
一、Spark 简介
Apache Spark 是一个专为大规模数据处理而设计的快速、通用、可扩展的大数据分析计算引擎。它诞生于 2009 年,由美国加州伯克利大学的 AMP 实验室开发,2013 年被纳入 Apache 开源项目,并迅速成为顶级项目。
Spark 被认为是 Hadoop 框架的升级版,主要原因在于其功能强大且独特。首先,它在性能方面表现优异。内存计算下,Spark 比 Hadoop 快 100 倍,在磁盘上也比 Hadoop 快 10 倍。例如,在处理大规模数据时,Spark 可以将中间结果存储在内存中,避免了 Hadoop 中频繁的磁盘读写操作,从而大大提高了计算速度。
其次,Spark 具有很高的易用性。它支持多种编程语言,包括 Java、Scala、Python 和 R。这使得不同背景的开发者都能轻松上手,利用 Spark 进行大数据分析。例如,Python 在人工智能和机器学习领域的广泛应用,使得开发者可以借助 Spark 轻松处理大规模数据,同时利用已封装好的算法库,降低开发门槛。
此外,Spark 的通用性也是其一大亮点。它提供了丰富的库,如 Spark Core、Spark SQL、Spark Streaming、MLlib 和 GraphX。开发者可以在同一个应用程序中无缝组合使用这些库,完成各种复杂的运算,包括 SQL 查询、文本处理、机器学习和图计算等。例如,在数据分析项目中,可以使用 Spark SQL 进行数据查询,利用 MLlib 进行机器学习算法训练,实现一站式的大数据处理解决方案。
总之,Spark 以其快速、通用、可扩展的特点,成为了大数据分析领域的重要工具,为大规模数据处理提供了强大的支持。
二、核心功能概述
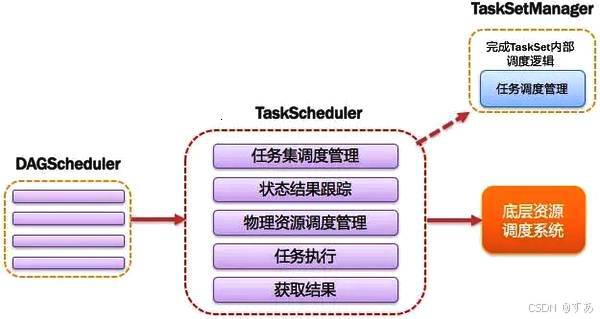
(一)SparkContext
SparkContext 是 DriverApplication 执行与输出的关键。它隐藏了网络通信、分布式部署、消息通信、存储能力、计算能力、缓存、测量系统、文件服务、Web 服务等众多复杂功能。内置的 DAGScheduler 负责创建 Job,将有向无环图(DAG)中的弹性分布式数据集(RDD)划分到不同的 Stage,然后提交 Stage。例如,在一个复杂的数据处理流程中,DAGScheduler 会根据数据的依赖关系将任务划分为多个阶段,确保任务的高效执行。内置的 TaskScheduler 则负责资源的申请、任务的提交及请求集群对任务的调度等工作。它会根据集群的资源情况和任务的需求,合理地分配计算资源,提高任务的执行效率。
(二)存储体系
Spark 的存储体系在提升任务执行效率方面起着重要作用。Spark 优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘。这种方式极大地减少了磁盘 I/O,例如,在处理大规模数据时,如果数据能够全部存储在内存中,那么数据的读取和写入速度将大大提高。此外,Spark 还提供了以内存为中心的高容错的分布式文件系统 Tachyon 供用户进行选择。Tachyon 能够为 Spark 提供可靠的内存级的文件共享服务,进一步提高了数据的存储和访问效率。
(三)计算引擎
计算引擎是 Spark 的核心组成部分。它由 SparkContext 中的 DAGScheduler、RDD 以及具体节点上的 Executor 负责执行的 Map 和 Reduce 任务组成。在任务正式提交与执行之前,DAGScheduler 和 RDD 会将 Job 中的 RDD 组织成有向无关图(DAG),并对 Stage 进行划分。这决定了任务执行阶段任务的数量、迭代计算、shuffle 等过程。例如,在进行机器学习算法训练时,计算引擎会根据数据的依赖关系和算法的需求,自动划分任务阶段,合理分配计算资源,提高训练效率。
(四)部署模式
Spark 在 TaskScheduler 组件中提供了对多种部署模式的支持。Standalone 模式构建一个基于 Master/Slave 的资源调度集群,Spark 任务提交给 Master 运行。Yarn 模式下,Spark 客户端直接连接 Yarn,有 yarn-client 和 yarn-cluster 两种模式,主要区别在于 Driver 程序的运行节点不同,适用于不同的场景,如 yarn-client 适用于交互、调试,yarn-cluster 适用于生产环境。Mesos 模式中,Spark 客户端直接连接 Mesos,不需要额外构建 Spark 集群。此外,Spark 还提供了便于开发和调试的 Local 模式,包括 local(所有计算都运行在一个线程当中)、local [n](指定使用 n 个线程来运行计算)、local [*](按照 CPU 的最多核数来设置线程数)等设置方式。
三、扩展功能展示
(一)Spark SQL
Spark SQL 为 Spark 带来了强大的 SQL 处理能力。它不仅支持在 Spark 程序内使用 SQL 语句进行数据查询,还允许从外部工具如 Tableau 等通过标准数据库连接器(JDBC/ODBC)连接进行查询。例如,在企业数据分析场景中,数据分析师可以使用熟悉的商业智能软件连接 Spark SQL,轻松进行数据分析。
Spark SQL 可以从多种结构化数据源如 JSON、Hive、Parquet 等中读取数据。当处理数据时,它会将 SQL 语句转换为语法树,然后通过优化器生成高效的物理执行计划。这种方式使得查询更加高效,能够快速处理大规模数据。例如,从一个大型的 Hive 表中查询特定条件的数据,Spark SQL 能够快速分析并返回结果。
(二)Spark Streaming
Spark Streaming 主要用于流式计算。它支持多种数据输入源,如 Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等。Dstream 是 Spark Streaming 中所有数据流的抽象,本质上由一系列连续的 RDD 组成。
在内部实现上,Dstream 可以将流式计算分解成一系列短小的批处理作业,每一段数据都转换成 Spark 中的 RDD,然后进行各种操作。例如,在实时监控系统中,从网络数据源接收数据后,通过 Spark Streaming 进行实时分析,及时发现异常情况。
Spark Streaming 具有高吞吐量和容错能力强等特点。它可以和 Spark 的其他组件如 MLlib、GraphX 完美融合,为实时数据分析提供更多的可能性。
(三)GraphX
GraphX 是一个分布式图计算框架。它遵循 Pregel 模型实现,提供对图的抽象,即弹性分布式属性图,这是一个有向多重图,带有连接到每个顶点和边的用户定义的对象。
GraphX 封装了多种算法实现,如最短路径算法、图遍历算法、连通性分析、PageRank、社区检测等。例如,在社交网络分析中,可以使用 GraphX 快速计算用户之间的关系,发现社交网络中的关键节点和社区。
GraphX 统一了 Graph View 和 Table View,可以非常轻松地进行 pipeline 操作,为图计算提供了强大的工具。
(四)MLlib
MLlib 为 Spark 提供了一个强大的机器学习框架。它涵盖了多种数学算法,如分类算法(包括逻辑回归、决策树、随机森林等)、回归算法(线性回归、决策树回归等)、聚类算法(K-means 聚类、Gaussian Mixture Model 等)、推荐算法(交替最小二乘法)和频繁模式挖掘算法等。
MLlib 的出现降低了用户学习成本,用户无需深入了解复杂的机器学习算法实现细节,就可以利用这些算法进行大规模数据的机器学习任务。例如,在电商推荐系统中,可以使用 MLlib 的推荐算法为用户推荐感兴趣的商品。
四、总结与展望
Apache Spark 以其强大的核心功能和丰富的扩展功能,在大数据处理领域展现出了巨大的优势。SparkContext 作为应用程序执行与输出的关键,隐藏了众多复杂功能,其内置的 DAGScheduler 和 TaskScheduler 高效地管理着任务的创建、划分和调度。存储体系优先使用内存存储,极大地减少了磁盘 I/O,提高了任务执行效率,同时 Tachyon 为 Spark 提供了可靠的内存级文件共享服务。计算引擎由 DAGScheduler、RDD 和 Executor 组成,能够自动划分任务阶段,合理分配计算资源。部署模式的多样性使得 Spark 能够适应不同的应用场景。
扩展功能方面,Spark SQL 为用户提供了强大的 SQL 处理能力,支持多种数据源和外部工具连接,使得数据分析更加便捷高效。Spark Streaming 适用于流式计算,支持多种数据输入源,能够将流式计算分解为批处理作业,具有高吞吐量和容错能力强的特点。GraphX 作为分布式图计算框架,封装了多种算法实现,为图计算提供了强大的工具。MLlib 则为 Spark 提供了丰富的机器学习算法,降低了用户学习成本,使得大规模数据的机器学习任务变得更加容易。
然而,Spark 也面临着一些挑战。例如,在处理大规模数据时,内存的使用可能会受到限制,需要更好地管理内存资源。同时,与其他大数据处理框架的集成也需要进一步优化,以提高系统的整体性能。
展望未来,Spark 的发展潜力巨大。随着大数据技术的不断发展,对数据处理的速度和效率要求将越来越高。Spark 将继续改进其性能和可扩展性,以处理更大规模的数据和更复杂的计算任务。更多的应用场景将被开发出来,如机器学习、图计算等领域的应用将更加广泛。同时,Spark 的生态系统将不断壮大,更多的组件将加入其中,为用户提供更加全面的大数据处理解决方案。此外,Spark 还将进一步提高与其他大数据技术的集成性,为用户提供更加便捷的使用体验。
总之,Apache Spark 凭借其强大的功能和广阔的发展前景,将在大数据处理领域继续发挥重要作用。
评论记录:
回复评论: