
Spark介绍
- Spark诞生的背景与原因:
- MapReduce的局限性:MapReduce语义简单,仅支持map和reduce两种操作,编程范式强制拆分,语义死板且不丰富;运行速度慢,大量与磁盘交互以节约内存,却降低了任务执行效率;功能单一,主要用于大规模离线批处理,处理其他计算场景需结合多种框架,增加了维护成本 。
- Spark的诞生目的:为解决MapReduce的上述问题,提供运行效率高、速度快且能支持多种计算场景的框架。
- Spark的特点与优势:
- 计算速度快:Spark底层的Spark Core对标MapReduce,但速度更快,它将数据全部拉到内存中计算,官网宣称比MapReduce快100倍(虽有夸张,但体现高效性)。
- 提供多种计算场景:是一个all in one的框架。底层Spark Core用于批处理运算;上层提供Spark SQL接口做数仓,能将SQL转换为底层代码运算;Spark Streaming用于实时流处理,通过微批次处理方式,将实时流处理转换为短时间间隔的批处理计算;还提供MLlib做机器学习、GraphX做图计算等接口,官网展示其生态圈丰富。
- Spark在企业中的应用及运行模式:
- 企业应用优势:在企业中应用性好,搭建一套Spark集群就能满足多种计算场景需求。
- 解决历史遗留问题的运行模式:对于之前使用Hadoop框架的企业,若想迁移到Spark,全部推倒重来成本过高。Spark提供多种运行模式,既可以单独安装Spark框架运行任务,也可以通过on YARN模式,在没有Spark集群时,将任务分发到Hadoop的YARN调度到HDFS的数据节点上进行运算,解决了企业的历史遗留问题。
RDD
- Spark基于RDD运算与RDD概念
-
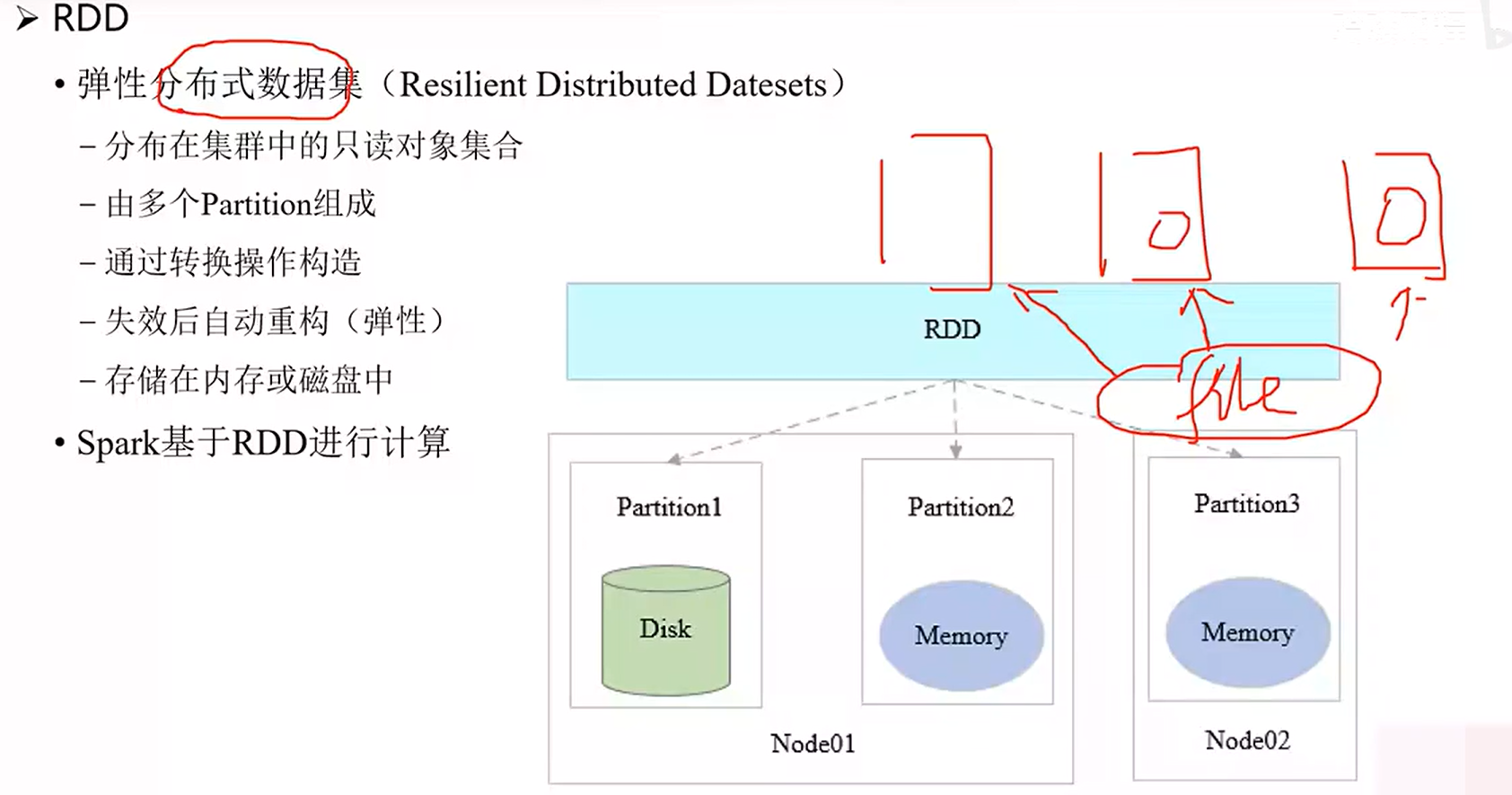
Spark基于弹性分布式数据集(RDD)进行运算。RDD是分布式存储在各个节点的数据集合,由文件拆分的数据块组成,具有只读特性。对RDD处理后需将结果保存为新的RDD。
-
-
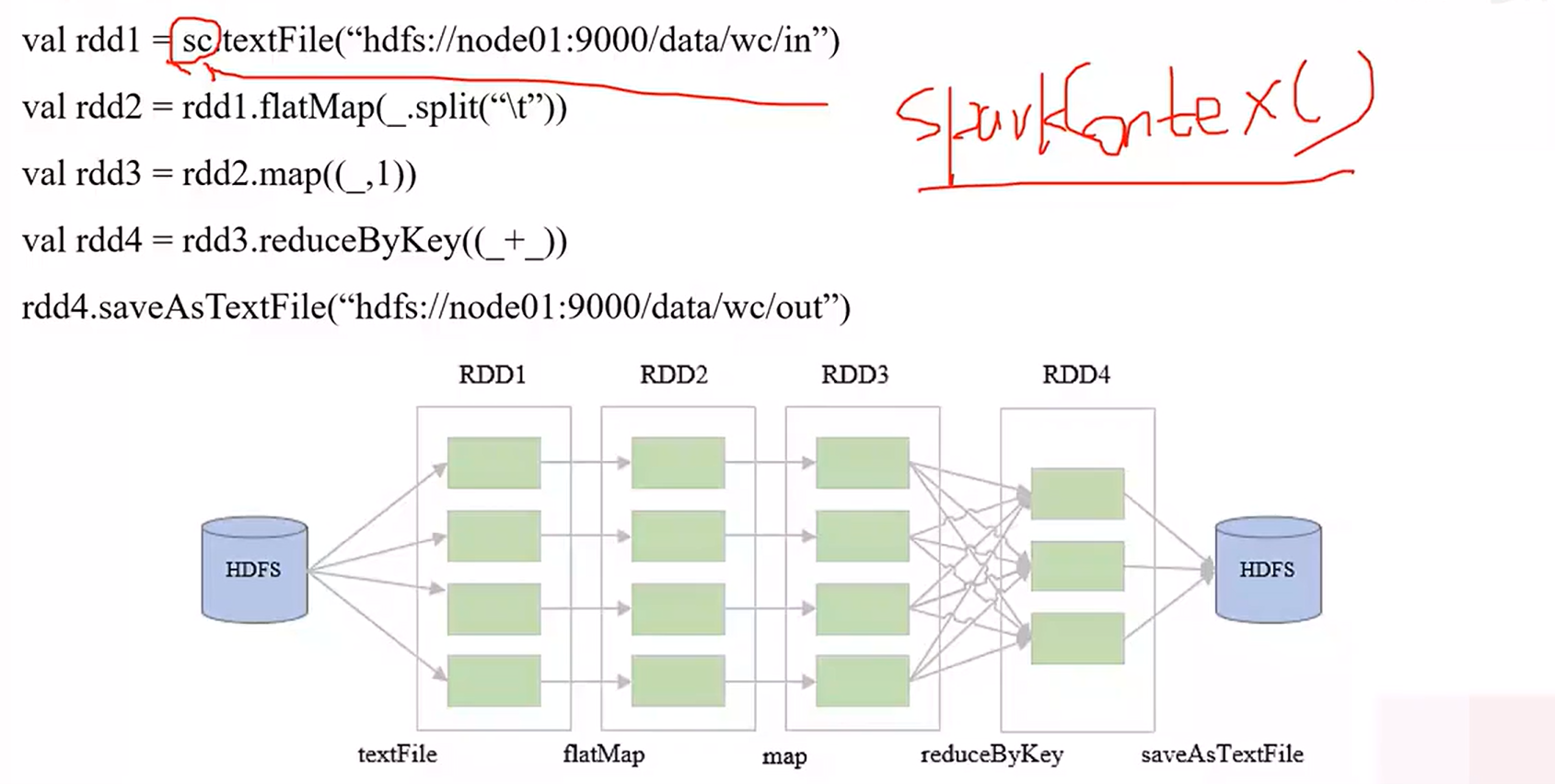
通过SparkContext对象的textFile算子可将HDFS数据文件读入并转化为RDD,这是后续处理的基础。
-
- Spark编程示例(词频统计)
-
利用flatMap算子按tab键拆分文本行,得到单词集合并保存为新RDD;再用map算子为每个单词标1。
-
-
使用reduceByKey算子按K值聚合,相同K值的value累加求和,最后将结果通过saveAsTextFile保存为文本文件输出到HDFS。
-
- Spark的DAG图及RDD关系
- Spark运算逻辑可绘制成有向无环图(DAG图)。文件的每个block是RDD的一个partition,RDD处理过程存在一对一和多对一的转换关系。
- 如RDD1处理形成RDD2是一对一转换;RDD3按K值reduce时需SHUFFLE操作,导致RDD4生成时是多对一关系,通过DAG图可清晰呈现RDD之间的关系。
- RDD的弹性特点
- RDD数据存于内存且只读,某个RDD的partition计算错误时,无需从源头重新读取数据,只需返回上一阶段重新处理即可恢复数据。
- 一对一转换的弹性恢复较容易,多对一转换因涉及SHUFFLE恢复相对麻烦,但仍比从头计算要好。
- 区分RDD的transformation和action
- transformation是对RDD进行转换构造,从一个RDD转换为新的RDD;action则是触发计算、生成或输出结果。
- 例如RDD的map操作是transformation,而saveAsTextFile、first、count、collect、forEach等触发结果输出的操作是action。
- RDD的操作及依赖关系和开发语言推荐
-
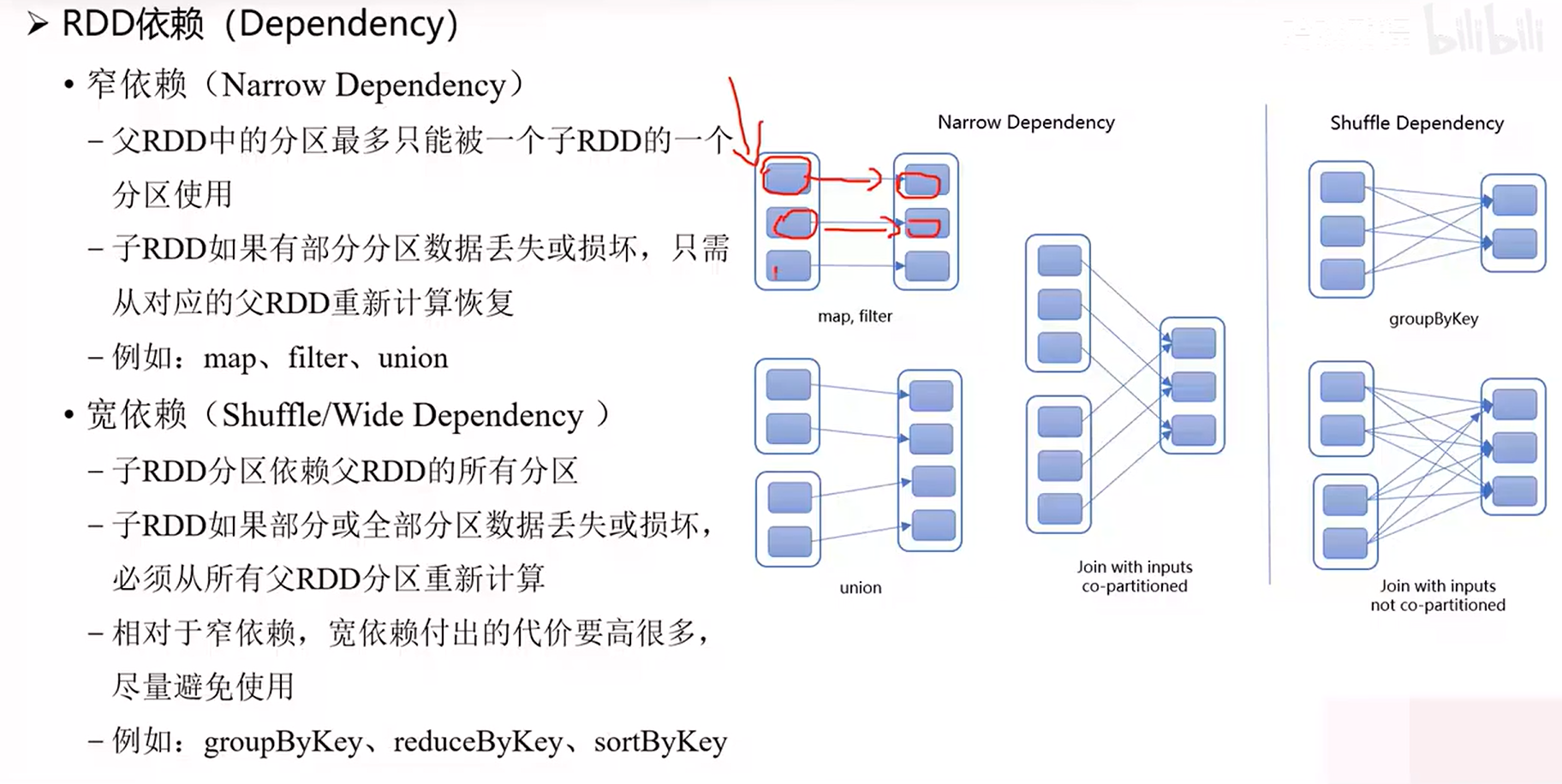
RDD操作会使RDD之间产生依赖关系,一对一转换形成窄依赖,多对一转换形成宽依赖。宽依赖因涉及SHUFFLE,数据恢复麻烦,应尽量避免使用产生宽依赖的算子,如groupByKey、reduceByKey、sortByKey等。
-
-
推荐使用SCALA语言进行Spark开发,因为Spark框架由SCALA开发,其语法简洁,使用SCALA开发更顺畅 。
-
运行模式
-
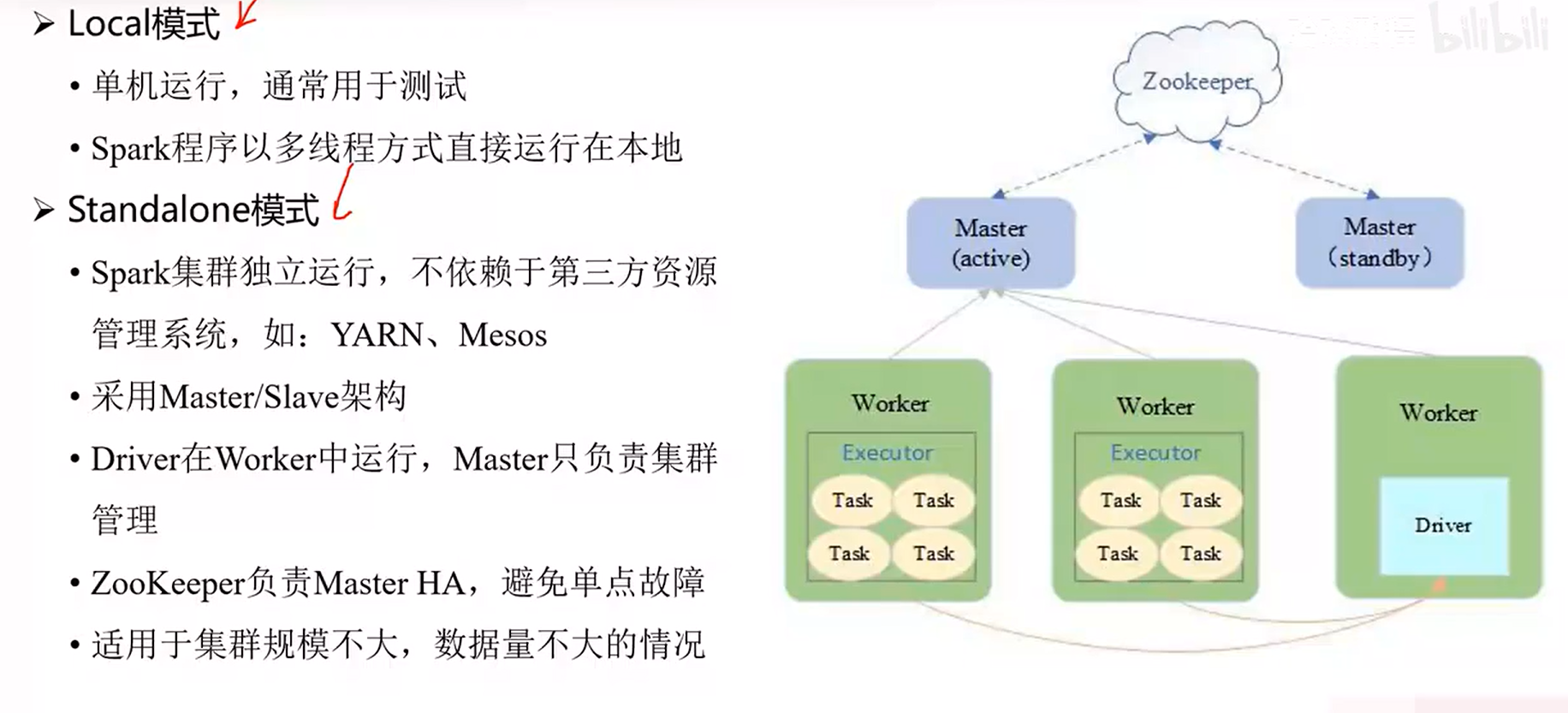
Spark运行模式概述:Spark提供多种运行模式,包括local模式、stand alone模式和on yarn模式。local模式用于本地单机测试,若代码在该模式下运行通过,可提交到其他模式。stand alone模式需搭建Spark集群,代码提交到集群运行。若没有Spark集群,只有Hadoop集群,则可使用on yarn模式提交代码运行。
-
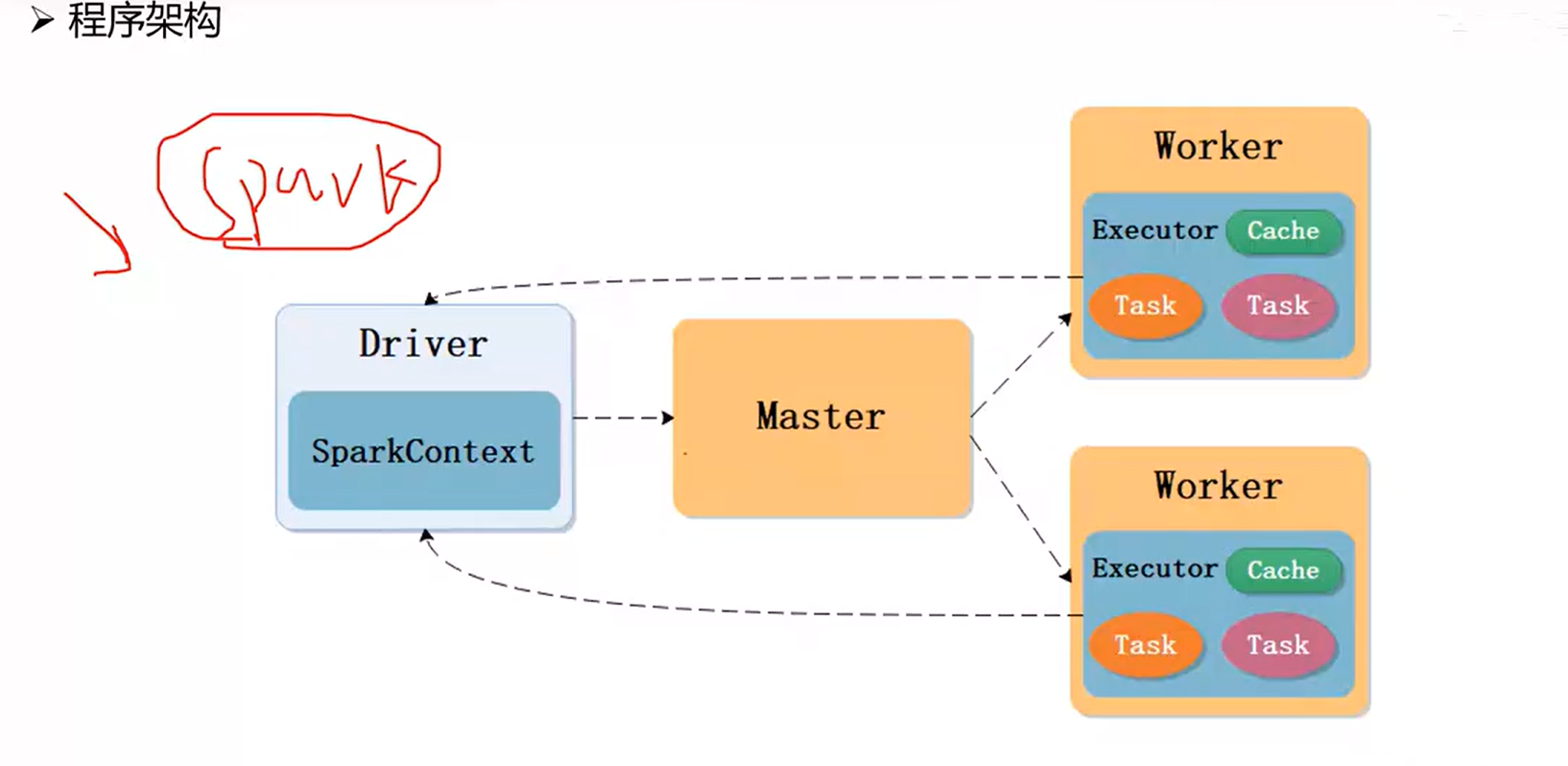
stand alone模式运行机制:在stand alone模式下,Spark集群主节点为master,从节点为worker。作业提交后,先申请资源运行driver。driver启动后解析作业,申请作业所需资源,master从worker中分配executor。分配好executor后,task分发到executor中执行,执行过程中task实时向driver汇报。所有task运行完成后,driver申请释放资源。
-
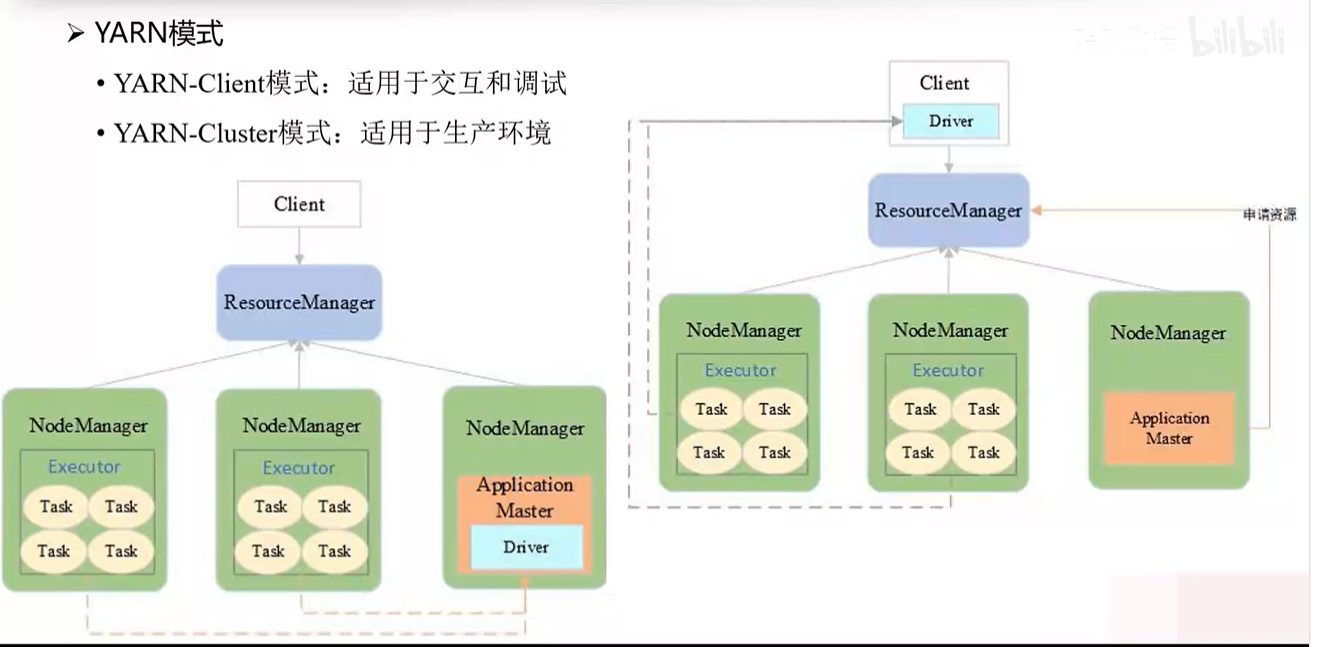
on yarn模式运行机制:在on yarn模式下,客户端向resource manager提交作业申请。resource manager在node manager中分配container,第一个container运行application master。由于Spark的管理进程是driver,yarn的管理进程是application master,通过在driver外面套一个application master的壳子进行协调。driver解析作业后,若需要资源,通知application master向resource manager申请。resource manager将申请到的资源(container)分配给application master,application master通知driver,driver把解析好的task分发到container中运行。task执行时实时向driver汇报,所有task完成后,driver通知application master释放资源,resource manager最终释放所有资源。注意在Spark框架中申请的资源叫executor,在yarn中叫container。
-
on yarn模式的两种子模式:on yarn模式包含cluster模式和client模式。cluster模式常用于生产环境;client模式用于交互和调试,它与cluster模式的主要区别在于,client模式将driver放到了客户端,这样driver实时监控task返回的信息能直接回显在客户端控制台上,便于观察作业运行情况,而cluster模式下driver在某一个从节点上,客户端无法直接看到作业运行信息。调试时用client模式,作业没问题后可使用on yarn模式上线生产。
执行流程
-
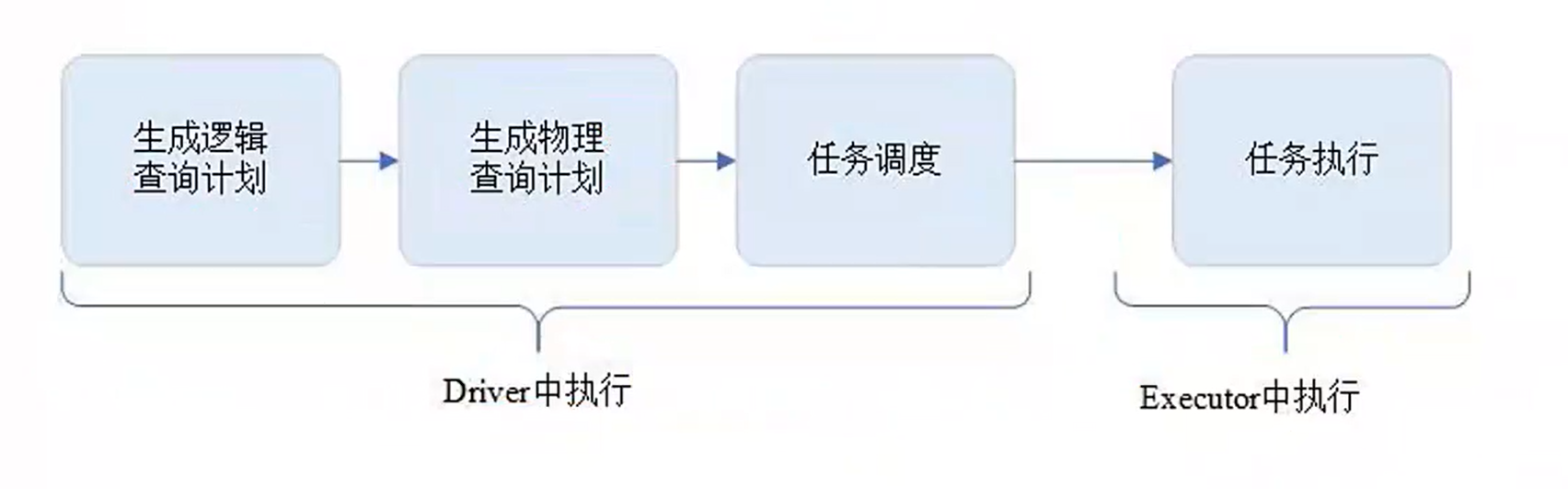
Spark执行流程概述:Spark执行从driver端开始,driver解析代码,先生成逻辑查询计划,再生成物理查询计划,随后将其打包成task集合,调度到executor执行,执行期间driver实时监控task信息并调度。
-
示例代码解析:以Scala编写的词频统计代码为例,借助SparkContext的textFile方法读取文本文件,经拆分单词、给单词标一、按K值聚合等操作,最终得到词频结果并输出保存。该代码运用链式编程,虽多行展示,但实际可写在一行。
-
逻辑查询计划:driver解析代码生成逻辑查询计划,此计划关注RDD(弹性分布式数据集)状态。在词频统计代码执行过程中,随着操作推进,RDD数据类型不断变化,逻辑查询计划会解析这些状态变化。
-
物理查询计划与stage划分
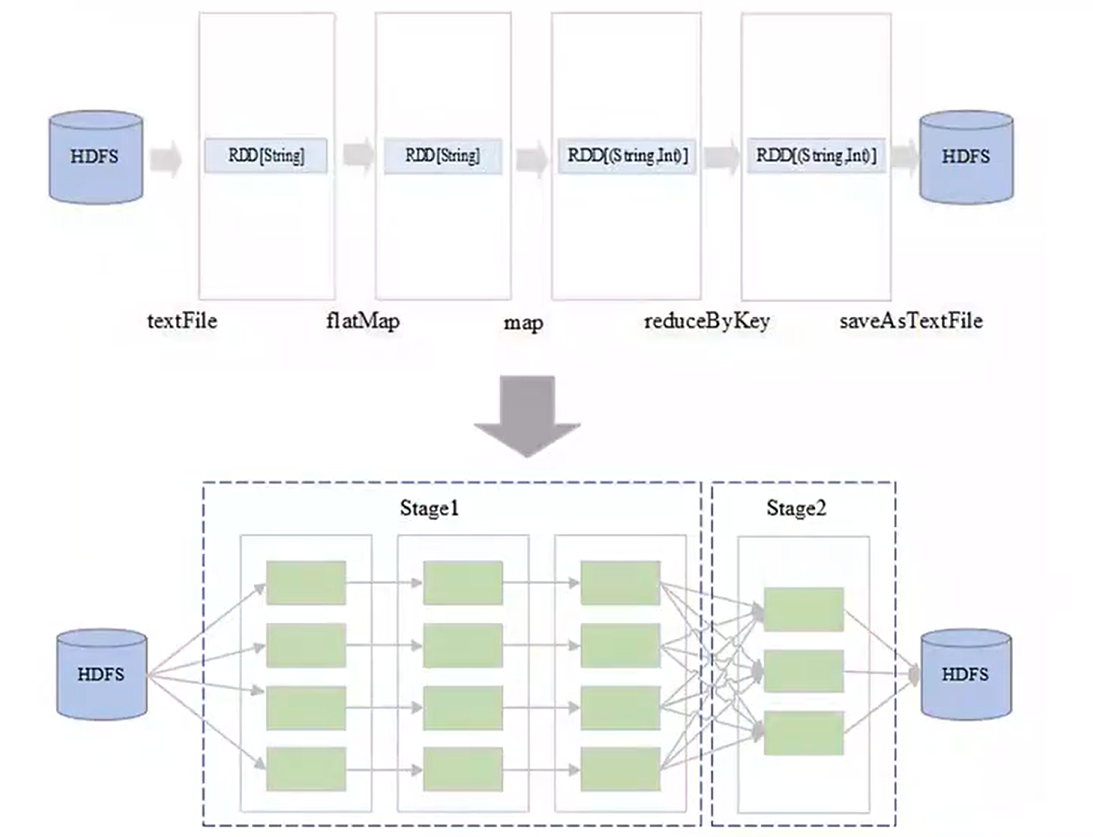
- 物理查询计划:物理查询计划关注底层数据状态,例如依据底层数据的block数量划分DAG图。在词频统计示例中,根据数据块划分RDD的partition,并依据操作特性(一对一转换或宽依赖操作)构建和转换RDD。
- stage划分依据:根据DAG图中RDD之间的宽窄依赖进行stage切分。窄依赖(如一对一转换)的操作可放在同一个stage,而宽依赖(如涉及shuffle操作)则会将RDD切分成新的stage。
-
任务调度过程:划分好stage后,每个stage内的操作可打包成task,每个partition可对应一个task。生成的task放入set集合,然后发送到executor执行,执行过程中task实时向driver汇报。
-
Spark任务监控页:Spark任务监控页在4040端口,通过访问Spark的IP地址加4040端口,可查看任务运行信息,如任务的DAG图、stage数量、每个stage的执行时间以及shuffle过程中的读写数据量等,这些信息对Spark任务调优至关重要。
评论记录:
回复评论: