
一、概述
几乎每个Flink作业都必须在其运算符之间交换数据,由于这些记录不仅可以发送到同一JVM中的另一个实例,还可以发送到单独的进程,因此需要先将记录序列化为字节。类似地,Flink的堆外状态后端基于本地嵌入式RocksDB实例,该实例以本机C++代码实现,因此也需要在每次状态访问时转换为字节。如果执行不正确,仅有线和状态序列化就很容易消耗作业的大量性能,因此,每当您查看Flink作业的分析器输出时,您很可能会在使用CPU周期的顶部看到序列化。
因此,序列化对我们的Flink作业至关重要
本质上,Flink试图推断有关作业数据类型的信息以进行连接和状态序列化,并能够通过引用单个字段名称来使用分组、连接和聚合操作,例如stream. keyBy("ruleId")或dataSet.connect(另一个).where("name").equalTo("个性化名称")。它还允许优化序列化格式以及减少不必要的去序列化(主要是在某些批处理操作以及SQL/表API中)。
二、序列化器选择
Flink的开箱即用序列化大致有以下几种:
- Flink为基本类型(Java原语及其装箱形式)、数组、复合类型(元组、Scala案例类、行)和一些辅助类型(Option, Either, Lists, Maps…)提供了特殊的序列化程序
- POJO:一个公共的、独立的类,具有公共的无参数构造函数和类层次结构中的所有非静态、非瞬态字段,要么是公共的,要么是公共的getter-和setter-method;
- 泛型类型:不被识别为POJO然后通过Kryo序列化的用户定义数据类型。
- 自定义序列化程序:可以为用户定义的数据类型注册自定义序列化程序。这包括编写自己的序列化程序或通过Kryo集成其他序列化系统,如Google Pro buf或Apache Thrift。
PojoSerializer
如果我们的数据类型没有被专门的序列化程序覆盖,但遵循POJO规则,Flink将使用PojoSerializer序列化,PojoSerializer使用Java反射来访问对象的字段。它快速、通用、特定于Flink,并支持开箱即用的状态模式演变。如果复合数据类型不能序列化为POJO,我们可以在集群日志中找到以下消息(或类似消息):
15:45:51,460 INFO org.apache.flink.api.java.typeutils.TypeExtractor - Class … cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on “Data Types & Serialization” for details of the effect on performance.
这意味着,PojoSerializer将不会被使用,而是Flink将回退到Kryo进行序列化。当然还会有一些情况可能导致Kryo意外回退的情况。
Tuple Data Types
Flink带有一组预定义的元组类型,它们都具有固定的长度,并包含一组可能不同类型的强类型字段。有Tuple0、Tuple1
在使用元组而不是POJO时,这当然是一个(性能)优势。然而,元组在代码中并不那么灵活,描述性肯定也较差。
Row Data Types
行类型主要由Flink的Table和SQLAPI使用。Row将任意数量的对象组合在一起,类似于上面的元组。这些字段不是强类型的,可能都是不同的类型。由于缺少字段类型,Flink的类型提取不能自动提取类型信息,Row的用户需要手动告诉Flink该行的字段类型。然后RowSerializer将利用这些类型进行高效的序列化。
行类型信息可以通过两种方式提供:
1、让源或运算符实现ResultTypeQueryable
- public static class RowSource implements SourceFunction
, ResultTypeQueryable {
- // ...
-
- @Override
- public TypeInformation
getProducedType() {
- return Types.ROW(Types.INT, Types.STRING, Types.OBJECT_ARRAY(Types.STRING));
- }
- }
在构建作业图时使用SingleOutputStreamOperator#returns()提供类型
- DataStream
sourceStream =
- env.addSource(new RowSource())
- .returns(Types.ROW(Types.INT, Types.STRING, Types.OBJECT_ARRAY(Types.STRING)));
如果您未能提供“行”的类型信息,Flink会根据上述规则识别“行”不是有效的POJO类型,并回退到Kryo序列化,这样性能就会下降。
flink 自带的TupleSerializer性能最高,其中一部分原因来源于不需要使用反射来访问 Tuple 中的字段。PojoSerializer 比 TupleSerializer性能差一些,但是比 kryo 的序列化方式性能要高几倍。
Avro
Flink通过将org. apache.flink:flink-avro依赖项添加到作业中来提供对Apache Avro序列化框架(当前使用版本1.8.2)的内置支持。然后,Flink的AvroSerializer可以使用Avro的Specific、Generic和 Reflect数据序列化,并利用Avro的性能和灵活性,特别是在类随时间变化时演变模式方面。
Avro Specific
通过检查给定类型的类型层次结构是否包含SpecificRecordBase类,将自动检测Avro特定记录。可以指定具体的Avro类型,或者——如果我们想更通用并在运算符中允许不同的类型——在我们用户函数中、在ResultTypeQueryable#getProducedType()中或在SingleOutputStreamOperator中使用SpecificRecordBase类型(或子类型)。由于特定记录使用生成的Java代码,因此它们是强类型的,并允许通过已知的getter和setter直接访问字段。
⚠:如果您将Flink类型指定为“SpecificRecord”而不是“SpecificRecordBase”,Flink不会将其视为Avro类型。相反,它将使用Kryo对任何可能相当慢的对象进行解/序列化
Avro Generic
不幸的是,Avro的GenericRecord类型不能自动使用,因为它们需要用户指定模式(手动或从某些模式注册表中检索)。使用该模式,我们可以通过以下任一选项提供正确的类型信息,就像上面的行类型一样:
- implement
ResultTypeQueryable:
- public static class AvroGenericSource implements SourceFunction
, ResultTypeQueryable { - private final GenericRecordAvroTypeInfo producedType;
-
- public AvroGenericSource(Schema schema) {
- this.producedType = new GenericRecordAvroTypeInfo(schema);
- }
-
- @Override
- public TypeInformation
getProducedType() { - return producedType;
- }
- }
- 在构建作业图时使用
SingleOutputStreamOperator#returns()
- DataStream
sourceStream = - env.addSource(new AvroGenericSource())
- .returns(new GenericRecordAvroTypeInfo(schema));
如果没有这种类型信息,Flink将回退到Kryo进行序列化,这将一遍又一遍地将模式序列化到每条记录中。因此,序列化的形式将更大,创建成本更高。
注意:由于Avro的Schema类不可序列化,因此不能按原样发送。我们可以通过将其转换为字符串并在需要时解析它来解决这个问题。如果在初始化时只这样做一次,那么直接发送实际上没有区别。
Avro Reflect
使用Avro的第三种方法是将Flink的PojoSerializer(根据上述规则用于POJO)交换为Avro的基于反射的序列化器。这可以通过调用以下代码实现:
env.getConfig().enableForceAvro();Kryo
任何不属于上述类别或被Flink提供的特殊序列化程序覆盖的类或对象都将被解/序列化,并回退到Kryo(当前版本2.24.0),这是Java中一个强大的通用序列化框架。Flink将此类类型称为泛型类型,我们在调试代码时可能会偶然发现GenericTypeInfo。如果使用Kryo序列化,请确保向kryo注册使用的类型:
env.getConfig().registerKryoType(MyCustomType.class);注册类型会将它们添加内部map(class->tag)中,这样在序列化过程中,Kryo就不必将完全限定的类名作为前缀添加到序列化形式中。相反,Kryo使用这些(整数)标签来识别底层类并减少序列化开销。
注意:Flink将在其检查点和保存点中存储来自类型注册的Kryo serializer mappings,并在作业(重新)启动时保留它们。
禁用Kryo
如果需要,您可以通过调用禁用Kryo回退,即序列化泛型类型的能力
env.getConfig().disableGenericTypes();这对于找出这些回退的应用位置并用更好的序列化程序替换它们非常有用。如果我们的作业有任何具有此配置的泛型类型,它将失败
Apache Thrift(通过Kryo)
除了上面的变体之外,Flink还允许我们向Kryo注册其他类型的序列化框架。从留档(com.twitter:chill-thrift 和 org.apache.thrift:libthrift)添加适当的依赖项后,可以像下面这样使用Apache Thrift:
env.getConfig().addDefaultKryoSerializer(MyCustomType.class, TBaseSerializer.class);这仅在未禁用泛型类型并且MyCustomType是Thrift生成的数据类型时才有效。如果数据类型不是由Thrift生成的,Flink将在运行时失败。
Protobuf(通过Kryo)
在类似于Apache Thrift的方式中,添加正确的依赖项(com.twitter:chill-protobuf 和 com.google.protobuf:protobuf-java)后,Google Protobuf可以注册为自定义序列化程序:
env.getConfig().registerTypeWithKryoSerializer(MyCustomType.class, ProtobufSerializer.class);只要泛型类型没有被禁用,这就可以工作(这将永久禁用Kryo)。如果MyCustomType不是Protobuf生成的类,Flink作业将在运行时失败。
三、状态模式演变
在仔细研究上述每个序列化程序的性能之前,我们想强调的是,性能并不是实际Flink作业中的一切。例如,用于存储状态的类型应该能够在作业的整个生命周期内发展其模式(添加/删除/更改字段),而不会丢失以前的状态。这就是Flink所说的状态模式演变。目前,从Flink 1.10开始,只有两个序列化程序支持开箱即用的模式演变:POJO和Avro。
对于其他任何事情,如果我们想更改状态模式,必须实现自己的自定义序列化程序或使用状态处理器API为新代码修改状态。
四、性能对比
有这么多的序列化选项,要做出正确的选择其实并不容易。我们已经看到了上面概述的每一个的一些技术优势和劣势。由于序列化程序是我们Flink作业的核心,并且通常也作用在热路径上(每个记录调用),所以让我们在https://github.com/dataArtisans/flink-benchmarks的Flink基准项目的帮助下实际更深入地了解它们的性能。这个项目在Flink之上添加了一些微基准(有些比其他更低级)来跟踪性能回归和改进。Flink用于监控序列化堆栈性能的持续基准在SerializationFrameworkMiniBenchmarks.java中实现。
不过,这只是所有可用序列化基准测试的一个子集,我们将在SerializationFrameworkAllBenchmarks.java中找到完整的集合。所有这些都使用可能涵盖平均用例的小型POJO的相同定义。本质上(没有构造函数、getter和setter),这些是它用于评估性能的数据类型:
- public class MyPojo {
- public int id;
- private String name;
- private String[] operationNames;
- private MyOperation[] operations;
- private int otherId1;
- private int otherId2;
- private int otherId3;
- private Object someObject;
- }
- public class MyOperation {
- int id;
- protected String name;
- }
这被适当地映射到tuples、行、Avro specific、Thrift和Protobuf 表示,并通过并行度=4的简单Flink作业发送,其中数据类型在网络通信期间使用,如下所示:
- env.setParallelism(4);
- env.addSource(new PojoSource(RECORDS_PER_INVOCATION, 10))
- .rebalance()
- .addSink(new DiscardingSink<>());
在通过SerializationFrameworkAllBenchmarks.java中定义的jmh微基准测试运行后,得到了官方给出的Flink 1.10以下性能结果(以每毫秒的操作数为单位):
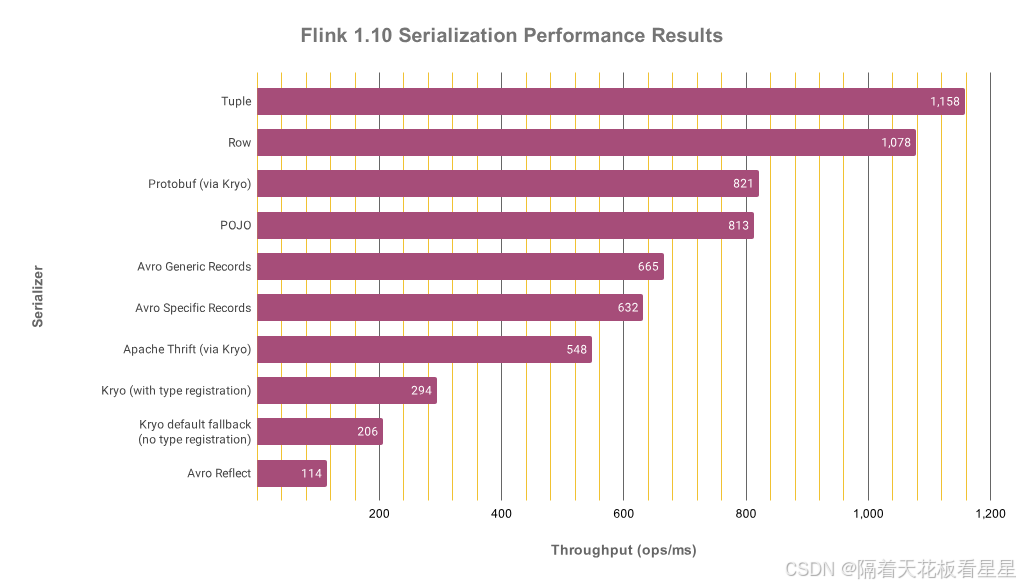
从图中我们可以得到以下信息:
-
从POJO到Kryo的默认回退将性能降低了75%。与使用POJO相比,向Kryo注册类型显着提高了其性能,仅减少了64%的操作。
-
Avro GenericRecord和SpecificRecord的序列化速度大致相同。
-
Avro Reflect序列化甚至比Kryo默认值(-45%)还要慢。
-
Tuples 是最快的,紧随其后的是Rows。两者都利用基于直接访问的快速专用序列化代码,无需Java反射。
-
使用(嵌套)Tuples 而不是POJO可能会使工作速度提高42%(但灵活性较低!)。为PojoSerializer(FLINK-3599)生成代码实际上可能会缩小这一差距(或者至少更接近RowSerializer)。
-
如果不能使用POJO,请尝试使用为其生成特定代码的序列化框架之一来定义用到的数据类型:Protobuf 、Avro、Thrift(按性能顺序)。
注意与所有基准测试一样,请记住,这些数字只能提示Flink在特定场景中的序列化器性能。它们可能因您的数据类型而异,但粗略的分类可能是相同的。如果你不放心,可以使用你的数据类型验证结果。
五、结论
我们研究了Flink如何对不同类型的数据类型执行序列化,并详细说明了技术上的优缺点。对于Flink状态下使用的数据类型,推荐使用POJO或Avro类型,目前,它们是唯一支持开箱即用状态演进的类型,并允许在有状态应用程序随着时间的推移而开发。POJO通常在反序列化方面更快,而Avro可能支持更灵活的模式演进,并且可以更好地与外部系统集成。但是请注意,我们可以对外部组件和内部组件甚至状态和网络通信使用不同的序列化程序
最快的反序列化是通过Flink的内部元组和行序列化器实现的,这些元组和行序列化器可以直接访问这些类型的字段,而无需通过反射。与元组相比,吞吐量降低了大约30%,Protobuf 和POJO类型本身的性能不会太差,并且更加灵活和可维护。Avro(specific and generic)记录以及Thrift数据类型分别进一步降低了20%和30%的性能。所以我们要想方设法避免Kryo,因为这会进一步降低约50%甚至更多的吞吐量!
那么如何避免Kryo的常见陷阱和障碍呢?如何充分利用PojoSerializer等序列化技术的调整呢?敬请关注,我们一起跟着官网壮大自己。
-------------------------------------------------------------------------------------------------------------------------------
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议如下:
第八届大数据与应用统计国际学术研讨会(ISBDAS 2025)
第二届生成式人工智能与信息安全国际学术会议(GAIIS 2025)
第四届电子技术与人工智能国际学术会议(ETAI 2025)
第四届网络安全、人工智能与数字经济国际学术会议(CSAIDE 2025)
评论记录:
回复评论: