
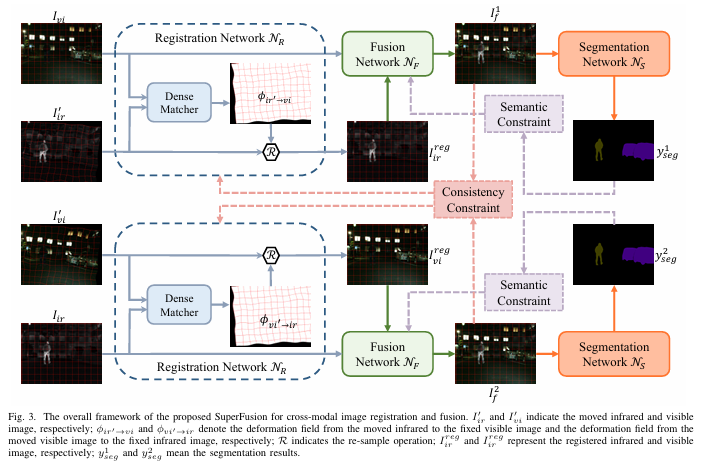
SuperFusion: A Versatile Image Registration and Fusion Network with Semantic Awareness
摘要
图像融合旨在整合源图像中的互补信息,合成综合表征成像场景的融合图像。然而,现有的图像融合算法仅适用于严格对齐的源图像,并且当输入图像有轻微的移位或变形时,会在融合结果中导致严重的伪影。此外,融合结果通常只具有良好的视觉效果,而忽略了高级视觉任务的语义要求。 本研究将图像配准、图像融合和高级视觉任务的语义要求整合到一个框架中,并提出了一种新颖的图像配准和融合方法,称为 SuperFusion。具体来说,我们设计了一个配准网络来估计双向变形场,以在光度和端点约束的监督下纠正输入图像的几何失真。配准和融合以对称方案相结合,其中虽然可以通过优化朴素融合损失来实现相互促进,但通过对对称融合输出的单模态一致约束进一步增强了这种相互促进。此外,图像融合网络配备了全局空间注意力机制,以实现自适应特征融合。此外,部署基于预训练分割模型和Lovasz-Softmax损失的语义约束来引导融合网络更多地关注高级视觉任务的语义要求。关于图像配准、图像融合和语义分割任务的大量实验证明了我们的 SuperFusion 与最先进的替代方案相比的优越性。
模型结构
变形场计算模块DenseMatcher:
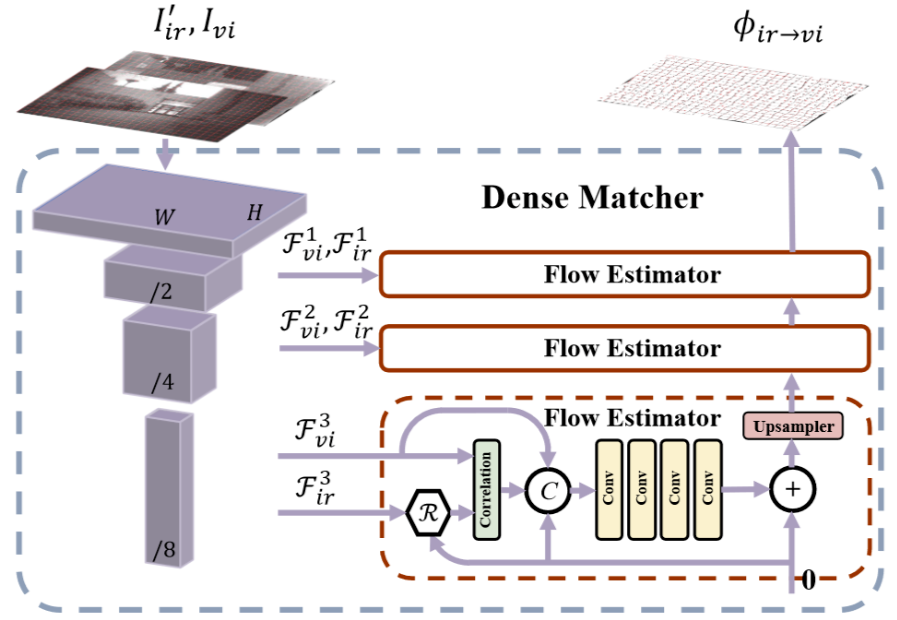
符号R表示变形采样:
I i r r e g = R ( I i r ′ , ϕ i r ′ → v i ) I_{ir}^{reg} = R(I_{ir}',\phi_{ir'\rightarrow vi}) Iirreg=R(Iir′,ϕir′→vi)
Correlation表示:
提取局部块之间的差异性:
def localcorr(self,feat1,feat2):
feat = self.featcompressor(torch.cat([feat1,feat2],dim=1))
b,c,h,w = feat2.shape
feat1_smooth = KF.gaussian_blur2d(feat1,(13,13),(3,3),border_type='constant')
feat1_loc_blk = F.unfold(feat1_smooth,kernel_size=self.corrks,dilation=4,padding=2*(self.corrks-1),stride=1).reshape(b,c,-1,h,w)
localcorr = (feat2.unsqueeze(2)-feat1_loc_blk).pow(2).mean(dim=1)
corr = torch.cat([feat,localcorr],dim=1)
return corr
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
localcorr = (feat2.unsqueeze(2)-feat1_loc_blk).pow(2).mean(dim=1)
通过将 feat2 的形状扩展到 (b, c, 1, h, w),可以进行逐像素的减法操作。feat1_loc_blk 的形状是 (b, c, num_blocks, h, w),其中 num_blocks 是展开后的局部块数量。这里的减法操作会产生一个新的张量,其中每个元素是 feat2 的特征图和 feat1_loc_blk 对应块之间的差值。对差值进行平方,计算均方误差(MSE),这有助于度量 feat2 和 feat1_loc_blk 之间的差异。对每个局部块的差值平方结果在通道维度(dim=1)上取均值,得到每个位置的局部相关性图。最终得到的 localcorr 形状为 (b, num_blocks, h, w)。
Upsampler 映射变形:
#upsample disp and grid
disp2 = F.interpolate(disp2_raw,[feat21.shape[2],feat21.shape[3]],mode='bilinear')
if disp2.shape[2] != self.grid_down.shape[1] or disp2.shape[3] != self.grid_down.shape[2]:
self.grid_down = KU.create_meshgrid(feat21.shape[2],feat21.shape[3]).cuda()
#warp the last src(fea1) to tgt(feat2) with disp2
feat21 = F.grid_sample(feat21,self.grid_down+disp2.permute(0,2,3,1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
feat21 = F.grid_sample(feat21,self.grid_down+disp2.permute(0,2,3,1))
disp2_raw由feat31、feat32的localcorr计算结果经过卷积核高斯模糊得到。使用 F.grid_sample 函数对 feat21 进行变形。F.grid_sample 根据给定的网格坐标 (self.grid_down + disp2) 对特征图进行采样和变形。disp2 在变形之前通过 permute(0, 2, 3, 1) 进行转置,以适应 grid_sample 的要求。这里的变形将 feat21 从源图像映射到目标图像的位置。
融合网络结构:
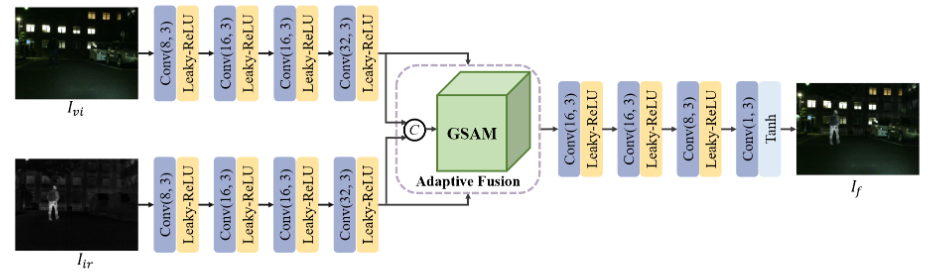
GSAM:
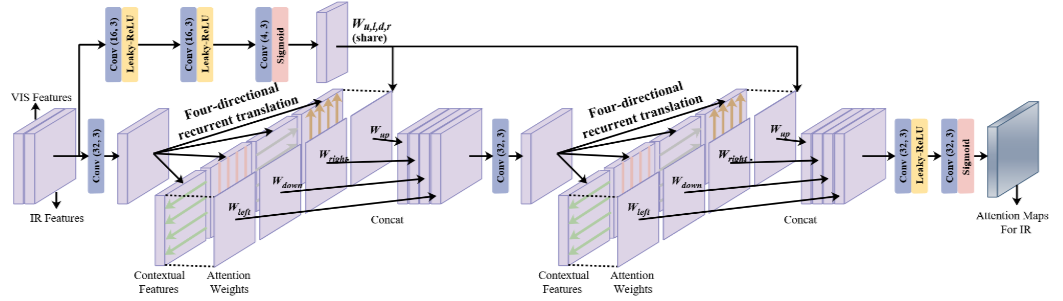
GSAM采用四方向RNN来提取上下文特征,再与注意力权重相乘并级联;通过级联卷积层计算红外特征的融合权重,并将两种特征进行自适应融合。
features_fused = features_ir.mul(attention_ir) + features_vi.mul(1 - attention_ir)
根据注意力图 attention_ir 融合红外特征图 features_ir 和可见光特征图 features_vi。融合的过程基于注意力机制,通过加权来组合两种特征。
损失函数:
图像配准的损失函数:
光度损失: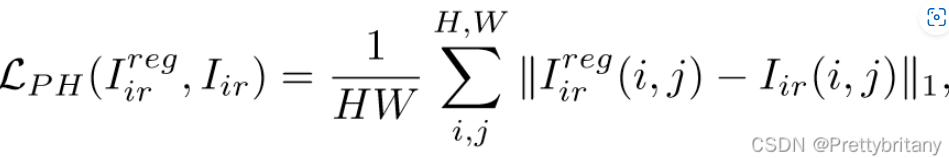
端点损失: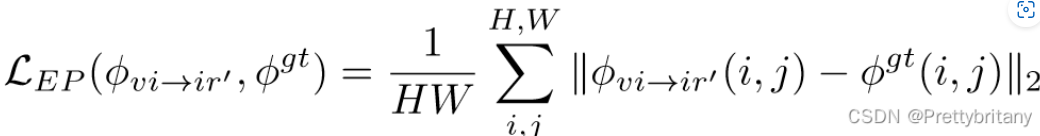
对称损失:
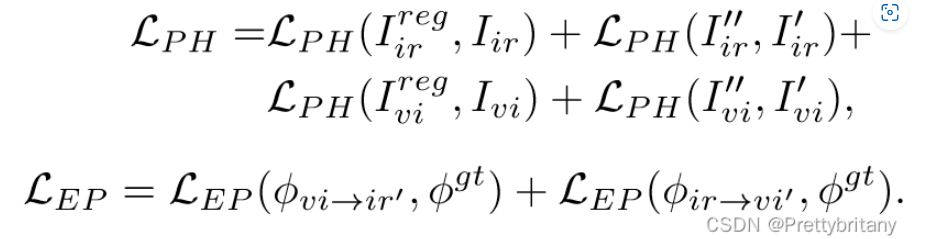
一致性约束损失: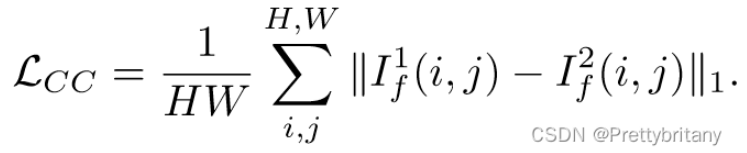
总损失: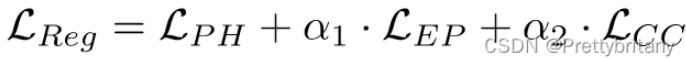
图像融合的损失函数:
SSIM损失(表示结构相似度度量,可以从光线、对比度和结构三个角度度量图像失真):
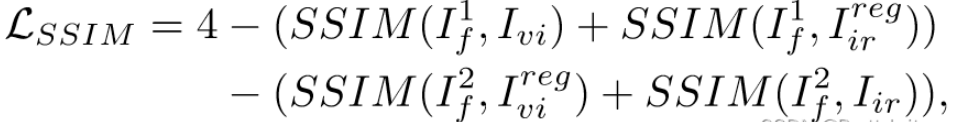
纹理损失(图像的纹理细节可以通过其梯度来表征):
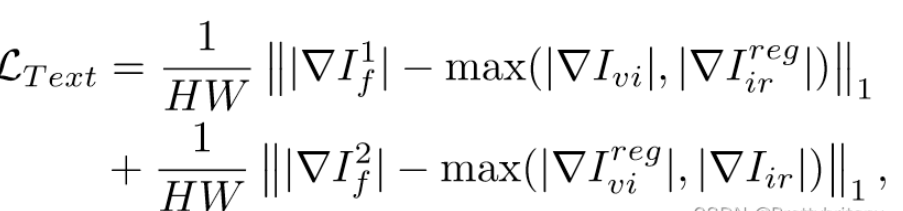
强度损失(融合图像还期望融合源图像中的强度信息,特别是红外图像中的重要目标):
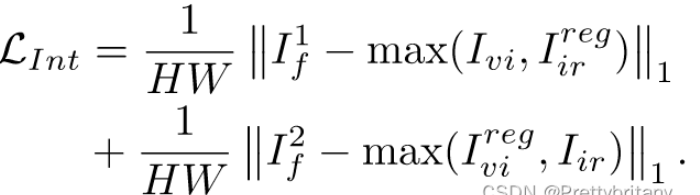
总损失: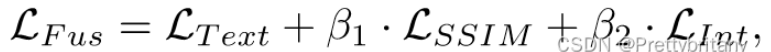
论文结果


复现结果:推理时间偏长,变形场非常容易使图像失真(不仅仅局限于此方法,使用变形场进行配准的都存在这一问题),红外与可见光的偏差越大,越容易出现波纹状失真,将DenseMatcher的特征金字塔层数减少,可以减小这种失真扭曲程度,但是配准效果也会降低。
评论记录:
回复评论: