

引言
在机器学习和统计学领域,许多实际问题涉及到含有隐变量的概率模型。例如,在图像识别中,图像的语义信息往往是隐变量,而我们能观测到的只是图像的像素值;在语音识别中,语音对应的文本内容是隐变量,观测数据则是语音信号。期望最大化(Expectation-Maximization,简称 EM)算法作为一种强大的迭代算法,专门用于处理这类含有隐变量的模型,通过巧妙的方式来估计模型参数,在众多领域发挥着不可或缺的作用。
本文将从 EM 算法的基本原理出发,逐步深入探讨其数学基础、应用场景、优化策略以及与其他算法的对比。通过详细的数学公式、代码示例和图解,帮助读者全面理解 EM 算法的核心思想及其在实际问题中的应用。

一. 期望最大化算法基础
1.1 算法定义与核心思想
1.1.1 定义阐述
期望最大化算法是一种在统计建模中用于寻找参数最大似然估计或最大后验估计的迭代方法。在面对包含潜在变量(隐变量)或缺失数据的概率模型时,传统的参数估计方法往往面临困境,而 EM 算法能够巧妙地解决这类问题。
以高斯混合模型为例,数据可能由多个高斯分布混合而成,但我们并不知道每个数据点具体来自哪个高斯分布,这里每个数据点所属的高斯分布类别就是隐变量。EM 算法通过迭代的方式,逐步逼近最优的参数估计值,使得模型能够最佳地拟合观测数据。
1.1.2 核心思想解读
EM 算法的核心在于通过引入隐变量来简化原本复杂的问题,并借助迭代优化的手段逐步提升对数似然函数的值。在实际的参数估计问题中,直接对含有隐变量的模型进行最大似然估计通常是极为困难的。
EM 算法通过引入隐变量,将复杂的问题转化为两个相对简单的步骤:期望(E)步和最大化(M)步。在 E 步中,基于当前的参数估计,计算未观测变量(隐变量)的条件期望值;在 M 步中,利用 E 步得到的期望值,更新模型参数,以实现对数似然函数的最大化。
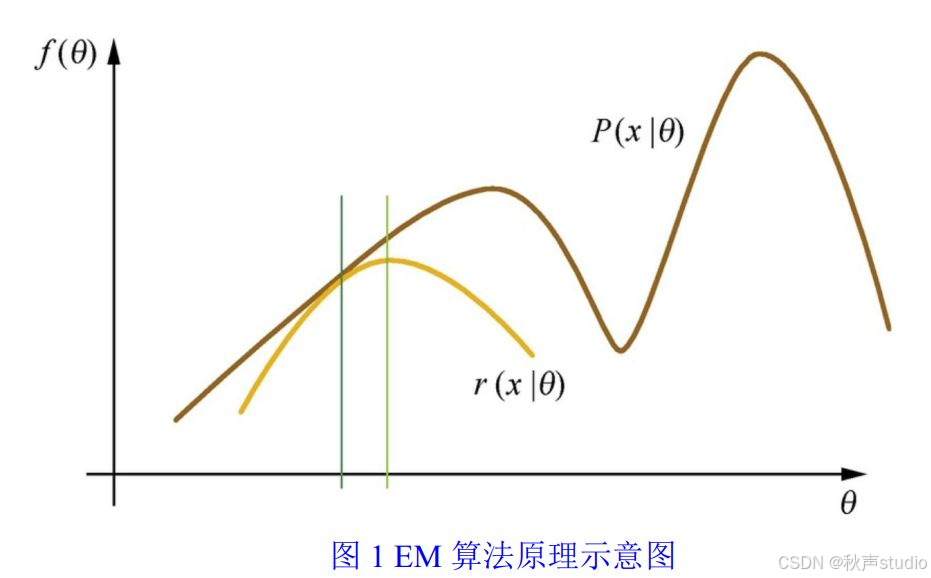
图1:EM算法原理示意图
如上图所示,EM 算法的迭代过程可以看作是在不断优化参数 θ 的过程中,逐步逼近最优解。在每次迭代中,E 步计算隐变量的条件期望,M 步更新模型参数,使得对数似然函数
f
(
θ
)
f(θ)
f(θ) 逐步增大,最终收敛到一个稳定的参数估计值。
1.2 数学基础
1.2.1 条件概率与联合概率
条件概率是指在事件 B 已经发生的条件下,事件 A 发生的概率,记作 P ( A ∣ B ) P(A|B) P(A∣B)。其计算公式为:
P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A|B) = \frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B)
其中 P ( A ∩ B ) P(A \cap B) P(A∩B) 表示事件 A 和事件 B 同时发生的概率,即联合概率。
在期望最大化算法中,条件概率和联合概率有着至关重要的应用。在 E 步中,计算隐变量的条件期望时,需要依据已知的观测数据和当前的参数估计,运用条件概率公式来计算隐变量在不同取值下的概率分布。
1.2.2 似然函数
似然函数是关于统计模型中参数的函数,它表示在给定观测数据的情况下,模型参数的似然性。具体而言,对于一个概率模型,其似然函数 L ( θ ∣ X ) L(\theta|X) L(θ∣X) 描述了在参数 θ \theta θ 下,观测数据 X X X 出现的概率。
在极大似然估计中,我们的目标是寻找一组参数 θ \theta θ,使得似然函数 L ( θ ∣ X ) L(\theta|X) L(θ∣X) 达到最大值。在期望最大化算法中,似然函数同样占据着核心地位。
1.2.3 Kullback-Leibler 散度
Kullback-Leibler 散度(简称 KL 散度)用于衡量两个概率分布 P P P 和 Q Q Q 之间的差异。其定义为:
K L ( P ∣ ∣ Q ) = ∑ P ( x ) log P ( x ) Q ( x ) KL(P||Q) = \sum P(x) \log \frac{P(x)}{Q(x)} KL(P∣∣Q)=∑P(x)logQ(x)P(x)
在期望最大化算法中,KL 散度可用于解释算法的收敛性。在每次迭代中,EM 算法通过 E 步和 M 步的操作,使得当前模型分布与真实数据分布之间的 KL 散度逐渐减小,从而保证了算法能够收敛到一个相对较优的参数估计值。
1.3 算法步骤详解
1.3.1 期望(E)步骤
在期望步骤中,主要任务是在当前参数估计的基础上,计算未观测变量(隐变量)的条件期望值。具体来说,对于给定的观测数据 X X X 和当前的参数估计 θ ( t ) \theta^{(t)} θ(t),我们需要计算隐变量 Z Z Z 在条件 ( X , θ ( t ) ) (X, \theta^{(t)}) (X,θ(t)) 下的期望。
这一步骤通常涉及到计算完整数据的对数似然函数的期望值,即构建一个 Q 函数:
Q ( θ , θ ( t ) ) = E [ log P ( X , Z ∣ θ ) ∣ X , θ ( t ) ] Q(\theta, \theta^{(t)}) = E[\log P(X, Z|\theta)|X, \theta^{(t)}] Q(θ,θ(t))=E[logP(X,Z∣θ)∣X,θ(t)]
其中 P ( X , Z ∣ θ ) P(X, Z|\theta) P(X,Z∣θ) 是观测数据 X X X 和隐变量 Z Z Z 的联合概率分布。
1.3.2 最大化(M)步骤
基于 E 步得到的期望值,最大化步骤的目标是更新模型参数 θ \theta θ,以最大化对数似然函数。在这一步中,我们将 Q 函数作为目标函数进行优化,即寻找一组新的参数 θ ( t + 1 ) \theta^{(t+1)} θ(t+1),使得 Q ( θ , θ ( t ) ) Q(\theta, \theta^{(t)}) Q(θ,θ(t)) 达到最大值。
对于不同的概率模型,最大化 Q 函数的方法各不相同。在高斯混合模型中,对于每个高斯分布,我们需要更新其均值 μ \mu μ、方差 σ 2 \sigma^2 σ2 和权重 π \pi π。
1.3.3 迭代过程
期望最大化算法的迭代过程就是不断交替执行 E 步和 M 步。从初始的参数估计 θ ( 0 ) \theta^{(0)} θ(0) 开始,首先进行 E 步,计算 Q ( θ , θ ( 0 ) ) Q(\theta, \theta^{(0)}) Q(θ,θ(0));然后进行 M 步,得到新的参数估计 θ ( 1 ) \theta^{(1)} θ(1)。接着,以 θ ( 1 ) \theta^{(1)} θ(1) 为基础,再次进行 E 步,计算 Q ( θ , θ ( 1 ) ) Q(\theta, \theta^{(1)}) Q(θ,θ(1)),随后进行 M 步得到 θ ( 2 ) \theta^{(2)} θ(2),如此反复进行。
二. 期望最大化算法的应用领域
2.1 高斯混合模型(GMM)
2.1.1 GMM 原理简介
高斯混合模型是一种将事物分解为若干个基于高斯概率密度函数(正态分布曲线)形成的模型,其基本假设是数据集由多个高斯分布组成。数学上,一个高斯混合模型可表示为多个高斯分布的加权和,即:
p ( x ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(x) = \sum_{k=1}^{K} \pi_k \mathcal{N}(x|\mu_k, \Sigma_k) p(x)=k=1∑KπkN(x∣μk,Σk)
其中, x x x 是数据点, K K K 是高斯分布的个数, π k \pi_k πk 是第 k k k 个高斯分布的权重,且 ∑ k = 1 K π k = 1 \sum_{k=1}^{K} \pi_k = 1 ∑k=1Kπk=1, N ( x ∣ μ k , Σ k ) \mathcal{N}(x|\mu_k, \Sigma_k) N(x∣μk,Σk) 是均值为 μ k \mu_k μk、协方差矩阵为 Σ k \Sigma_k Σk 的高斯分布。
2.1.2 EM 算法在 GMM 中的应用案例
在某客户细分项目中,有一家电商企业收集了大量用户的购买金额和购买频率数据。为了对用户进行细分,企业采用了高斯混合模型结合 EM 算法的方法。首先,假设数据由两个高斯分布混合而成(即 K = 2 K=2 K=2),随机初始化两个高斯分布的均值 μ 1 \mu_1 μ1、 μ 2 \mu_2 μ2,协方差矩阵 Σ 1 \Sigma_1 Σ1、 Σ 2 \Sigma_2 Σ2 以及权重 π 1 \pi_1 π1、 π 2 \pi_2 π2。
在 E 步中,对于每个用户数据点 x i x_i xi,计算其属于每个高斯分布的概率 P ( Z = k ∣ x i , θ ( t ) ) P(Z=k|x_i, \theta^{(t)}) P(Z=k∣xi,θ(t)),其中 Z Z Z 表示数据点所属的高斯分布类别, θ ( t ) \theta^{(t)} θ(t) 是当前的参数估计。这一概率反映了该数据点更有可能来自哪个高斯分布。
在 M 步中,根据 E 步计算得到的概率,更新高斯分布的参数。例如,更新均值的公式为:
μ k = ∑ i = 1 N P ( Z = k ∣ x i , θ ( t ) ) x i ∑ i = 1 N P ( Z = k ∣ x i , θ ( t ) ) \mu_k = \frac{\sum_{i=1}^{N} P(Z=k|x_i, \theta^{(t)}) x_i}{\sum_{i=1}^{N} P(Z=k|x_i, \theta^{(t)})} μk=∑i=1NP(Z=k∣xi,θ(t))∑i=1NP(Z=k∣xi,θ(t))xi
通过不断迭代执行 E 步和 M 步,最终得到了两个较为稳定的高斯分布。其中一个高斯分布的均值较低,方差较小,代表了购买金额和频率都相对较低的普通用户群体;另一个高斯分布的均值较高,方差较大,代表了购买金额较高、购买频率波动较大的优质用户群体。
2.2 隐马尔可夫模型(HMM)
2.2.1 HMM 原理概述
隐马尔可夫模型是一种用于描述具有隐藏状态的序列数据的统计模型。它由状态集合、观测集合、初始状态概率分布、状态转移概率矩阵和观测概率矩阵这五个部分组成。
在隐马尔可夫模型中,存在一组隐藏状态,这些状态不能直接被观测到,但它们之间的转移遵循一定的概率规律,即状态转移概率矩阵。每个隐藏状态在某一时刻会以一定的概率产生一个观测值,这个概率由观测概率矩阵描述。
2.2.2 脑部 MR 图像分割案例
在医学领域的脑部 MR 图像分割中,研究人员结合隐马尔可夫模型、高斯混合模型和马尔可夫随机场模型,运用 EM 算法来实现对脑部不同组织的精准分割。
以某脑部疾病诊断项目为例,首先利用高斯混合模型对脑部 MR 图像的灰度值进行建模,将图像中的不同组织(如灰质、白质、脑脊液等)假设为不同的高斯分布。隐马尔可夫模型则用于描述这些组织在空间上的分布规律,因为不同组织在脑部具有一定的空间连续性和相关性。马尔可夫随机场模型进一步考虑了图像中像素之间的空间邻域关系,增强了分割的准确性。
在使用 EM 算法进行分割时,E 步中根据当前的模型参数估计,计算每个像素点属于不同组织类别的后验概率。M 步中,基于 E 步得到的后验概率,更新高斯混合模型的参数(如均值、方差和权重)、隐马尔可夫模型的状态转移概率和观测概率,以及马尔可夫随机场模型的相关参数。通过多次迭代,模型能够准确地将脑部 MR 图像中的灰质、白质和脑脊液等组织分割出来,为医生对脑部疾病的诊断提供了清晰、准确的图像信息,有助于提高诊断的准确性和效率。
2.3 EM 算法的 E 步和 M 步示例
为了更好地理解 EM 算法的 E 步和 M 步,我们来看一个简单的硬币抛掷示例。假设我们有两枚硬币(Coin A 和 Coin B),每枚硬币有不同的正面朝上的概率。我们的目标是通过观察一系列抛掷结果,估计每枚硬币的正面朝上的概率。
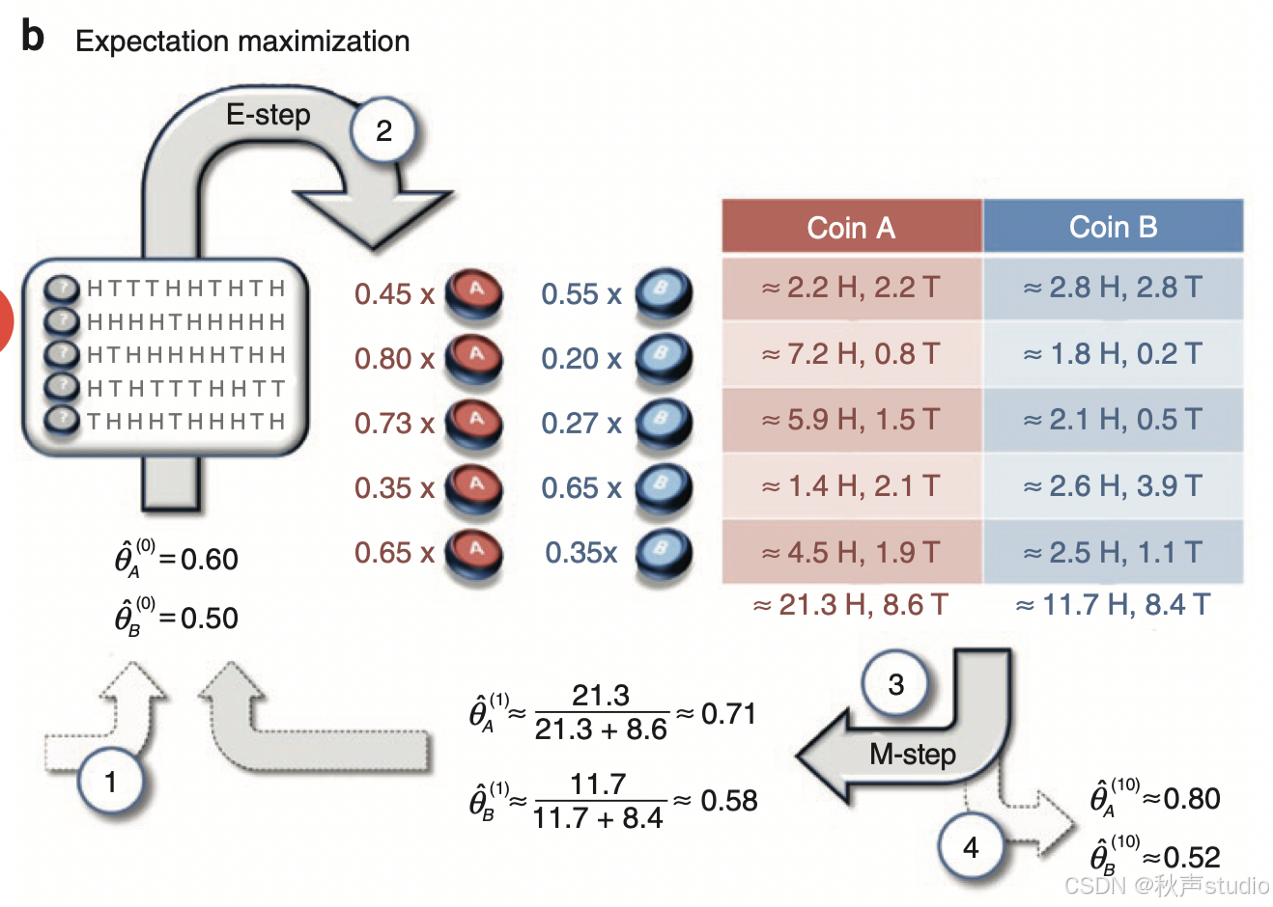
在上图中,我们展示了 EM 算法的 E 步和 M 步的计算过程。在 E 步中,我们计算每个抛掷结果属于 Coin A 或 Coin B 的概率。在 M 步中,我们根据这些概率更新 Coin A 和 Coin B 的正面朝上的概率。通过多次迭代,我们最终得到了 Coin A 和 Coin B 的正面朝上的概率估计。
三. 期望最大化算法的优势与挑战
3.1 算法优势
3.1.1 简洁高效
期望最大化算法的结构十分清晰,其核心步骤仅包括期望(E)步和最大化(M)步的交替执行。这种简单明了的结构使得算法易于理解和实现。在实际应用中,研究者和开发者能够相对轻松地掌握算法的原理和流程,从而快速将其应用到具体问题中。
3.1.2 适用于高维数据
在处理高维数据中的复杂模型时,期望最大化算法展现出了强大的能力。随着数据维度的增加,许多传统的参数估计方法往往会面临计算复杂度急剧上升、模型难以求解等问题。而 EM 算法通过引入隐变量,将复杂的高维问题分解为相对简单的 E 步和 M 步。
3.2 算法挑战
3.2.1 收敛速度
期望最大化算法的收敛速度可能较慢,尤其是在参数初始化不当的情况下。由于 EM 算法是一种迭代算法,其收敛依赖于每次迭代中参数的更新。如果初始参数选择不合理,算法可能需要进行大量的迭代才能逐渐逼近最优解。
3.2.2 局部最优
EM 算法在迭代过程中容易陷入局部最优解。这是因为算法在每次迭代中,都是基于当前的参数估计来更新参数,以最大化对数似然函数的下界(Q 函数)。然而,Q 函数可能存在多个局部最大值,当算法收敛到某个局部最大值时,就会停止迭代,而此时得到的参数估计值可能并非全局最优解。
四. 期望最大化算法的优化策略
4.1 针对收敛速度的优化
4.1.1 优化初始值选择
初始值的选择对期望最大化算法的收敛速度有着至关重要的影响。若初始值与真实值相差甚远,算法可能需要进行大量不必要的迭代才能逐渐接近最优解。在高斯混合模型中,若初始均值远离数据的实际分布中心,那么在 E 步计算每个数据点属于各高斯分布的概率时,会产生较大偏差,进而导致 M 步中参数更新的方向不准确,使得算法收敛缓慢。
为了优化初始值选择,可以采用 K-means 算法对数据进行初步聚类。K-means 算法能够快速将数据划分成 K 个簇,每个簇的中心可作为高斯混合模型中各高斯分布均值的初始值。对于协方差矩阵和权重,也可以根据 K-means 聚类的结果进行合理初始化。
4.1.2 改进迭代方式
改进迭代方式是提升期望最大化算法收敛速度的另一个重要途径。一种常见的方法是采用加速技术,如在 M 步中使用拟牛顿法。拟牛顿法通过近似海森矩阵来加速函数的优化过程,相比传统的梯度上升法,它能够更快地找到使 Q 函数最大化的参数值。
4.2 避免局部最优的方法
4.2.1 多初始值尝试
由于期望最大化算法容易陷入局部最优解,多初始值尝试是一种简单有效的避免方法。具体做法是多次随机初始化模型参数,每次使用不同的初始值运行 EM 算法,然后比较每次运行得到的对数似然函数值,选择对数似然函数值最大的结果作为最终的参数估计。
4.2.2 结合其他优化算法
将期望最大化算法与其他优化算法相结合,也是避免局部最优解的有效策略。模拟退火算法是一种基于概率的全局优化算法,它在迭代过程中以一定的概率接受较差的解,从而有机会跳出局部最优解。在期望最大化算法的迭代过程中,可以引入模拟退火算法的思想。
五. 期望最大化算法与其他算法的比较
5.1 与贝叶斯方法的比较
5.1.1 原理差异
期望最大化算法旨在寻找参数的最大似然估计或最大后验估计。在面对含有隐变量的概率模型时,它通过迭代执行期望(E)步和最大化(M)步来逐步逼近最优参数值。
贝叶斯方法则基于贝叶斯定理,即 P ( θ ∣ X ) = P ( X ∣ θ ) P ( θ ) P ( X ) P(\theta|X) = \frac{P(X|\theta)P(\theta)}{P(X)} P(θ∣X)=P(X)P(X∣θ)P(θ),其中 P ( θ ∣ X ) P(\theta|X) P(θ∣X) 是后验概率, P ( X ∣ θ ) P(X|\theta) P(X∣θ) 是似然函数, P ( θ ) P(\theta) P(θ) 是先验概率, P ( X ) P(X) P(X) 是证据因子。贝叶斯方法将参数视为随机变量,通过结合先验知识和观测数据来更新对参数的估计。
5.1.2 应用场景对比
在数据挖掘领域,当需要对大量数据进行聚类分析时,如果数据分布较为复杂,存在多个潜在的簇,且每个簇可能由不同的概率分布生成,期望最大化算法结合高斯混合模型能够有效地对数据进行建模和聚类。
贝叶斯方法在机器学习中的分类任务中应用广泛。例如在垃圾邮件分类中,我们可以根据邮件的特征(如关键词、发件人等),利用贝叶斯方法计算邮件属于垃圾邮件的后验概率。
5.2 与其他聚类算法的比较
5.2.1 与 k-means 聚类算法对比
k-means 聚类算法是基于距离的聚类方法,它将数据点分配到距离其最近的聚类中心所在的簇中。在初始化阶段,随机选择 k 个数据点作为聚类中心,然后通过不断计算数据点与聚类中心的距离,更新聚类中心,直到聚类结果稳定。
期望最大化算法在聚类分析中,基于概率模型,假设每个样本都由一个隐藏的潜在类别决定,通过估计每个数据点属于不同簇的概率来进行聚类。在高斯混合模型聚类中,它不仅考虑数据点与聚类中心(高斯分布的均值)的距离,还考虑数据点在不同高斯分布下的概率密度。
5.2.2 与层次聚类算法对比
层次聚类算法在处理大规模数据时,分为自下而上的聚合式算法和自上而下的分裂式算法。自下而上的聚合式算法从每个数据点开始构建簇,逐步合并相邻的簇,直到所有数据点都被聚为一类;自上而下的分裂式算法则从整个数据集开始,逐步将其分裂为更小的簇。
期望最大化算法在处理大规模数据时,可以通过数据抽样等方法来降低计算复杂度。通过抽取一部分代表性的数据进行计算,然后将结果推广到整个数据集,从而提高计算效率。
代码示例
这个代码包括初始化步骤、E步和M步,并通过多次迭代来优化模型参数:
import numpy as np
class GaussianMixtureModel:
def __init__(self, n_components, max_iter=100, tol=1e-3):
self.n_components = n_components
self.max_iter = max_iter
self.tol = tol
def initialize_parameters(self, X):
# 初始化权重、均值和协方差矩阵
n_samples, n_features = X.shape
self.weights = np.ones(self.n_components) / self.n_components
self.means = X[np.random.choice(n_samples, self.n_components, replace=False)]
self.covariances = [np.eye(n_features) for _ in range(self.n_components)]
def e_step(self, X):
# 计算每个样本属于各个高斯分布的概率
responsibilities = np.zeros((X.shape[0], self.n_components))
for k in range(self.n_components):
prior = self.weights[k]
likelihood = self.gaussian_pdf(X, self.means[k], self.covariances[k])
responsibilities[:, k] = prior * likelihood
# 归一化概率
sum_responsibilities = responsibilities.sum(axis=1).reshape(-1, 1)
responsibilities /= sum_responsibilities
return responsibilities
def m_step(self, X, responsibilities):
# 更新权重、均值和协方差矩阵
n_samples = X.shape[0]
weights = responsibilities.mean(axis=0)
means = np.dot(responsibilities.T, X) / responsibilities.sum(axis=0).reshape(-1, 1)
covariances = []
for k in range(self.n_components):
diff = X - means[k]
weighted_diff = responsibilities[:, k].reshape(-1, 1) * diff
covariance = np.dot(diff.T, weighted_diff) / responsibilities[:, k].sum()
covariances.append(covariance)
self.weights = weights
self.means = means
self.covariances = covariances
def gaussian_pdf(self, X, mean, covariance):
# 计算高斯分布的概率密度函数
det_cov = np.linalg.det(covariance)
inv_cov = np.linalg.inv(covariance)
d = X.shape[1]
norm_const = 1.0 / (np.sqrt((2 * np.pi) ** d * det_cov))
exponent = -0.5 * ((X - mean).dot(inv_cov) * (X - mean)).sum(axis=1)
return norm_const * np.exp(exponent)
def fit(self, X):
self.initialize_parameters(X)
log_likelihoods = []
for i in range(self.max_iter):
prev_log_likelihood = self.log_likelihood(X)
responsibilities = self.e_step(X)
self.m_step(X, responsibilities)
current_log_likelihood = self.log_likelihood(X)
log_likelihoods.append(current_log_likelihood)
if abs(current_log_likelihood - prev_log_likelihood) < self.tol:
break
def log_likelihood(self, X):
# 计算数据集的对数似然度
total_prob = np.zeros(X.shape[0])
for k in range(self.n_components):
prior = self.weights[k]
likelihood = self.gaussian_pdf(X, self.means[k], self.covariances[k])
total_prob += prior * likelihood
return np.sum(np.log(total_prob))
# 示例数据
if __name__ == "__main__":
from sklearn.datasets import make_blobs
X, y_true = make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0)
gmm = GaussianMixtureModel(n_components=4)
gmm.fit(X)
print("Means:", gmm.means)
print("Covariances:", gmm.covariances)
print("Weights:", gmm.weights)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
这段代码首先定义了一个GaussianMixtureModel类,其中包含了初始化参数、执行E步和M步的方法,以及计算高斯分布的概率密度函数和对数似然度的方法。最后,在示例部分生成了一些聚类数据并用该模型进行了拟合。
结语
期望最大化算法通过巧妙的期望(E)步和最大化(M)步的迭代,能够有效地处理包含隐变量或缺失数据的概率模型的参数估计问题。在高斯混合模型、隐马尔可夫模型、缺失数据处理以及聚类分析等众多领域,该算法都展现出了强大的应用能力。
尽管 EM 算法面临收敛速度较慢、容易陷入局部最优解等挑战,但通过优化初始值选择、改进迭代方式、结合其他优化算法等策略,可以显著提升算法的性能。未来,随着各学科的不断交叉融合,期望最大化算法有望在更多新兴领域发挥重要作用。
参考文献
- Expectation-Maximization Algorithm - Wikipedia
- Gaussian Mixture Models - Scikit-learn Documentation
- Hidden Markov Models - Stanford University

学习是通往智慧高峰的阶梯,努力是成功的基石。
我在求知路上不懈探索,将点滴感悟与收获都记在博客里。
要是我的博客能触动您,盼您 点个赞、留个言,再关注一下。
您的支持是我前进的动力,愿您的点赞为您带来好运,愿您生活常暖、快乐常伴!
希望您常来看看,我是 秋声,与您一同成长。
秋声敬上,期待再会!
评论记录:
回复评论: