
目标检测算法之YOLOv5计算预选框、详解anchor计算
- 单节段目标检测算法中:预选框的设定直接影响最终的检测精度
- 众所周知,yolov5中采用自适应调整预选框anchor的大小,但万事开头难,配置文件config中的预设还是很重要
- yolo算法作为one-stage领域的佼佼者,采用anchor-based的方法进行目标检测,使用不同尺度的anchor直接回归目标框并一次性输出目标框的位置和类别置信度。
- 下边根据最近的调研做出这块的一个详细总结:
1.YOLOv5网络结构
- yolov5中使用的coco数据集输入图片的尺寸为
640x640,但是训练过程的输入尺寸并不唯一,因为v5可以采用masaic增强技术把4张图片的部分组成了一张尺寸一定的输入图片。但是如果需要使用预训练权重,最好将输入图片尺寸调整到与作者相同的尺寸,而且输入图片尺寸必须是32的倍数,这与下面anchor检测的阶段有关。
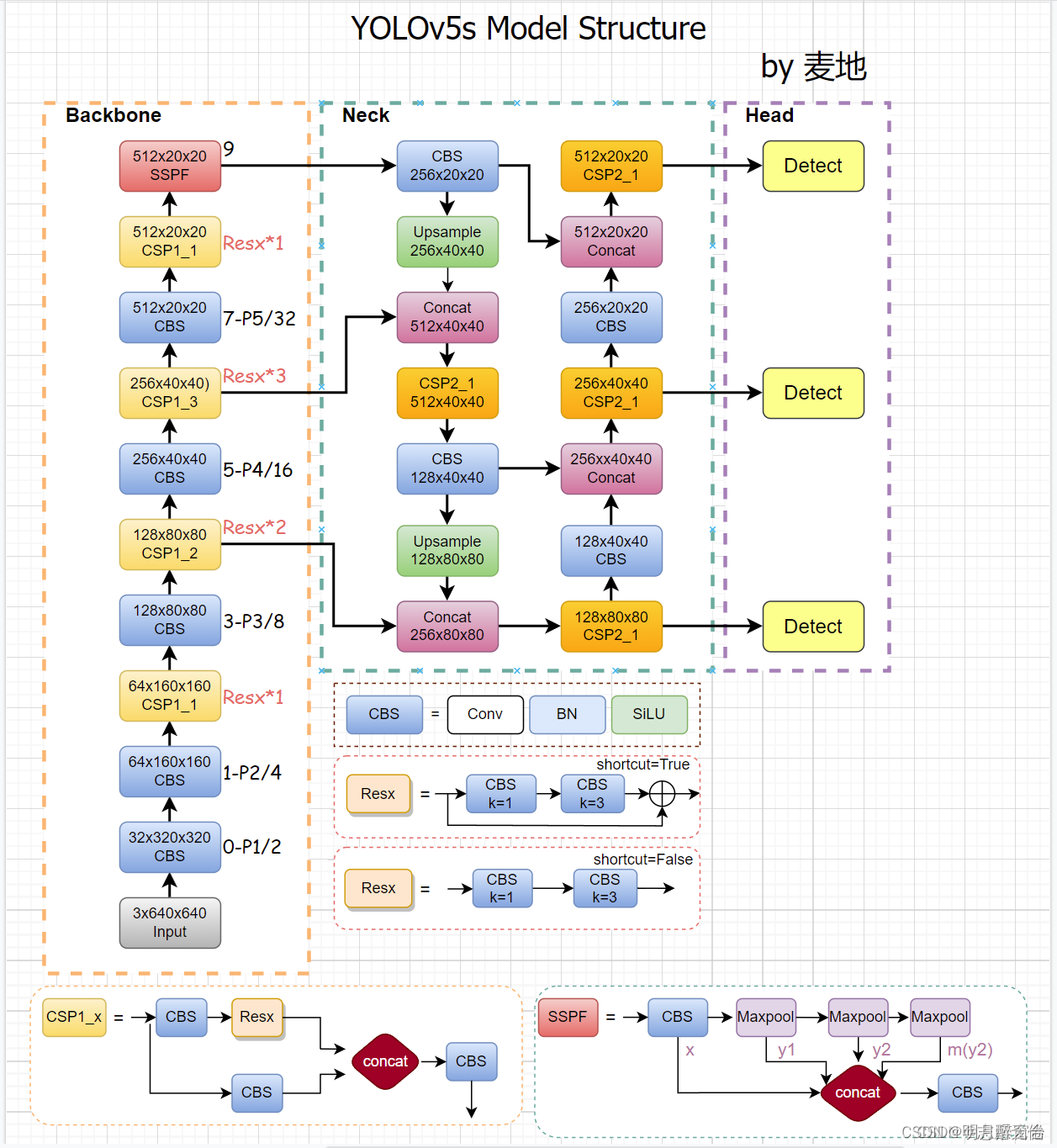
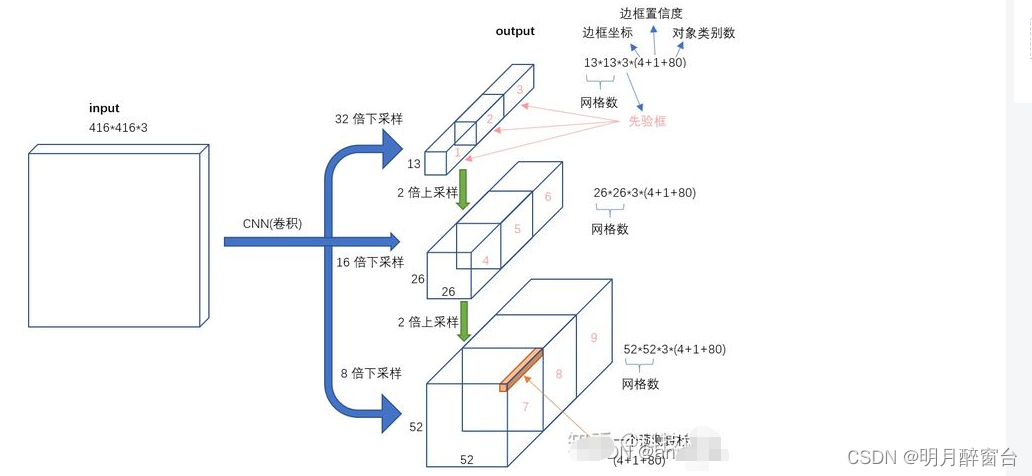
- 当我们的输入尺寸为640*640时,会得到3个不同尺度的输出:80x80(640/8)、40x40(640/16)、20x20(640/32),即上图中的CSP2_3模块的输出。
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
- 1
- 2
- 3
- 4
-
anchors参数共有三行,每行9个数值;且每一行代表应用不同的特征图:
-
在目标检测任务中,一般希望在大的特征图上去检测小目标,因为大特征图才含有更多小目标信息,因此大特征图上的anchor数值通常设置为小数值,而小特征图上数值设置为大数值检测大的目标,yolov5之所以能高效快速地检测跨尺度目标,这种对不同特征图使用不同尺度的anchor的思想功不可没。
-
以上就是yolov5中的anchors的具体解释。
2. 训练时自动计算anchor
-
yolov5 中不是只使用默认锚定框,在开始训练之前会对数据集中标注信息进行核查,计算此数据集标注信息针对默认锚定框的最佳召回率,当最佳召回率大于或等于0.98,则不需要更新锚定框;如果最佳召回率小于0.98,则需要重新计算符合此数据集的锚定框。
-
核查锚定框是否适合要求的函数在 /utils/autoanchor.py 文件中:
def check_anchors(dataset, model, thr=4.0, imgsz=640):
#其中 thr 是指 数据集中标注框宽高比最大阈值,默认是使用 超参文件 hyp.scratch.yaml 中的 “anchor_t” 参数值。
- 1
- 2
- 核查主要代码如下:
def metric(k): # compute metric
r = wh[:, None] / k[None]
x = torch.min(r, 1. / r).min(2)[0] # ratio metric
best = x.max(1)[0] # best_x
aat = (x > 1. / thr).float().sum(1).mean() # anchors above threshold
bpr = (best > 1. / thr).float().mean() # best possible recall
return bpr, aat
bpr, aat = metric(m.anchor_grid.clone().cpu().view(-1, 2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
其中:
bpr(best possible recall)
aat(anchors above threshold)
其中 bpr 参数就是判断是否需要重新计算锚定框的依据(是否小于 0.98)。
- 重新计算符合此数据集标注框的锚定框,是利用
kmean聚类方法实现的,代码在/utils/autoanchor.py文件中:
def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
""" Creates kmeans-evolved anchors from training dataset
Arguments:
dataset: path to data.yaml, or a loaded dataset
n: number of anchors
img_size: image size used for training
thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
gen: generations to evolve anchors using genetic algorithm
verbose: print all results
Return:
k: kmeans evolved anchors
Usage:
from utils.autoanchor import *; _ = kmean_anchors()
"""
from scipy.cluster.vq import kmeans
npr = np.random
thr = 1 / thr
def metric(k, wh): # compute metrics
r = wh[:, None] / k[None]
x = torch.min(r, 1 / r).min(2)[0] # ratio metric
# x = wh_iou(wh, torch.tensor(k)) # iou metric
return x, x.max(1)[0] # x, best_x
def anchor_fitness(k): # mutation fitness
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
return (best * (best > thr).float()).mean() # fitness
def print_results(k, verbose=True):
k = k[np.argsort(k.prod(1))] # sort small to large
x, best = metric(k, wh0)
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
s = f'{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n' \
f'{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, ' \
f'past_thr={x[x > thr].mean():.3f}-mean: '
for x in k:
s += '%i,%i, ' % (round(x[0]), round(x[1]))
if verbose:
LOGGER.info(s[:-2])
return k
if isinstance(dataset, str): # *.yaml file
with open(dataset, errors='ignore') as f:
data_dict = yaml.safe_load(f) # model dict
from utils.dataloaders import LoadImagesAndLabels
dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
# Get label wh
shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
# Filter
i = (wh0 < 3.0).any(1).sum()
if i:
LOGGER.info(f'{PREFIX}WARNING: Extremely small objects found: {i} of {len(wh0)} labels are < 3 pixels in size')
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
# wh = wh * (npr.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
# Kmeans init
try:
LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...')
assert n <= len(wh) # apply overdetermined constraint
s = wh.std(0) # sigmas for whitening
k = kmeans(wh / s, n, iter=30)[0] * s # points
assert n == len(k) # kmeans may return fewer points than requested if wh is insufficient or too similar
except Exception:
LOGGER.warning(f'{PREFIX}WARNING: switching strategies from kmeans to random init')
k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random init
wh, wh0 = (torch.tensor(x, dtype=torch.float32) for x in (wh, wh0))
k = print_results(k, verbose=False)
# Plot
# k, d = [None] * 20, [None] * 20
# for i in tqdm(range(1, 21)):
# k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
# fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
# ax = ax.ravel()
# ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
# fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
# ax[0].hist(wh[wh[:, 0]<100, 0],400)
# ax[1].hist(wh[wh[:, 1]<100, 1],400)
# fig.savefig('wh.png', dpi=200)
# Evolve
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
pbar = tqdm(range(gen), bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
for _ in pbar:
v = np.ones(sh)
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
kg = (k.copy() * v).clip(min=2.0)
fg = anchor_fitness(kg)
if fg > f:
f, k = fg, kg.copy()
pbar.desc = f'{PREFIX}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
if verbose:
print_results(k, verbose)
return print_results(k)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
对 kmean_anchors()函数中的参数做一下简单解释(代码中已经有了英文注释):
- path:包含数据集文件路径等相关信息的 yaml 文件(比如 coco128.yaml), 或者 数据集张量(yolov5 自动计算锚定框时就是用的这种方式,先把数据集标签信息读取再处理) n:锚定框的数量,即有几组;默认值是9
- img_size:图像尺寸。计算数据集样本标签框的宽高比时,是需要缩放到 img_size 大小后再计算的;默认值是640
- thr:数据集中标注框宽高比最大阈值,默认是使用 超参文件 hyp.scratch.yaml 中的 “anchor_t”参数值;默认值是4.0;自动计算时,会自动根据你所使用的数据集,来计算合适的阈值。 gen:kmean聚类算法迭代次数,默认值是1000
- verbose:是否打印输出所有计算结果,默认值是true
- 如果你不想自动计算锚定框,可以在 train.py 中设置参数即可:
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
- 1
3. 训练前手动计算anchor
-
- 修改./data/xxx.yaml文件:将训练数据路径设为绝对路径
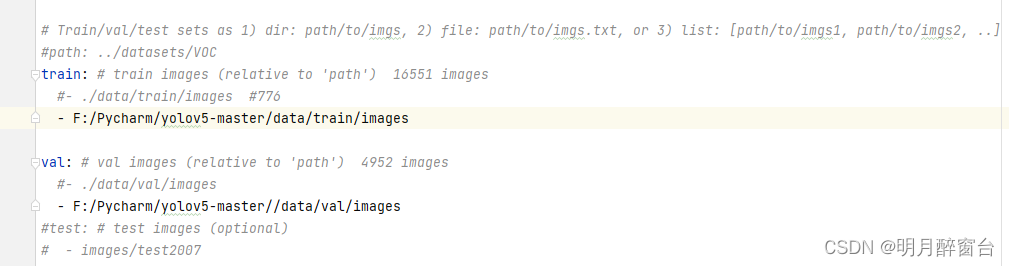
- 修改./data/xxx.yaml文件:将训练数据路径设为绝对路径
-
数据集下需包含
.cache文件:
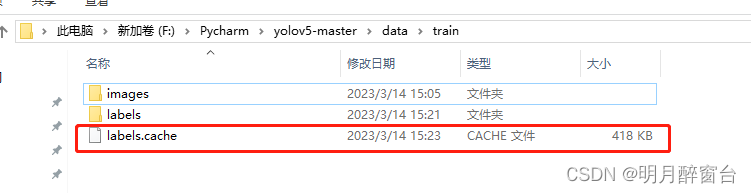
-
- 调用kmeans算法计算
anchor:
- 调用kmeans算法计算
from utils.autoanchor import *
config="../data/xxx.yaml"
_=kmean_anchors(config)
- 1
- 2
- 3
- 4
- 5
输出如下:

- 将最后计算得出的值按顺序修改至模型配置文件
./model/xxx.yaml中,重新训练即可:

4. 检测模块
-
接下来就是anchor在模型中的应用了。这就涉及到了yolo系列目标框回归的过程了。yolov5中的detect模块沿用了v3检测方式,这里就用这种方式来阐述了。
-
- 检测到的不是框,是偏移量:
tx,ty指的是针对所在grid的左上角坐标的偏移量, tw,th指的是相对于anchor的宽高的偏移量,通过如下图的计算方式,得到bx,by,bw,bh就是最终的检测结果。
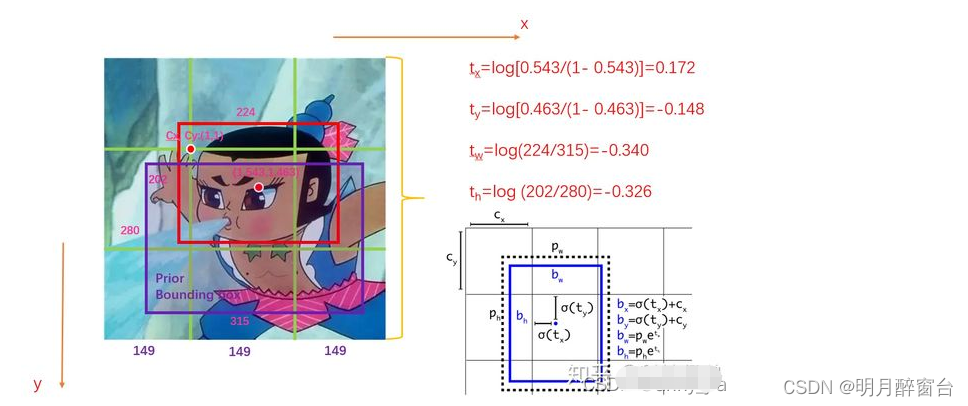
- 检测到的不是框,是偏移量:
-
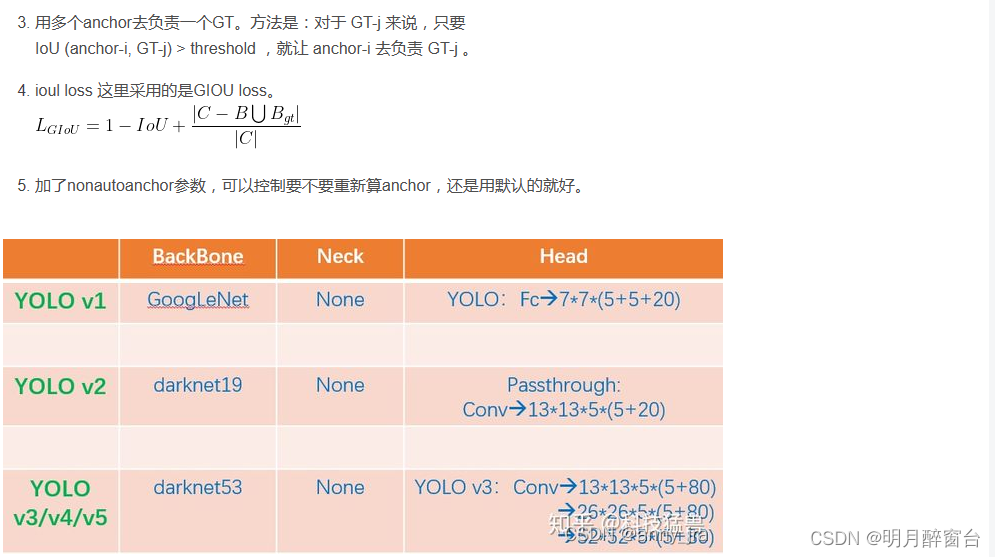
- 前面经过backbone,neck, head是panet的三个分支,可见特征图size不同,每个特征图分了13个网格,同一尺度的特征图对应了3个anchor,检测了[c,x,y,w,h]和num_class个的one-hot类别标签。3个尺度的特征图,总共就有9个anchor。
参考
深研视觉算法.cpp.m.py
 QQ名片
QQ名片
QQ名片

评论记录:
回复评论: