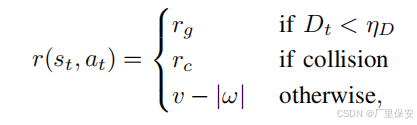
其中,在时间步 t 的状态 - 动作对 st, at 的奖励 r 取决于三个条件。如果当前时间步到目标的距离 Dt 小于阈值 etaD ,则应用正的目标奖励 rg 。如果检测到碰撞,则应用负的碰撞奖励 rc 。如果这两个条件都不满足,则根据当前的线速度 v 和角速度 omega 应用即时奖励。为了引导导航策略朝着给定的目标,采用延迟归因奖励方法,计算如下:
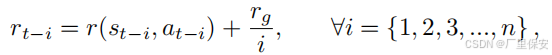
其中 n 是更新奖励的先前步数。这意味着正的目标奖励不仅归因于到达目标时的状态 - 动作对,还在到达目标前的最后 n 步中逐渐分配。网络学习到一种局部导航策略,该策略能够在直接从激光输入中避开障碍物的同时到达局部目标。
1.3探索和映射
机器人沿着路径点被引导向全局目标。一旦机器人接近全局目标,它就会导航至该目标。在这个过程中探索并绘制环境地图。映射使用激光和机器人里程计传感器作为数据源,并获得环境的占用网格地图。带有映射功能的完全自主探索算法的伪代码如算法 1 所示。
2.代码复现
参考链接
ROS+Gazebo强化学习从虚拟训练到实车部署全流程分析_机械臂强化学习gazebo复现-CSDN博客
ROS+Gazebo强化学习导航项目的仿真训练和实车部署:教程及踩过的一些坑 - 知乎
前期准备:
系统:Ubuntu20.04
依赖:anaconda3、ros-noetic、python3.8.10、pytorch1.10、tensorboard
在anaconda下创建包括上述依赖的环境(这里我的环境名称是drl_robot_nav)
开始部署:
新建一个工作空间,这里我的工作空间名为DRL_ROBOT_NAV
mkdir -p DRL_ROBOT_NAV进入工作空间
cd DRL_ROBOT_NAVclone工作项目包
get clone https://github.com/reiniscimurs/DRL-robot-navigation
进入项目空间/进行编译
- cd ~/DRL-robot-navigation/catkin_ws
-
- catkin_make_isolated
在上述过程中可能会遇到各种依赖包的缺失的问题
读者只需按照缺失项下载即可,不会出现依赖包版本之间相互冲突的问题
在这里其实作者也有疑惑,ROS-noetic部署在全局环境中,在项目环境中调用时需要重新下载rospy这个依赖包,也就是说ros并不是一个可以在各种项目环境中直接使用的工具包,但为什么在后续的仿真中可以直接调用roscore和rviz、gazebo呢
还有以前部署ros有关的项目时直接在全局部署,会有一些环境污染的问题,,,,
训练
在训练之前需要现在终端运行以下命令,导出或获取变量,以正常训练。
- export ROS_HOSTNAME=localhost
- export ROS_MASTER_URI=http://localhost:11311
- export ROS_PORT_SIM=11311
- export GAZEBO_RESOURCE_PATH=~/DRL-robot-navigation/catkin_ws/src/multi_robot_scenario/launch
- source ~/.bashrc
进入工作空间
- cd ~/DRL-robot-navigation/catkin_ws
- source devel_isolated/setup.bash
开始训练
- cd ~/DRL-robot-navigation/TD3
- python3 train_velodyne_td3.py
照理说,现在模型就可以开始正常训练了,但是作者在这里遇到了很多问题,比如rviz不能正常显示,小车只能原地打转等等......
更改部分
手动创建launch文件
cd ./DRL-robot-navigation-main/catkin_ws/src/multi_robot_scenario/launch
创建一个新的launch文件,命名为 TD3_world.launch
在其中输入如下内容
- <launch>
- <include file="$(find gazebo_ros)/launch/empty_world.launch">
- <arg name="world_name" value="$(find multi_robot_scenario)/launch/TD3.world"/>
- <arg name="paused" value="false"/>
- <arg name="use_sim_time" value="true"/>
- <arg name="gui" value="true"/>
- <arg name="headless" value="false"/>
- <arg name="debug" value="false"/>
- </include>
- </launch>
打开新终端
- cd DRL-robot-navigation-main/catkin_ws/
- catkin_make
- source devel/setup.sh
- roslaunch multi_robot_scenario TD3_world.launch
这样就打开了gazebo的仿真空间,但是里面还没有小车。
所以我们还需要打开launch文件夹下的pioneer3dx.gazebo.launch文件,则新建一个终端
- cd DRL-robot-navigation-main/catkin_ws/
- source devel/setup.sh
- roslaunch multi_robot_scenario pioneer3dx.gazebo.launch
这样就出现了小车模型
修改velody_env.py文件
将文件中所有的"r1"改为“p3dx”
注释掉文件的98行-113行,但是注意104行初始化节点不要注释
这时候如果开始训练就会发现,小车已经可以在环境中正常训练了,但是新的问题是rviz窗孔不见了,下面来解决这个问题
新建一个终端
- cd ~/DRL_ROBOT_NAV/DRL-robot-navigation-main/catkin_ws/
- source devel/setup.sh
- cd src/multi_robot_scenario/launch
- rviz -d pioneer3dx.rviz
在启动其他窗口之后,再启动rviz就可以发现小车在两个终端都可以正常显示了
自己的一些尝试与思考
笔者在进行仿真的时候遇到的第一个问题就是小车会在撞几次墙之后陷入原地转圈的死循环,通过询问师兄师姐得知这是激励函数设置的太小的原因,撞一次墙reward -100之后小车的策略就会非常保守。所以我在一开始是将奖励函数的负数部分的绝对值调小,让小车的策略更倾向于激进,但是几轮下来尝试了几个数值后结果都不太理想。
所以我又去调整下面的动态避障(局部路径规划)的激励函数
return action[0] / 2 - abs(action[1]) / 2 - r3(min_laser) / 2在这行代码用于计算计算最终的奖励值:action[0] / 2 - abs(action[1]) / 2 - r3(min_laser) / 2。
action[0] / 2:通常 action[0] 表示前进速度,将其除以 2 作为正向奖励的一部分,鼓励智能体前进。
- abs(action[1]) / 2:action[1] 通常表示转向速度,取其绝对值并除以 2 作为负向奖励,用于惩罚不必要的转向,鼓励智能体保持直线前进。
- r3(min_laser) / 2:根据激光传感器检测到的最小距离 min_laser 计算一个负向奖励。如果 min_laser 小于 1,则 r3(min_laser) 不为 0,表示智能体距离障碍物较近,需要给予一定的惩罚;如果 min_laser 大于等于 1,则 r3(min_laser) 为 0,不给予额外的惩罚。
这里笔者将 - abs(action[1]) / 2 改为了- abs(action[1]) / 0.8 ,这样小车的转向倾向就会小很多,让小车倾向于走直线,实测比较好用,在经历一晚的训练之后小车走的路线已经比较正常了。
还有一个问题就是小车容易在进入三角区的时候出现原地不动,然后左右摇摆的情况,目前这个问题笔者还在研究,等后续
评论记录:
回复评论: