

作者:来自 vivo 互联网服务器团队 - Zeng Luobin
在使用 RocksDB 存储引擎的过程中,有部分开发者遇到了内存使用超出预期的情况。本文针对这一问题展开了深入分析,从内存使用原理、RocksDB 内存管理机制、常见内存使用问题等方面进行了详细探讨,并提出了相应的解决方案和优化建议,希望能够帮助开发者更好地理解和优化 RocksDB 的内存使用情况,提升系统性能和稳定性。
一、背景
1.1 前言
在现代数据库系统中,RocksDB 作为一种高性能的键值存储引擎,广泛应用于需要高吞吐量和低延迟的场景。然而,在使用过程中观察到 RocksDB 的内存使用常常超出预设的阈值,这一现象对系统的稳定性和可用性构成了严重威胁。
RocksDB 提供了通过 block-cache-size 参数来控制缓存使用的机制。开发者可以通过以下代码片段设置缓存大小:
std::shared_ptr cache = rocksdb::NewLRUCache(cache_size, -1, true); 左右滑动查看完整代码
然而,实际应用中发现,RocksDB 的内存占用往往超出了设定的 cache_size 值。这种内存使用的不可预测性导致了内存分配的失控,甚至触发了程序的 OOM(Out of Memory)错误,严重影响了服务的连续性和可靠性。
有部分开发者报告了相似的内存超额使用问题,该问题在 GitHub 社区也引起了广泛关注。
1.2 内存分析流程
在分析内存的过程中,可以搭配许多 Linux 的命令工具来进行。以下是一套内存分析的基本思路:
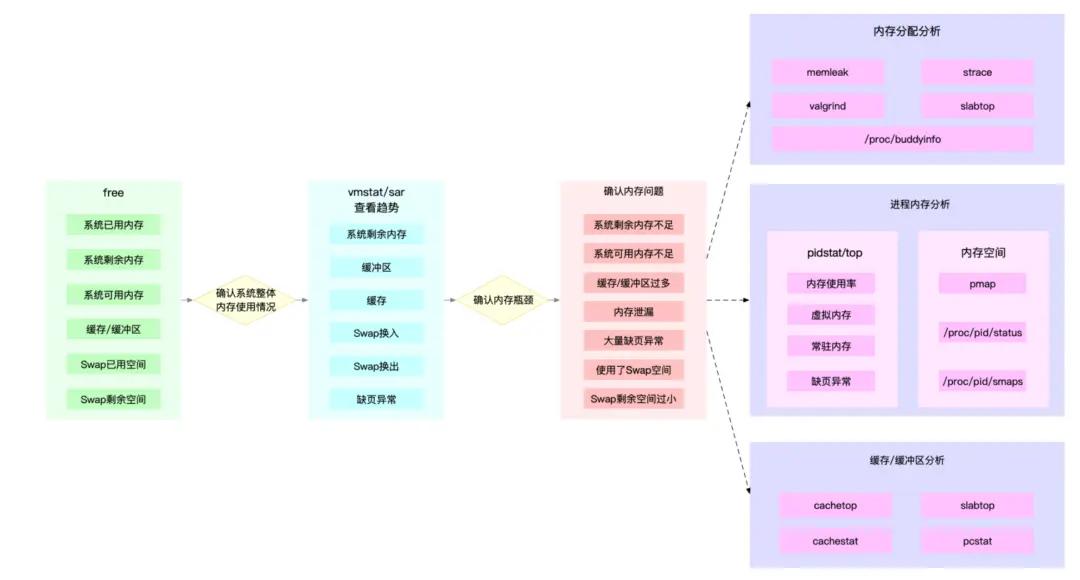
图片来源:https://learn.lianglianglee.com/
1、可以先用 free 和 top,查看系统整体的内存使用情况。
2、再用 vmstat 和 pidstat,查看一段时间的趋势,从而判断出内存问题的类型。
3、最后进行详细分析,比如内存分配分析、缓存 / 缓冲区分析、具体进程的内存使用分析等。
其中,第一步和第二步可以观察到内存问题的现象,而最难的往往是第三步,对内存的使用情况进行分析。第三步中需要结合业务代码,对问题的根因提出假设,然后配合一些工具来验证假设。分析的过程更像在做实验:提出假设,收集数据,验证假设,得出结论。下文中,也会搭配内存工具进行分析,供读者参考。
彩蛋提醒
我们为大家准备了抽奖福利,请继续阅读下去。
二、问题描述
在前文所述的 RocksDB 内存使用问题背景下,我们业务生产环境遭遇了相似的挑战。应用程序采用 glibc 的 ptmalloc 作为内存分配器。在程序中,存在两个 RocksDB 实例,分别用于存储不同类型的数据。根据配置,两个实例的 block-cache-size 分别被设定为 4GB 和 8GB。然而,实际的内存消耗量远远超出了这一预设值,导致整体内存使用量显著高于预期。
通过执行 free -g 命令,监测到程序的内存使用量达到了 59GB,这一数值已经接近了物理服务器的内存容量阈值。此外,通过定期执行 vmstat 3 命令,观察到自服务启动以来,内存使用量持续上升,直至接近 100% 的使用率。这一现象表明,系统内存已极度紧张,存在触发 OOM(Out of Memory)错误的风险。
鉴于当前内存使用情况,确认了内存管理问题的存在,并认识到需要进一步结合源代码进行深入分析,以识别内存使用异常的根本原因,并探索相应的优化措施。
|
名称 |
信息 |
|
机器配置 |
32C64G 物理机 |
|
内存使用量 |
59G |
|
RocksDB 实例数量 |
2 |
|
每个 RocksDB 实例文件夹大小 |
实例 1:190G、实例 2:180G |
|
内存分配器 |
glibc ptmalloc |
|
block_cache 设置 |
实例 1:4G、实例 2:8G |
三、分析过程
3.1 内存泄露分析
以下分析均在内部测试环境中进行,使用的是 16C32G 的机器。起初,怀疑 RocksDB 存在内存泄露,会不断申请内存并且不会回收。
分析内存泄露的常用工具有 valgrind、memleak、strace、jemalloc 的 jeprof。这里用到的工具是 jemalloc 的 jeprof。jeprof 的原理主要是在内存的 malloc 和 free 的地方进行监控并收集数据,使用时可以设置定期打印数据。
通过 RocksDB 提供的的 db.getProperty () 方法对各个模块占用内存情况进行取值,结果如下:
rocksdb.estimate-table-readers-mem: 16014055104 // 重点关注rocksdb.block-cache-usage: 1073659024 // 重点关注左右滑动查看完整代码
发现主要占用内存的地方有两个:block-cache-usage 和 estimate-table-readers-mem。这两个属性分别对应了 RocksDB 中的 block_cache 以及 indexs/filters。
但是随着时间的推移,block_cache 和 indexs/filters 会达到一个均衡点,不再增加上涨。与 RocksDB 存在内存泄露的假设不相符。
进一步分析 RocksDB 分配内存的调用堆栈,由于 glibc ptmalloc 无法打印调用堆栈,将 glibc ptmalloc 切换成了 jemalloc,通过 jeprof 进行内存调用堆栈的打印,以下是 jemalloc 的安装方法:
# 用jemalloc 对于服务来说没有改造成本。# 可以直接使用LD_PRELOAD=/usr/local/lib/libjemalloc.so这种动态链接的方式去植入# 前提是Linux机器上需要先安装jemalloc:wget https://github.com/jemalloc/jemalloc/archive/5.1.0.tar.gz tar zxvf jemalloc-5.1.0.tar.gzcd jemalloc-5.1.0/./autogen.sh./configure --prefix=/usr/local/jemalloc-5.1.0 --enable-profmake && make install_bin install_include install_lib左右滑动查看完整代码
上述命令中,--enable-prof 代表开启 jemalloc 的 jeprof 功能。
安装完成后,通过 LD_PRELOAD 命令来开启 jemalloc 的 malloc 和 free。LD_PRELOAD 的原理是直接使用 jemalloc 的 malloc 和 free 方法替换掉 glibc 的 malloc/free。
通过以下命令启动程序:
export MALLOC_CONF="prof:true,lg_prof_interval:29"LD_PRELOAD=/usr/local/jemalloc-5.1.0/lib/libjemalloc.so ./process_start左右滑动查看完整代码
上述命令中
export MALLOC_CONF="prof:true,lg_prof_interval:29"
代表开启 jeprof 的信息捕获,内存每次上涨 2 的 29 次方 btyes (512MB) 便记录一次信息。最终输出了结果,可以通过以下命令将结果转成调用堆栈图:
jeprof --show_bytes --pdf ./process_start jeprof.34447.0.f.heap > result.pdf左右滑动查看完整代码
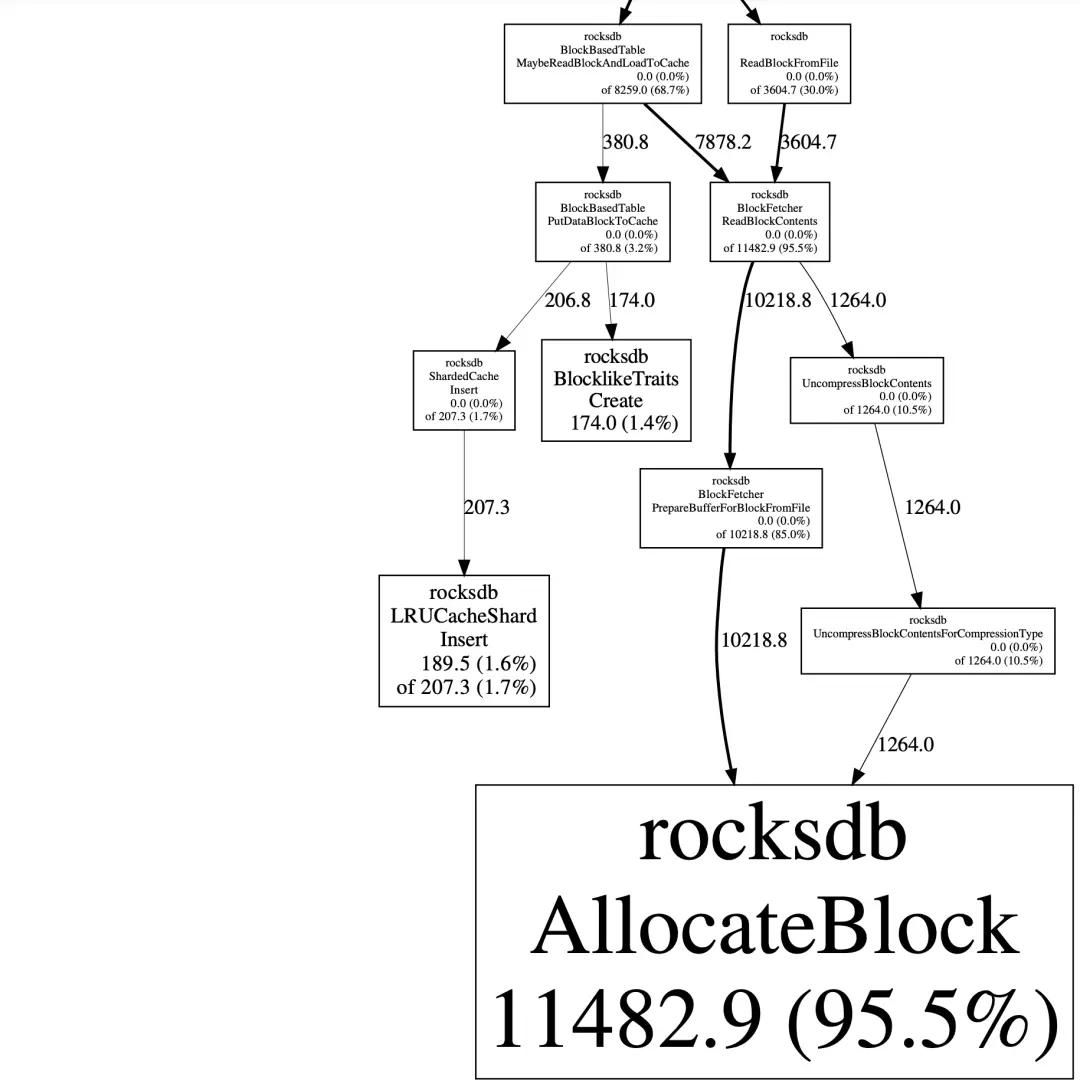
最终观察堆栈图(只截取了部分)发现,RocksDB 正常调用分配内存的方法:rocksdb::AllocateBlock,没有观察到有内存泄露的情况。
3.2 系统 glibc ptmalloc 分析
搜索了很多类似的问题,发现也有开发者都遇到了 glibc 内存分配不释放的问题,便怀疑是否是 glibc 的内存分配不合理导致的。目前线上环境 glibc 的版本是 2.17。

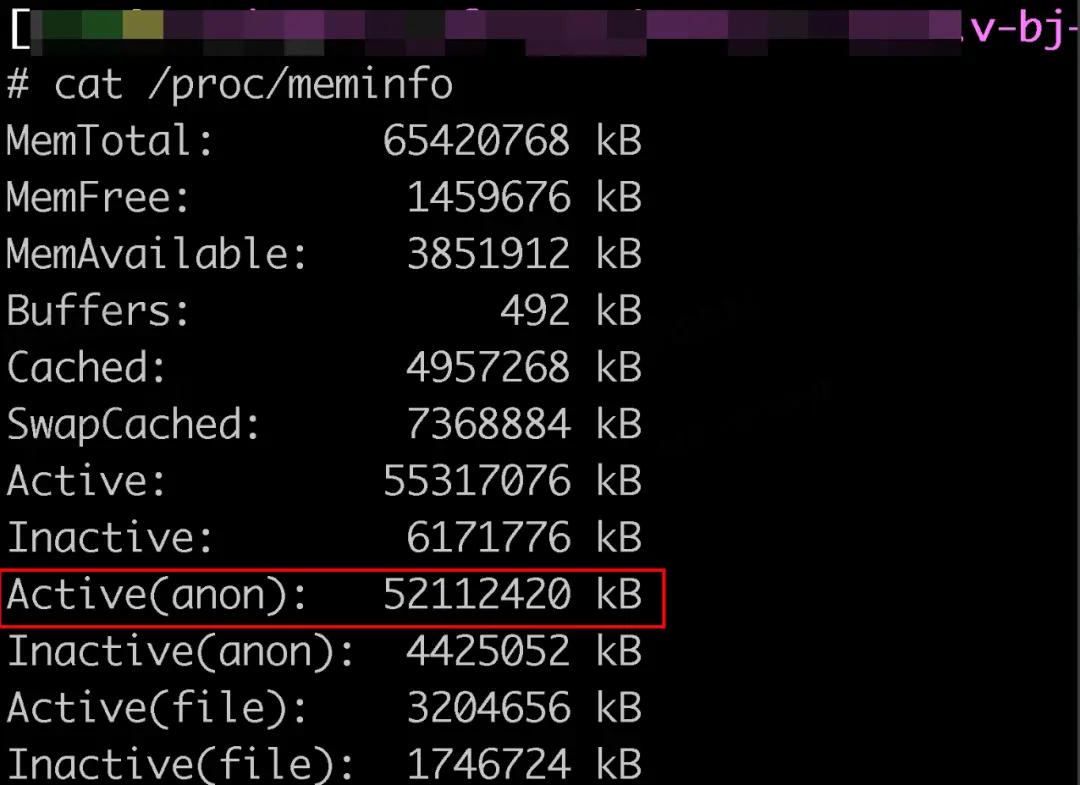
查看了线上机器的 /proc/meminfo,大部分内存主要用在了程序申请的栈内存和堆内存中,可以看到下图中 Active (anon) 匿名内存占用了 52G,这部分内存申请后没有被释放。
glibc 申请的内存均属于这部分内存。
其次,通过 pmap -X pid 查看进程的内存块,发现有很多 64MB 的内存段。
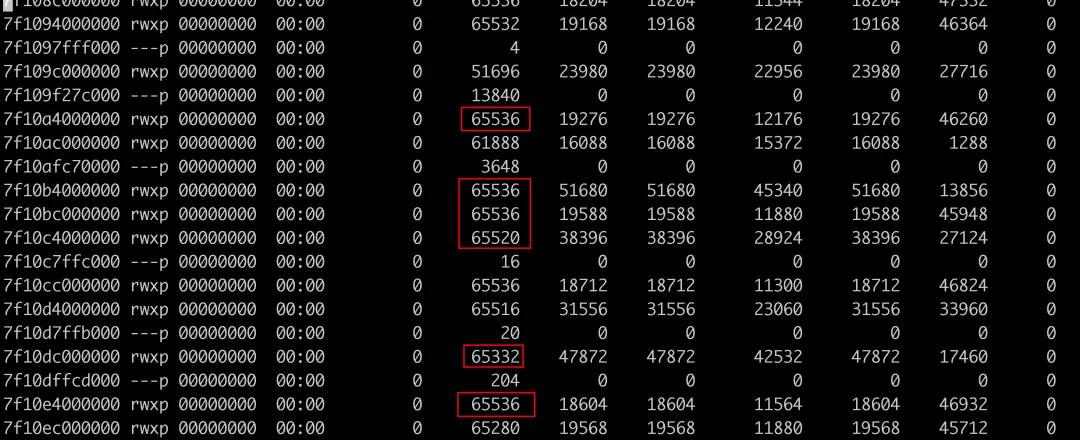
为什么会创建这么多的 64M 的内存区域?这个跟 glibc 的内存分配器有关系。glibc 每次进行 mmap 分配时申请内存的大小在 64 位系统上默认为 64MB。
此时便进一步提出了新的假设:是否因为 glibc 的内存分配机制不合理,导致内存不断申请,但是不释放资源?
分析 glibc 分配的内存情况,可以使用 glibc 提供的接口:
malloc_info(https://man7.org/linux/man-pages/man3/malloc_info.3.html
The malloc_info() function exports an XML string that describes the current state of the memory-allocation implementation in the caller. The string is printed on the file stream stream. The exported string includes information about all arenas.
以下为 malloc_info 的接口定义。该接口会将内存分配的情况直接以 XML 的形式输出到文件中。
int malloc_info(int options, FILE *stream);左右滑动查看完整代码
在程序中添加内存信息打印的代码,每隔一段时间触发一次打印:
FILE *filePointer;filePointer = fopen("mem_info.log", "a");if (filePointer != nullptr) { malloc_info(0, filePointer); fclose(filePointer);}左右滑动查看完整代码
以下为 malloc_info 输出的内容(截取部分内容):
<malloc version="1"><heap nr="0"><sizes> <size from="17" to="32" total="32" count="1"/> <size from="33" to="48" total="48" count="1"/> <size from="81" to="96" total="1824" count="19"/> <size from="97" to="112" total="112" count="1"/> <size from="33" to="33" total="42636" count="1292"/> // ....sizes><total type="fast" count="22" size="2016"/><total type="rest" count="5509" size="33761685"/><system type="current" size="230117376"/><system type="max" size="230117376"/><aspace type="total" size="230117376"/><aspace type="mprotect" size="230117376"/>heap>左右滑动查看完整代码
XML 内容阐述:
nr 即 arena,通常一个线程一个,线程间会相互争抢 arena。
2.
大小在一定范围内的内存,会放到一个链表里,这就是其中一个链表。from 是内存下限,to 是上限,上面的意思是内存分配在 [17,32] 范围内的空闲内存总共有 32 个。
3.
即 fastbin 这链表当前有 22 个空闲内存块,大小为 2016 字节。
4.
除 fastbin 以外,所有链表空闲的内存数量,以及内存大小,此处内存块数量为 5509,大小为 33761685 字节。
因此,fast 和 rest 加起来为当前 glibc 中空闲的未归还给操作系统的内存。通过命令 awk 将文件中所有 fast 和 rest 占用的内存加起来后,发现约为 4G 。

当前 RocksDB 进程的内存使用量为 20.48G,上述提到 block-cache-usage 和 estimate-table-readers-mem 加起来只有 15.9G (1073659024 bytes + 16014055104 bytes)。相当于中间差距还有 4G 左右。刚好和 glibc 占用的空闲内存相吻合。

最终确认是由于 glibc 的 ptmalloc 内存管理器申请内存不回收,导致了机器内存紧张。
四、问题解决
发现是 glibc ptmalloc 的问题之后,解决也相对简单,业内有更好的 ptmalloc 替代方案,如 jemalloc 以及 tcmalloc。
将 jemalloc 应用到线上环境之后发现,确实像预期那样,内存的使用相比于 ptmalloc 更少,此前,机器的内存一直维持在高位,使用 jemalloc 之后,内存的使用下降了 1/4(从 95%+ 下降到 80%+),随着内存地释放,有更多的内存可用于处理请求,IO 和 CPU 的使用率就降低了,下图是内存、磁盘 IO 使用率以及 CPU 空闲率的对比图。
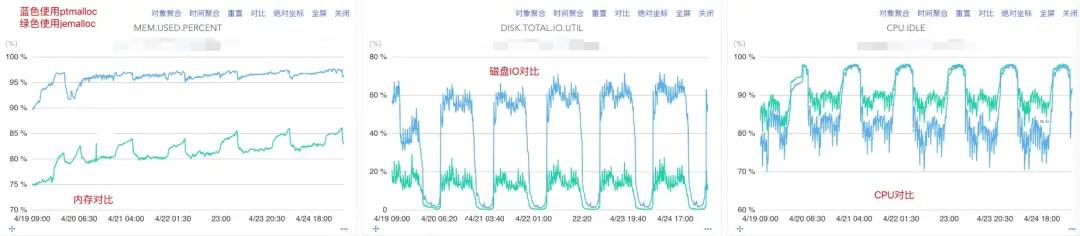
在相关性能指标得到优化之后,服务可用性以及 RT 也得到了提升。
五、总结
在进行内存超量使用问题的分析过程中,最初怀疑是 RocksDB 存在一些内存管理不合理的地方导致了内存超量使用。然而,经过深入研究和分析,发现实际的原因主要由 glibc 的 ptmalloc 内存回收机制所导致。整个分析过程较为繁琐,需要结合一些合适的内存分析工具,逐层深入,不断假设并验证猜想。
总的来说,内存超量使用问题得到了解释,也成功解决。通过逐步深入,持续假设和验证,最终找到了真正的问题所在,希望能为读者在解决类似问题上提供一些灵感和思路。
六、参考文献
https://github.com/facebook/rocksdb/wiki/Partitioned-Index-Filters
https://github.com/facebook/rocksdb/wiki/Memory-usage-in-RocksDB
http://jemalloc.net/jemalloc.3.html
https://paper.seebug.org/papers/Archive/refs/heap/glibc%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86ptmalloc%E6%BA%90%E4%BB%A3%E7%A0%81%E5%88%86%E6%9E%90.pdfhttps://man7.org/linux/man-pages/man3/malloc_info.3.html
END
粉丝福利
vivo 互联网技术为开发者朋友们提供了 iQOO & NBA 联名款周边(各 1 个),快来领取吧!

✦
✦
✦

iQOO x NBA 联名洗漱包 x1
iQOO x NBA 联名运动水杯 x1
参与方法:
转发本篇内容到朋友圈,截图保存界面,再到 vivo 互联网技术微信后台发送 “v 爱技术” 参与抽奖,上传截图即可。(请保留朋友圈分享链接至开奖当天)
开奖时间:2024 年 12 月 27 日 20:00
奖品将通过邮寄发放,中奖者需在 5 天内提供收货信息。(联系本号后台)
注意:
1. 我们将会通过人工审核截图进行校对。未及时提供收货信息或未完成所有步骤的参与者将视为自动放弃。
2. 活动解释权归 vivo 互联网技术所有。
猜你喜欢
本文分享自微信公众号 - vivo 互联网技术(vivoVMIC)。
如有侵权,请联系 [email protected] 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。
评论记录:
回复评论: