

嘿,各位编程爱好者们!今天带来的 LIS 算法简直太赞啦 无论你是刚入门的小白,还是经验丰富的大神,都能从这里找到算法的奇妙之处哦!这里不仅有清晰易懂的 C++ 代码实现,还有超详细的算法讲解,让你轻松掌握 LIS 算法的三种解法:暴力、动态规划、贪心加二分查找,彻底搞懂它在数据处理、资源分配和文本处理中的强大应用呢 看完保证让你收获满满,记得点赞,收藏三连,关注我,后续还有更多精彩的算法干货分享哦 让我们一起开启算法的奇妙之旅,提升编程技能,征服代码世界吧!
欢迎拜访:羑悻的小杀马特.-CSDN博客本篇主题:
剖析所谓的LIS算法(C++版)制作日期:2025.01.03
隶属专栏:美妙的算法世界


目录
本篇简介:
本篇以LIS算法展开细致介绍,不同方法的实现如动态规划,贪心二分实现等;并配合实际例题进行应用;望对读者学习LIS算法有帮助。
一·LIS算法:
1.1算法定义及目的:
LIS(Longest Increasing Subsequence)算法,即最长递增子序列算法。
它的目标是在一个给定的序列(可以是数字序列、字符序列等)中,找到一个子序列,这个子序列中的元素是按照递增顺序排列的,并且在所有符合递增条件的子序列中,长度是最长的。
例如,在序列 [1, 3, 2, 4, 5] 中,最长递增子序列是 [1, 2, 4, 5],长度为 4。这个算法在很多领域都有应用,比如数据挖掘中分析数据的趋势,或者在文本处理中分析文本的某种递增模式。
1.2实现方法:
1.2.1简单的暴力解法:
又称枚举法;下面说一下它的思路:
这种方法是最直观的。它会枚举所有可能的子序列,然后检查每个子序列是否是递增的,并记录下最长的递增子序列。
具体来说,对于一个长度为 n 的序列,它有 2^n 个子序列,需要逐个检查这些子序列是否满足递增条件。
但是它有个致命的缺点:
时间复杂度非常高,达到了指数级别 O (2^n)。在实际应用中,当序列长度稍微变大时,计算量会变得极其庞大,效率极低。例如,当 n = 20 时,2^20 约等于 100 万次运算,这会导致程序运行时间过长。
代码实现:
- // 暴力解法
- int lis_brute_force(const std::vector<int>& nums) {
- int n = nums.size();
- int max_length = 0;
- // 枚举所有可能的子序列
- for (int mask = 0; mask < (1 << n); ++mask) {
- std::vector<int> subseq;
- for (int i = 0; i < n; ++i) {
- if (mask & (1 << i)) {
- subseq.push_back(nums[i]);
- }
- }
- bool is_increasing = true;
- for (size_t i = 1; i < subseq.size(); ++i) {
- if (subseq[i] <= subseq[i - 1]) {
- is_increasing = false;
- break;
- }
- }
- if (is_increasing) {
- max_length = std::max(max_length, static_cast<int>(subseq.size()));
- }
- }
- return max_length;
- }

代码解释:
使用位运算枚举所有可能的子序列。
mask从 0 到(1 << n) - 1,对于每个mask,将对应位为 1 的元素添加到subseq向量中。检查
subseq是否是递增序列,如果是,更新max_length。时间复杂度为 o(2^n),效率低,适合较短序列。
因此我们极大不推荐这种解法。
1.2.2动态规划解法:
原理:
1.2.2.1从左往右填表:
动态规划的核心思想是将一个复杂的问题分解为一系列相互关联的子问题,并通过记录子问题的解来避免重复计算。
对于 LIS 算法,我们定义一个状态数组 dp,
其中 dp [i] 表示以第 i 个元素结尾的最长递增子序列的长度。
状态转移方程:
dp [i]=max (dp [j]) + 1,其中 j < i 且 nums [j]
这意味着要找到在 i 之前的元素 j,使得 nums [j] 小于 nums [i],并且 dp [j] 是最大的,然后将 dp [i] 更新为 dp [j]+1。
时间复杂度分析:
时间复杂度为 O (n^2),相比于暴力解法有了很大的提升。
例如,对于长度为 100 的序列,暴力解法可能需要计算 2^100 次左右,而动态规划只需要计算 100^2 = 10000 次左右,大大减少了计算量。
代码实现:
首先,定义完了dp状态,先明确我们的任务:即从这这段数组中(其实是参差不齐),但是我们忽略降序的数,只从升序的那条路看起,找最长的。
比如我们到了i位置,想要得到的是? 以i位置为结尾的最长(包括i位置);因此我们需要在i之前找一条升序最长路L(末尾元素一定要比i小)--->这里正好就是我们的dp[j](j是由0~i-1);因此我们只需要遍历得到以j为结尾的dp的最大值就好;如果是结尾元素值比我们标定i对应值大;那么这个j就不能作为L的结尾元素;直接else跳过。
故,上面所说的我们最后是遍历得到L然后再+1得到dp[i];因此我们让它更加贴近一下dp状态方程的写法-->下面我们只用维护L+1(dp[i])的最大值即可了
- int lis_dp(const std::vector<int>& nums) {
- int n = nums.size();
- std::vector<int> dp(n, 1);
- int max_length = 1;
- for (int i = 1; i < n; ++i) {
- for (int j = 0; j < i; ++j) {
- if (nums[i] > nums[j]) {
- // 状态转移方程 dp[i] = max(dp[i], dp[j] + 1)
- dp[i] = std::max(dp[i], dp[j] + 1);
- }
- }
- max_length = std::max(max_length, dp[i]);
- }
- return max_length;
- }
代码解释:
使用
dp数组存储以每个元素结尾的最长递增子序列的长度。对于每个元素
i,遍历i之前的元素j,若nums[i] > nums[j],根据状态转移方程dp[i] = std::max(dp[i], dp[j] + 1)更新dp[i]。最终
max_length存储了最长递增子序列的长度,时间复杂度为 。
1.2.2.2从右向左填表:
这里还可以是dp[i]表示以第i个元素为开始的 最长递增子序列的长度;这里只不过就是和上面的填表顺序颠倒一下。
代码展示:
这里的实现思路其实大差不多;我们只是定义的dp状态不同;只是所谓的推导从前变成了后了;
i为开始元素:因此我们要找的是i的右侧的大于i位置值的升序最长路L;因此从i+1开始看(必须要包含i+1为起点的最大路L)【->故我们是当填充i从i右侧找;因此这个是逆向填表(从右往左填表)】;注:遍历时,这里我们符合的要求(L)首先是j位置的值一定要大于i位置;其次就是找最长;因此遍历到长的L;因此我们为了让它像dp状态方程写法,故每次是求L+1作为dp[i]暂定值,然后求个max。
- int LIS(vector<int> d) {
- int maxn = 1;
- vector<int> dp(d.size(),1);
- for (int i = d.size() - 2; i >= 0; i--) {
- for (int j = i + 1; j < d.size(); j++) {
- if (d[i] < d[j]) dp[i] = max(dp[i],dp[j] + 1);
- }
- maxn = max(dp[i],maxn);
- }
- return maxn;
- }
这两种定义方法都可以。
1.2.3贪心算法 + 二分查找解法:
贪心思想引入:
贪心算法的策略是在每一步都做出当前看起来最优的选择。对于 LIS 算法,我们维护一个辅助数组 tail,它存储了当前找到的最长递增子序列。当扫描到一个新元素时,我们尽量将它插入到 tail 数组中合适的位置,使得 tail 数组仍然保持递增。
二分查找:
为了高效地将新元素插入到 tail 数组中,我们使用二分查找。每次插入元素时,在 tail 数组中找到第一个大于等于新元素的位置,然后用新元素替换它。这样可以保证 tail 数组始终是递增的,并且长度尽可能长。
时间复杂度:
这种方法的时间复杂度可以达到 O (nlogn),这是一种比较高效的解法。例如,对于长度为 1000 的序列,其计算量比动态规划的 O (n^2) 解法又减少了很多,能够更快地得到结果。
代码实现:
- int lis_greedy(const std::vector<int>& nums) {
- std::vector<int> tail;
- for (int num : nums) {
- auto it = std::lower_bound(tail.begin(), tail.end(), num);
- if (it == tail.end()) {
- tail.push_back(num);
- } else {
- *it = num;
- }
- }
- return tail.size();
- }
代码解释:
维护
tail向量存储当前找到的最长递增子序列。对于每个元素
num,使用std::lower_bound找到tail中第一个大于等于num的位置。如果
it等于tail.end(),说明num比tail中所有元素都大,添加到tail末尾;否则,将tail中it位置的元素更新为num。时间复杂度为 o(nlogn),是最有效的实现方式
这种也是比较推荐的!!!
2·算法应用场景:
2.1数据分析与挖掘:
在分析数据的趋势变化时,LIS 算法可以帮助找到数据中的上升趋势部分,例如股票价格的上涨阶段、气温的上升周期等。
2.2资源分配优化:
在任务调度或者资源分配场景中,如果任务有先后顺序要求或者资源有递增的利用顺序,LIS 算法可以辅助找到最优的分配方案。
2.3文本处理:
在文本编辑软件中,用于分析文本段落中句子的长度递增模式,或者单词的某种语义递增模式,辅助进行文本排版或者语义分析。
二·LIS算法例题:
下面我们就用一道例题,来应用上面所述的LIS算法解答吧:

测试用例:
输入:6 1 4 2 2 5 6
输出:4
题目链接: 蓝桥账户中心
首先我们先看数据范围:
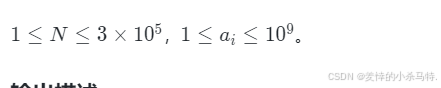
这里我们由题意可以看出:

总结下:就是当选了大的数值后就无法在选择比它小的数值;因此我们可以 选择把它排好升序,但是此时要注意符合刚才说的要求即可,这时就联想到了LIS算法了,但是前两种即暴力,动态规划实现是不合适的(大数据范围),因此后面我们就用贪心+二分来实现。
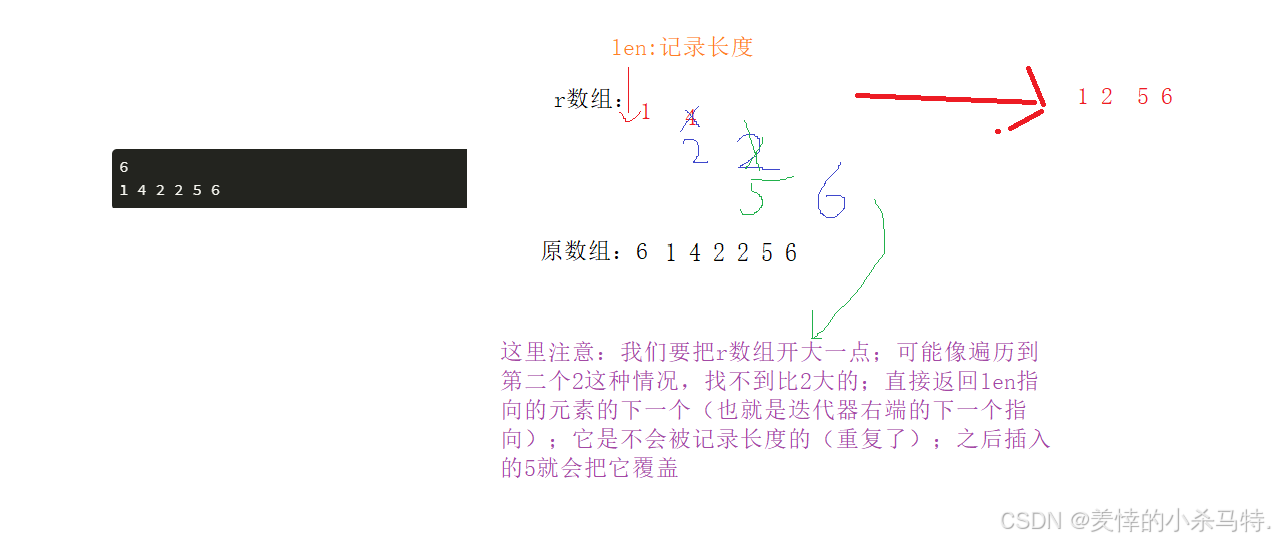
这里也就是要求我们要是升序,并且不能重复 (去重复:1·利用lower_bound的特性找到相同的会覆盖掉,2·当发现找不到返回的是区间最后+1位置的迭代器也是会覆盖,不记录len(如上图的情况))。
因此直接上手代码:
- #include <bits/stdc++.h>
- using namespace std;
- const int N=3e5+5;
- int r[N]={0};
- int main()
- { //最长递增子序列问题(贴近):lis
- int n;
- cin>>n;
- vector<int>v(n+1);
- for(int i=1;i<=n;i++) cin>>v[i];
- int len=0;//r答案数组的长度:确保r数组始终是升序的
- //(不是一般的sort类的升序,而是确保了在r数组中出现的升序元素相对位置符合原数组的相对位置)
- for(int i=1;i<=n;i++){
- if(v[i]>r[len]) r[++len]=v[i];//比它大直接放在后面(多可以个0位置,方便比较)
- else {
- //返回大于它的数完成覆盖:
- //找不到也就是r数组存在于当前值第一大的值,放在len后面的位置,之后会覆盖(相当于相等的数据就是无效的)
- // int pos=lower_bound(r+1,r+len+1,v[i])-r;
- // r[pos]=v[i];
-
- //或者
- *lower_bound(r+1,r+len+1,v[i])=v[i];
-
- }
- }
- cout<<len;
- return 0;
- }
这道题也是不n能用o(N^2)复杂度的动态规划局解法;故就用复杂度为o(nlogn)的贪心二分来解决。
最后也是通过了。
三·本篇小结:
本篇介绍了LIS算法;下面介绍一下具体怎么用来小结一下:
当我们发现要求的是最长地址子序列,就可以选择它;具体有三种情况;但是合适的要么就动归,要么就二分;根据数据范围选择即可了。
如果我们只要这个序列的长度:两种都可。
但是,如果是还要它的数据那么就只能选二分来模拟了。
二分的话,就要保证:
在lis数组中出现的升序元素相对位置符合原数组的相对位置。
评论记录:
回复评论: