

目录
蓝耘 GPU 智算云平台:开启 AI 算力新征程
在人工智能飞速发展的当下,算力已然成为推动技术创新与应用突破的核心要素。从图像识别到自然语言处理,从自动驾驶到药物研发,各类 AI 应用对算力的需求呈爆发式增长。蓝耘 GPU 智算云平台,作为算力服务领域的佼佼者,应运而生,为众多 AI 开发者、科研人员以及企业提供了强大且高效的算力支持,开启了 AI 算力的全新征程。
蓝耘 GPU 智算云平台基于行业领先的灵活基础设施及大规模的 GPU 算力资源,构建了一个现代化的、基于 Kubernetes 的云平台。这使其具备了诸多显著优势,能充分满足不同用户在 AI 领域的多样化需求。
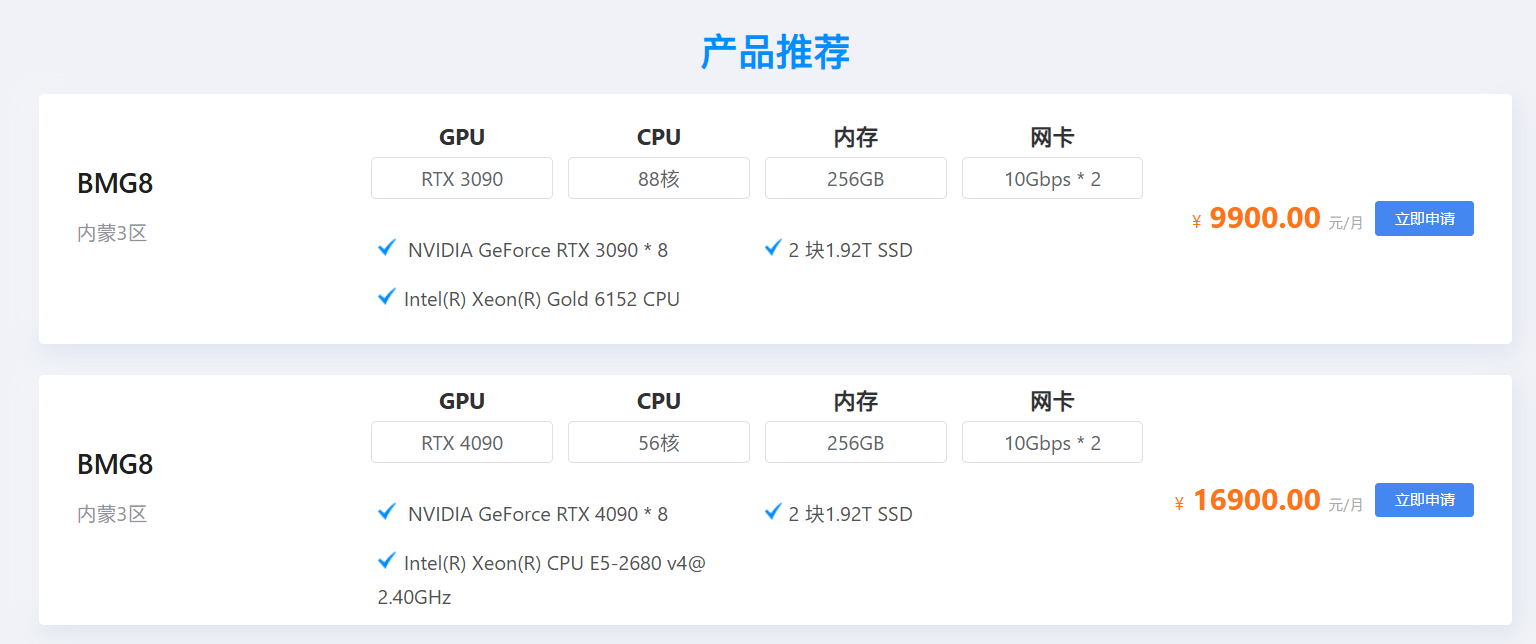
在算力资源方面,蓝耘 GPU 智算云平台拥有丰富且强大的 GPU 集群,支持多种主流 GPU 型号,如 NVIDIA A100、V100 等。以 A100 为例,其强大的计算能力能够在深度学习训练中,大幅提升计算速度,相比传统算力资源,可将训练时间缩短数倍甚至数十倍。在训练一个拥有数亿参数的大型语言模型时,使用蓝耘智算云平台搭载的 A100 GPU,原本可能需要数周的训练时间,现在借助其强大算力,短短几天即可完成,极大地提高了模型的迭代速度,让研究人员能够更快地验证模型的有效性和准确性,加速科研进程。
从功能特性来看,平台具备高度的开放性和灵活性。它支持多种 AI 框架,如 TensorFlow、PyTorch 等,以及各种开发工具。这意味着无论你是习惯使用 TensorFlow 进行图像识别项目开发,还是偏好 PyTorch 进行自然语言处理任务,都能在蓝耘智算云平台上找到适合自己的开发环境,实现资源的高效利用。同时,平台还提供了全流程的 AI 支持,涵盖了从数据预处理、模型构建、训练优化,到推理部署的每一个环节。以一个图像生成项目为例,用户可以在平台上完成从收集图像数据、进行数据清洗和标注,到构建生成对抗网络(GAN)模型、训练模型以及最终将模型部署到线上服务的全流程操作,真正实现一站式开发,大大提升了工作效率。
蓝耘 GPU 智算云平台还具有显著的成本优势。其速度可比传统云服务提供商快 35 倍,成本降低 30%。对于初创企业和科研团队来说,这无疑是极具吸引力的。在进行一个小型的 AI 创业项目时,使用传统云服务可能需要投入大量的资金用于算力租赁,而选择蓝耘智算云平台,不仅能够以更低的成本获取到更强大的算力,还能享受到高效的服务,帮助企业在有限的预算下实现技术突破,快速发展。
鉴于蓝耘 GPU 智算云平台在 AI 领域的卓越表现和巨大潜力,撰写本文旨在为广大读者提供一份详细的使用干货教程。无论你是 AI 领域的新手,渴望了解如何利用云平台开启自己的 AI 之旅;还是经验丰富的开发者,希望进一步挖掘蓝耘智算云平台的高级功能,提升工作效率,本文都将为你提供全面且深入的指导,帮助你充分发挥蓝耘 GPU 智算云平台的优势,在 AI 的世界中畅游。
前期准备:注册与登录
在开启蓝耘 GPU 智算云平台的使用之旅前,首先要完成注册与登录的前期准备工作。这是进入平台、获取算力资源的基础步骤,每一个环节都至关重要,下面将为你详细介绍。
注册流程
1.访问官方网站:打开你常用的浏览器,在地址栏中输入蓝耘 GPU 智算云平台的官方网址(https://cloud.lanyun.net/ ),然后按下回车键,即可进入平台的官方首页。此时,你会看到一个充满科技感与现代设计风格的页面,展示着平台的各项优势与服务。
2.点击注册按钮:在首页的显著位置,通常位于页面右上角,你会找到 “注册” 按钮。这个按钮的设计醒目,以吸引用户的注意力,引导新用户开启注册流程。点击该按钮后,页面将跳转到注册页面。
3.填写注册信息:
- 邮箱地址:在注册页面,首先需要填写一个有效的邮箱地址。这个邮箱将作为你在平台的登录账号之一,同时也是接收平台通知、密码找回等重要信息的渠道。确保你填写的邮箱是你经常使用且能够正常接收邮件的,例如你的工作邮箱或常用的个人邮箱。
- 设置密码:设置一个强密码,长度至少为 8 位,包含字母(大小写)、数字和特殊字符,如 “Abc@123456”。强密码能够有效保护你的账号安全,防止被他人轻易破解。
- 确认密码:再次输入刚才设置的密码,以确保密码输入的准确性。这一步骤是为了避免因密码输入错误而导致后续登录或使用过程中出现问题。
- 验证码:为了验证你是真实用户而非机器人,平台会提供一个验证码输入框。验证码通常是由数字和字母组成的字符串,显示在输入框旁边的图片中。仔细观察图片中的验证码,然后在输入框中准确输入。如果看不清验证码,可以点击图片刷新,获取新的验证码。
4.阅读并同意用户协议:在注册页面的下方,通常会有一份用户协议和隐私政策的链接。请务必仔细阅读这些条款,了解平台对你使用服务的各项规定以及对你个人信息的处理方式。在阅读完成后,勾选 “我已阅读并同意用户协议和隐私政策” 的复选框,表示你接受这些条款。
5.完成注册:当你填写完所有注册信息并勾选同意用户协议后,点击 “注册” 按钮。平台将对你输入的信息进行验证,如果信息填写正确且符合要求,你将收到一条注册成功的提示信息,同时平台会向你注册时填写的邮箱发送一封验证邮件。打开你的邮箱,找到来自蓝耘智算云平台的邮件,点击邮件中的验证链接,完成邮箱验证,至此注册流程全部完成。
登录步骤
- 返回平台首页:完成注册后,如果你没有自动跳转到平台首页,可以再次在浏览器中输入平台官方网址,回到平台首页。
- 点击登录按钮:在首页右上角,找到 “登录” 按钮,点击它进入登录页面。
- 输入登录信息:在登录页面,输入你注册时填写的邮箱地址和设置的密码。如果你使用的是其他登录方式,如手机号登录,输入相应的手机号和密码。
- 验证码登录(可选):为了进一步保障账号安全,平台可能会要求你输入验证码进行登录。验证码会以短信的形式发送到你注册时预留的手机号上,或者显示在页面上的图片中(如果是邮箱登录且开启了图形验证码)。输入正确的验证码后,点击 “登录” 按钮。
- 进入平台控制台:如果你的登录信息准确无误,你将成功进入蓝耘 GPU 智算云平台的控制台。在这里,你将看到平台提供的各种功能和服务,如创建计算实例、管理资源、查看账单等,从此开启你的智算之旅。
登录注意事项
- 密码安全:务必牢记你的登录密码,不要将密码告知他人。如果担心忘记密码,可以将密码记录在安全的地方,如密码管理工具中。定期更换密码也是一个良好的安全习惯,建议每隔一段时间(如 3 - 6 个月)更换一次密码,以降低账号被盗的风险。
- 验证码保护:收到验证码后,不要在不安全的环境中输入,如公共网络或不可信的设备上。验证码通常具有时效性,一般在几分钟内有效,所以请尽快使用。如果验证码过期,可以重新获取。
- 多设备登录:如果你需要在多台设备上登录蓝耘智算云平台,确保这些设备都是安全可信的。避免在公共电脑或他人设备上登录,以防账号信息被窃取。如果在不可信设备上登录后,及时退出登录并修改密码。
- 忘记密码处理:如果不慎忘记密码,在登录页面点击 “忘记密码” 链接。按照系统提示,输入你注册时的邮箱地址或手机号,平台将向你发送密码重置链接或验证码。根据收到的信息,重置你的密码,确保新密码的安全性和易记性。
实例创建:挑选合适的算力
当你成功登录蓝耘 GPU 智算云平台后,接下来的关键步骤便是创建计算实例,这是获取算力资源、开展 AI 项目的重要环节。在创建过程中,合理选择 GPU 资源、操作系统镜像,以及设置实例名称和密码等信息,都直接关系到后续计算任务的顺利执行和效率高低。
选择 GPU 资源
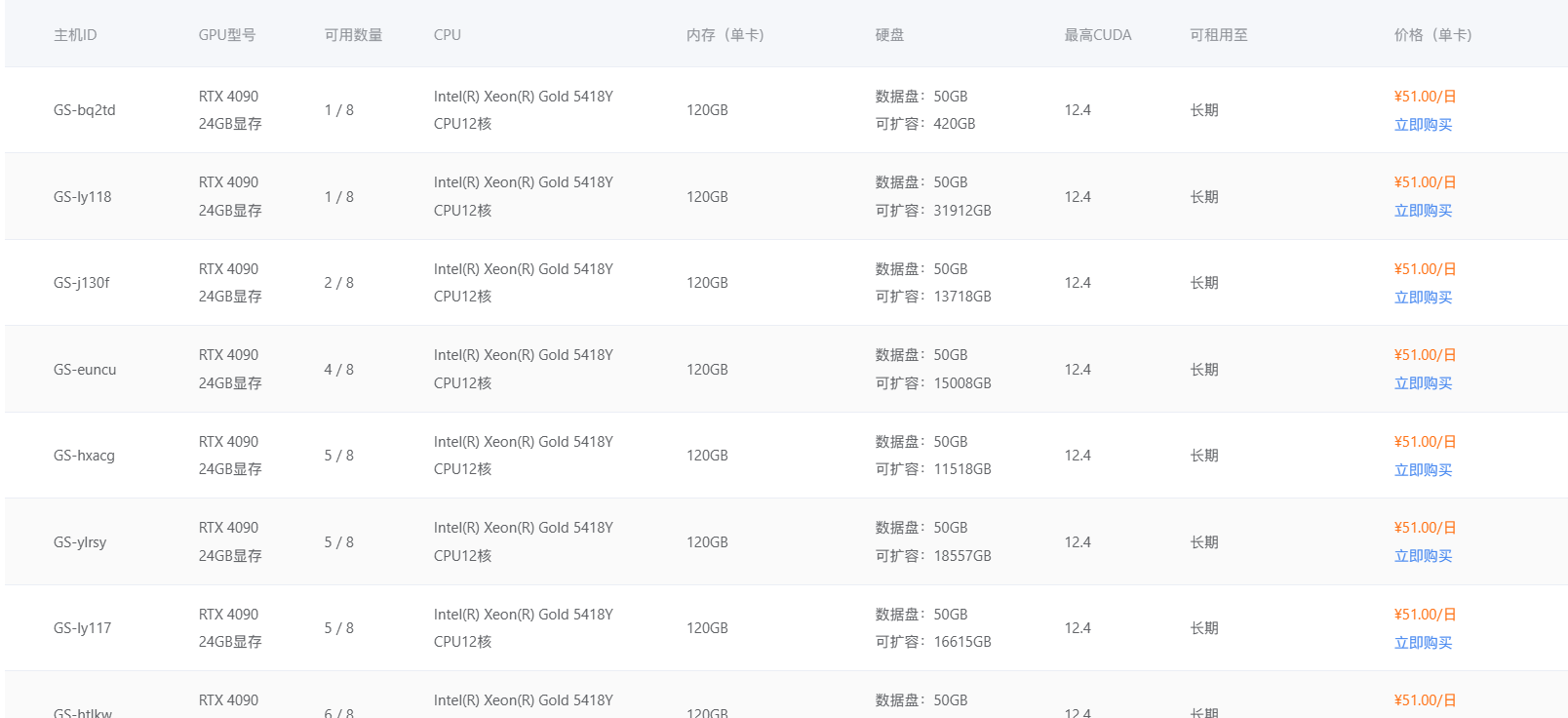
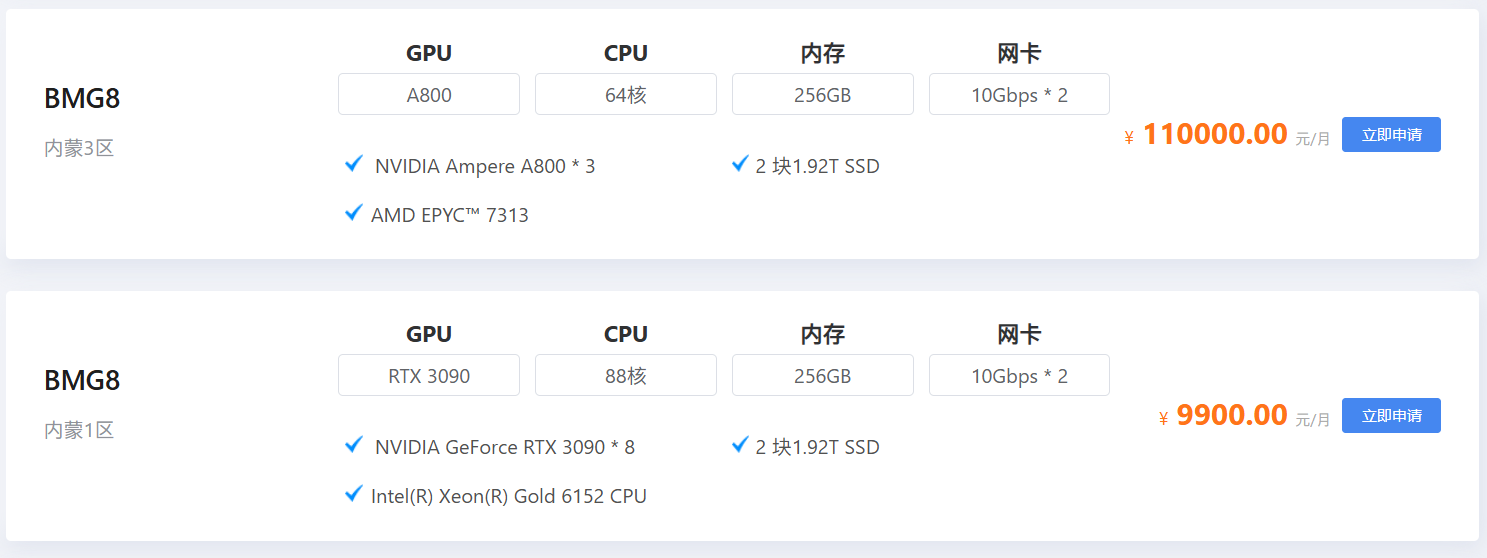
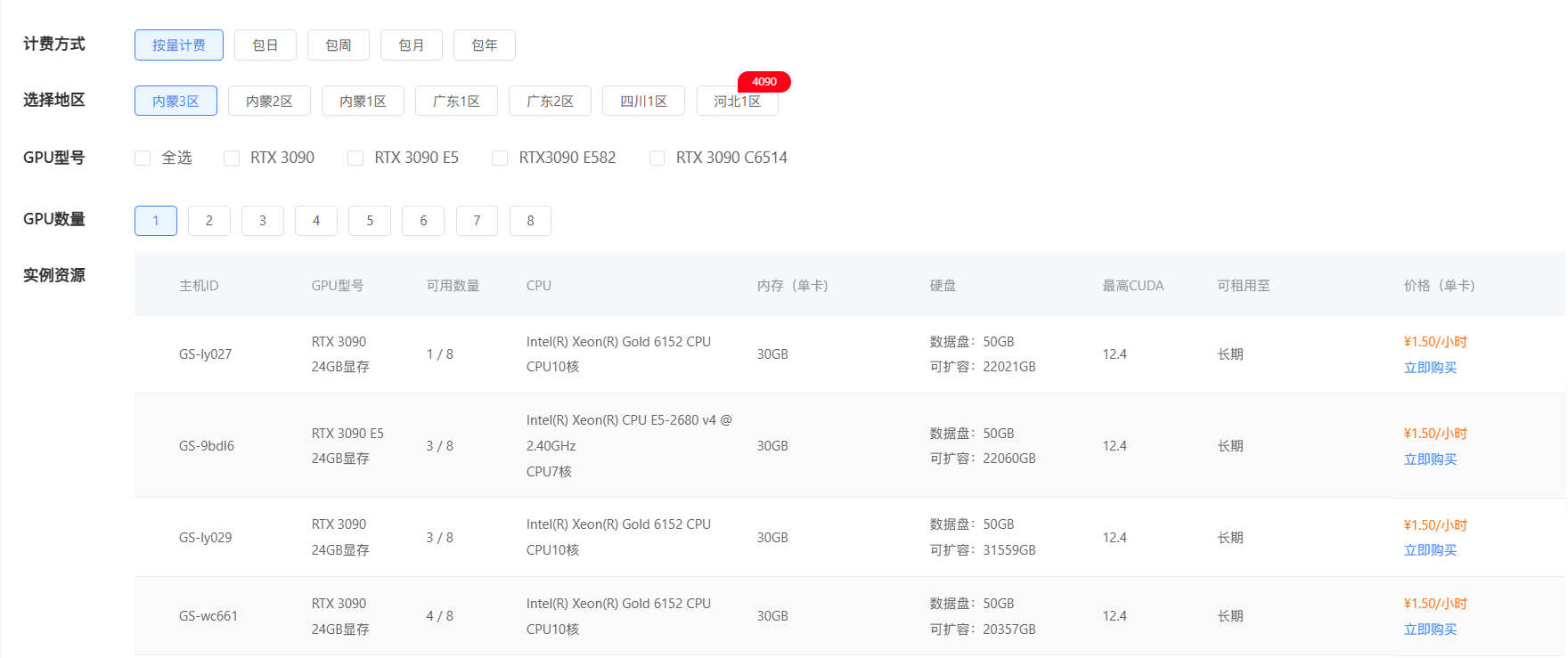
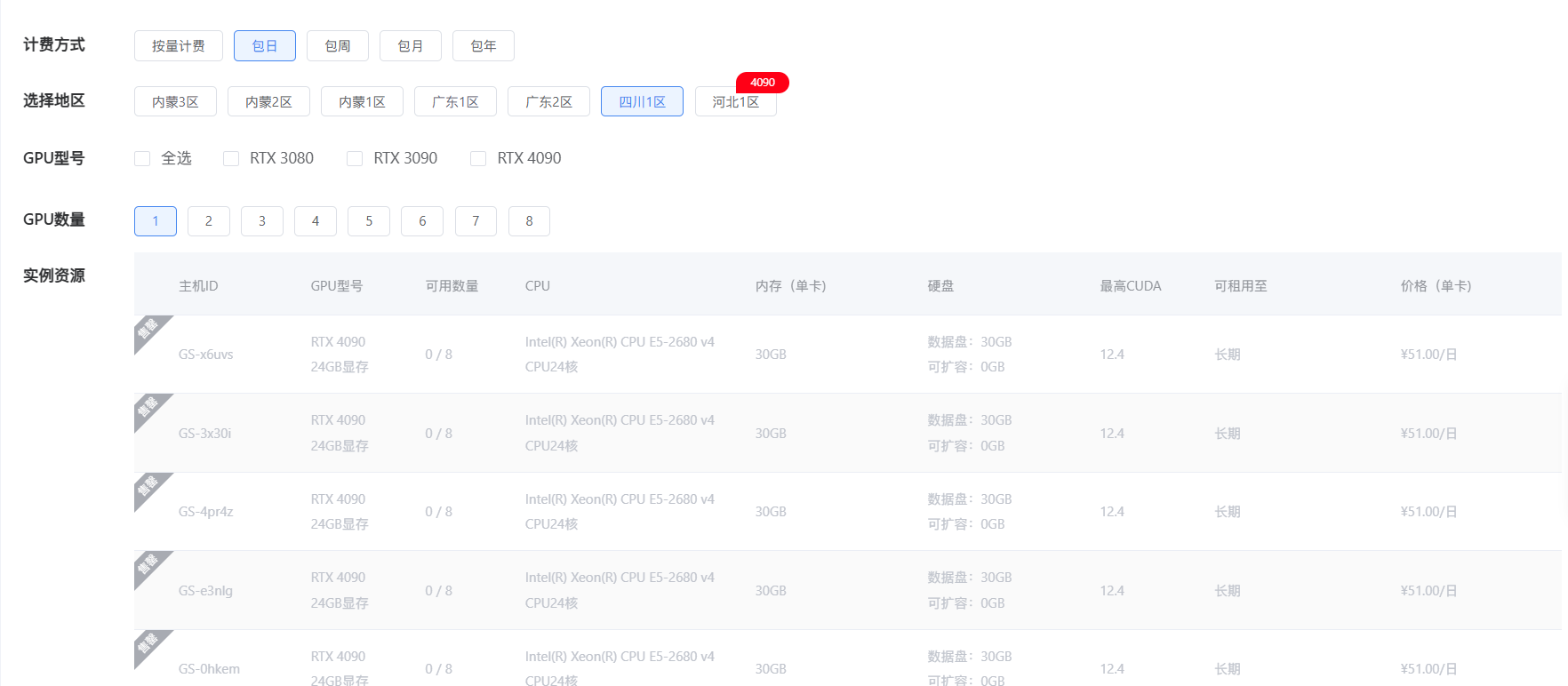
- 了解 GPU 型号:蓝耘 GPU 智算云平台提供了多种主流的 GPU 型号,如 NVIDIA A100、V100、RTX 3090 等,每种型号都有其独特的性能特点和适用场景。NVIDIA A100 采用了先进的架构和工艺,拥有高达 80GB 的显存和强大的计算核心,在处理大规模深度学习训练任务,如训练大型语言模型、复杂的图像生成模型时,能够凭借其卓越的并行计算能力,显著缩短训练时间,提高模型的训练效率。而 RTX 3090 虽然在显存容量和计算能力上相对 A100 略逊一筹,但对于一些对显存要求不是特别高的深度学习任务,如常见的图像识别、小型自然语言处理项目,它以相对较低的成本提供了不错的计算性能,是初学者和预算有限的用户的良好选择。
- 确定 GPU 数量:根据你的计算任务的规模和复杂度来确定所需的 GPU 数量。如果是进行简单的深度学习实验,如一个小型的图像分类项目,使用 1 - 2 块 GPU 可能就足够了。但如果是进行大规模的分布式训练,如训练一个拥有数十亿参数的超大型语言模型,可能需要 8 块甚至更多的 GPU 协同工作,以满足巨大的计算量需求。在实际选择时,你可以参考项目的文档、前人的经验,或者进行一些小规模的测试来确定合适的 GPU 数量。
- 考虑显存需求:显存是 GPU 存储数据的地方,对于深度学习任务来说,显存的大小直接影响到能够处理的数据规模和模型的复杂度。如果你的模型较大,或者需要处理高分辨率的图像、长时间的视频数据等,就需要选择显存较大的 GPU。在训练一个高分辨率图像生成模型时,可能需要使用显存为 80GB 的 NVIDIA A100 GPU,以确保模型能够顺利加载和处理大量的图像数据,避免因显存不足而导致训练中断或性能下降。
选择操作系统镜像
- 常见操作系统镜像:蓝耘智算云平台通常提供多种操作系统镜像供用户选择,如 Ubuntu、CentOS 等 Linux 发行版,以及 Windows Server 系统(部分场景支持)。Ubuntu 以其丰富的软件源、良好的社区支持和对深度学习框架的友好性而受到广泛欢迎。许多深度学习框架,如 TensorFlow、PyTorch 等,都在 Ubuntu 系统上进行了优化,能够充分发挥其性能优势。CentOS 则以其稳定性和长期支持而著称,适合对系统稳定性要求较高的生产环境和科研项目。
- 根据项目需求选择:如果你的项目依赖于特定的软件包或工具,而这些软件包在某个操作系统上有更好的兼容性和性能表现,那么就应该选择该操作系统镜像。如果你使用的是基于 Python 的深度学习框架,并且项目中需要使用一些特定的 Python 库,而这些库在 Ubuntu 系统上有更便捷的安装和配置方式,那么选择 Ubuntu 镜像会是一个明智的选择。此外,如果你对某个操作系统更为熟悉,使用起来更加得心应手,也可以优先选择该操作系统,以提高开发效率。
设置实例名称和密码
- 实例名称:为你的计算实例取一个有意义且易于识别的名称,例如 “Image_Recognition_Instance” 或 “NLP_Project_Instance”。这样在后续管理多个实例时,能够快速准确地找到你需要的实例,避免混淆。实例名称应遵循平台的命名规则,一般要求长度适中,不能包含特殊字符或非法字符。
- 登录密码:设置一个强密码来保护你的实例安全。密码长度至少为 8 位,包含大小写字母、数字和特殊字符,如 “Abc@123456”。避免使用简单易猜的密码,如生日、电话号码等。同时,要妥善保管好密码,不要将其泄露给他人。如果担心忘记密码,可以将密码记录在安全的地方,如密码管理工具中。
创建实例的具体操作步骤
- 进入实例创建页面:登录蓝耘 GPU 智算云平台控制台后,在界面中找到 “实例管理” 或 “创建实例” 相关的入口,点击进入实例创建页面。这个页面通常会以直观的方式展示各种创建选项和参数设置区域。
- 选择 GPU 资源:在实例创建页面的 “GPU 资源” 选项中,从下拉菜单或列表中选择你需要的 GPU 型号,如 NVIDIA A100。然后,在 “GPU 数量” 输入框中填写你所需的 GPU 数量,比如 4。
- 选择操作系统镜像:在 “操作系统镜像” 选项中,浏览可供选择的镜像列表,找到你需要的操作系统镜像,如 Ubuntu 20.04,点击进行选择。
- 设置实例名称和密码:在相应的输入框中,输入你为实例取的名称和设置的密码。
- 其他配置(可选):根据你的需求,还可以进行一些其他配置,如选择存储容量、网络带宽等。对于需要频繁读写大量数据的项目,可以选择较大的存储容量和较高的网络带宽;对于对网络延迟要求较高的实时推理任务,确保选择足够的网络带宽以保障数据传输的及时性。
- 确认并创建:仔细检查你所选择和设置的各项参数,确保准确无误后,点击 “创建” 或 “立即创建” 按钮。平台将开始为你分配资源并创建计算实例,这个过程可能需要几分钟时间,你可以在实例管理界面查看实例的创建进度和状态。当实例状态显示为 “运行中” 时,说明实例创建成功,你可以开始使用该实例进行计算任务了。
环境搭建:代码环境初构建
当你成功创建计算实例后,接下来就需要进行环境搭建,这是在蓝耘 GPU 智算云平台上运行代码、开展深度学习任务的关键准备工作。下面将从连接计算实例、安装系统依赖库、搭建 Python 虚拟环境以及安装深度学习框架及相关库这几个重要方面,为你详细介绍环境搭建的步骤和方法。
(一)连接计算实例
通过 SSH(Secure Shell)协议连接到计算实例是与实例进行交互的常用方式。在 Linux 或 macOS 系统中,你可以使用终端进行连接;在 Windows 系统中,你可以使用 PuTTY、Xshell 等 SSH 客户端工具。以下是使用命令行连接的具体步骤:
- 获取连接信息:在蓝耘 GPU 智算云平台的控制台中,找到你创建的计算实例,查看其 “连接信息”,这里会提供服务器地址、端口号和用户名等信息。例如,服务器地址为 “192.168.1.100”,端口号为 “22”,用户名为 “ubuntu”。
- 使用 SSH 命令连接:打开终端或 SSH 客户端,输入以下命令进行连接:
- 输入密码:按下回车键后,系统会提示你输入该实例的登录密码。输入你在创建实例时设置的密码(输入密码时,终端不会显示任何字符,这是正常现象,只需正常输入并回车即可)。
- 成功连接:如果密码输入正确,你将成功连接到计算实例,此时终端会显示实例的命令行提示符,例如 “ubuntu@instance - 1:~$”,表示你已进入实例的操作环境,可以开始执行后续的操作命令。
(二)安装系统依赖库
在实例中运行深度学习任务,通常需要安装一些必要的系统依赖库,这些库为深度学习框架和相关工具提供了基础支持。以 Ubuntu 系统为例,使用apt - get命令来安装依赖库,以下是一些常见的依赖库及其安装命令:
- 安装build - essential:这是一组开发工具和库的集合,包含了编译 C 和 C++ 代码所需的工具,如 GCC 编译器等。许多深度学习库在编译安装时依赖这些工具。安装命令如下:
- 安装libcupti - dev:CUDA Profiling Tools Interface(CUpti)是 NVIDIA CUDA 工具包的一部分,它提供了用于性能分析和调试的接口。对于深度学习任务,特别是在优化 GPU 性能时,这个库非常有用。安装命令如下:
sudo apt - get install libcupti - dev- 安装libopenblas - dev:OpenBLAS 是一个优化的 BLAS(Basic Linear Algebra Subprograms)库,用于高效地执行矩阵运算等线性代数操作。深度学习框架在进行张量计算时,常常依赖 OpenBLAS 来提高计算效率。安装命令如下:
sudo apt - get install libopenblas - dev
(三)Python 虚拟环境搭建
Python 虚拟环境可以为不同的项目创建独立的 Python 运行环境,避免不同项目之间的依赖冲突。这里介绍两种常见的创建和管理 Python 虚拟环境的工具:venv和conda。
1.使用venv创建虚拟环境:
- 安装venv(如果未安装):在大多数 Python 3.3 及以上版本中,venv已经作为标准库包含在内。如果你的系统中没有安装,可以使用以下命令安装:
sudo apt - get install python3 - venv- 创建虚拟环境:选择一个合适的目录来存放虚拟环境,例如在用户主目录下创建一个名为 “my_venv” 的虚拟环境,命令如下:
python3 - m venv my_venv- 激活虚拟环境:在 Linux 或 macOS 系统中,使用以下命令激活虚拟环境:
source my_venv/bin/activate在 Windows 系统中,使用以下命令激活:
my_venv\Scripts\activate激活后,命令行提示符会发生变化,显示当前使用的虚拟环境名称,例如 “(my_venv) ubuntu@instance - 1:~$”,表示你已进入虚拟环境,可以在其中安装项目所需的 Python 库,而不会影响系统全局的 Python 环境。
- 退出虚拟环境:当你完成项目操作后,使用以下命令退出虚拟环境:
deactivate
2.使用conda创建虚拟环境:
- 安装conda:首先需要从 Anaconda 或 Miniconda 官网下载适合你系统的安装包,并按照安装向导进行安装。安装完成后,conda命令将添加到系统路径中。
- 创建虚拟环境:使用以下命令创建一个名为 “my_conda_env”,Python 版本为 3.8 的虚拟环境:
conda create -n my_conda_env python = 3.8- 激活虚拟环境:在 Linux 或 macOS 系统中,使用以下命令激活:
conda activate my_conda_env在 Windows 系统中,同样使用上述命令激活。激活后,命令行提示符会显示当前激活的虚拟环境名称。
- 退出虚拟环境:使用以下命令退出:
conda deactivate
(四)深度学习框架及相关库安装
深度学习框架是实现深度学习任务的核心工具,蓝耘 GPU 智算云平台支持多种主流的深度学习框架,如 TensorFlow 和 PyTorch。以下以这两个框架为例,介绍它们以及 DeepSeek 相关库的安装方法。
1.安装 TensorFlow:在激活的虚拟环境中,使用pip命令安装 TensorFlow。如果你的计算实例配备了 GPU,并且希望使用 GPU 加速计算,可以安装 GPU 版本的 TensorFlow;如果没有 GPU,或者只进行简单的测试和学习,也可以安装 CPU 版本。
- 安装 GPU 版本(假设 CUDA 版本为 11.2):
pip install tensorflow - gpu==2.8.02.安装 CPU 版本:同样在虚拟环境中,根据你的 CUDA 版本和需求,从 PyTorch 官网获取相应的安装命令。例如,安装 CUDA 11.3 版本的 PyTorch:
pip install torch torchvision torchaudio --index - url https://download.pytorch.org/whl/cu1133.安装 DeepSeek 相关库:如果你的项目需要使用 DeepSeek 相关的模型或工具,根据其官方文档的说明进行安装。假设 DeepSeek 库的名称为 “deepseek - toolkit”,使用以下命令安装:
pip install deepseek - toolkit在安装过程中,可能会遇到网络问题导致安装失败。此时,可以尝试更换 pip 源,例如使用清华大学的镜像源:
pip install - i https://pypi.tuna.tsinghua.edu.cn/simple [库名称]通过以上步骤,你已经成功完成了在蓝耘 GPU 智算云平台上的环境搭建,包括连接计算实例、安装系统依赖库、搭建 Python 虚拟环境以及安装深度学习框架和相关库,为后续的深度学习任务开发和运行奠定了坚实的基础。
模型加载与推理:让模型运转起来
在完成环境搭建后,就进入到模型加载与推理的关键环节。这一步骤是将训练好的模型应用于实际任务的核心操作,通过加载模型并对输入数据进行推理,从而得到我们期望的结果。下面将详细介绍在蓝耘 GPU 智算云平台上进行模型加载与推理的具体步骤和方法。
(一)本地模型加载
将本地训练好的模型加载到蓝耘平台是进行推理的首要步骤。以 PyTorch 框架为例,假设你的模型保存在本地的model.pth文件中,并且模型定义在model.py文件里,以下是加载模型的代码示例:
在上述代码中,首先导入必要的库torch以及定义模型的模块model。然后创建模型实例model,使用torch.load函数加载本地的模型参数文件model.pth,并通过model.load_state_dict方法将加载的参数加载到模型中。最后,将模型设置为评估模式model.eval(),这一步很重要,因为在评估模式下,模型会关闭一些训练时的操作,如随机失活(dropout)等,以确保推理结果的准确性。
在设置文件路径时,要确保路径的准确性。如果模型文件不在当前工作目录下,需要使用绝对路径或相对路径正确指向模型文件。例如,如果模型文件在/home/user/models/目录下,那么加载模型的代码应改为:
model.load_state_dict(torch.load('/home/user/models/model.pth'))
(二)输入数据预处理
在进行推理之前,需要对输入数据进行清洗、转换等预处理操作,以确保数据的格式和内容符合模型的输入要求。以图像数据为例,假设使用的是一个图像分类模型,输入图像的尺寸要求为 224x224,并且需要进行归一化处理。以下是使用torchvision库进行数据预处理的代码片段:
在这段代码中,首先使用transforms.Compose方法将多个预处理操作组合在一起。transforms.Resize用于调整图像大小,transforms.ToTensor将图像转换为 PyTorch 的张量格式,transforms.Normalize进行归一化处理,通过指定均值和标准差,将图像数据映射到一个合适的范围。最后,使用unsqueeze(0)方法为图像张量添加一个批次维度,因为模型通常期望输入数据是一个批次的形式。
(三)进行推理
在完成模型加载和数据预处理后,就可以使用加载的模型对预处理后的数据进行推理了。以下是使用 PyTorch 模型进行推理的代码示例:
在这段代码中,使用with torch.no_grad()上下文管理器,这是因为在推理过程中不需要计算梯度,使用该管理器可以减少内存消耗并提高推理速度。然后,将预处理后的图像数据preprocessed_image输入到模型model中,得到模型的输出outputs。outputs通常是一个包含各个类别的预测分数的张量。最后,使用torch.max函数找到预测分数最高的类别索引predicted,这就是模型对输入图像的预测结果。
(四)API 调用实现推理
如果蓝耘平台提供推理 API,使用 API 进行推理可以简化流程,并且便于与其他系统集成。假设蓝耘平台提供的推理 API 地址为https://api.lanyun.com/inference,以下是使用 Python 的requests库进行 API 调用实现推理的示例代码:
在上述代码中,首先将预处理后的图像数据preprocessed_image转换为列表形式,并封装成一个字典data。然后使用requests.post方法向 API 发送 POST 请求,请求的 URL 为https://api.lanyun.com/inference,并将数据以 JSON 格式传递。如果 API 返回的状态码为 200,表示请求成功,此时解析响应的 JSON 数据,获取预测结果并打印。如果状态码不为 200,则打印错误信息。
在使用 API 进行推理时,需要注意 API 的请求方式(如 GET、POST 等)、参数设置(包括数据格式、请求头信息等)以及错误处理。不同的 API 可能有不同的要求,要仔细阅读蓝耘平台提供的 API 文档,确保请求的正确性和有效性。
数据处理与准备:为模型提供优质 “燃料”
在深度学习任务中,数据处理与准备是至关重要的环节,它如同为模型提供优质的 “燃料”,直接影响模型的性能和效果。以下将详细介绍文本数据清洗与预处理以及数据加载与批量处理的相关内容。
(一)文本数据清洗与预处理
针对文本数据,去除噪声、分词、标注等预处理步骤是必不可少的。下面结合代码示例展示操作过程。
1.去除噪声:原始文本数据中通常包含各种噪声,如标点符号、特殊字符、HTML 标签等,这些噪声会干扰模型的学习,需要予以去除。以 Python 为例,使用re库进行正则表达式操作来去除标点符号和特殊字符。
在这段代码中,re.sub(r'[^\w\s]', '', text)表示使用正则表达式将文本中除了字母、数字和空格之外的字符替换为空字符串,从而实现去除标点符号和特殊字符的目的。运行上述代码,输出结果为:Hello world This is a sample text with some special characters @#$%^&* 。
如果文本数据中包含 HTML 标签,可使用BeautifulSoup库进行处理。假设从网页上获取了一段包含 HTML 标签的文本:
Hello, world! This is a sample text with HTML tags.
"在这个示例中,BeautifulSoup库将 HTML 文本解析成树形结构,然后使用get_text()方法获取其中的纯文本内容,去除了 HTML 标签。运行结果为:Hello, world! This is a sample text with HTML tags.
2.分词:分词是将文本拆分为单个词语或标记的过程,这是文本处理的关键步骤,常用的分词工具包括 NLTK 和 spaCy。以 NLTK 为例,展示分词操作:
上述代码中,nltk.word_tokenize(text)函数对输入文本进行分词操作,将文本拆分成一个个单词。运行结果为:['Natural', 'language', 'processing', 'is', 'an', 'important', 'field', 'in', 'artificial', 'intelligence', '.'] 。
3.标注:标注是为文本中的词语或短语添加语义标签,如词性标注、命名实体识别等,有助于模型更好地理解文本的语义信息。使用 NLTK 进行词性标注的示例如下:
在这段代码中,nltk.pos_tag(tokens)函数对分词后的单词列表进行词性标注,为每个单词标注其词性。运行结果为:[('The', 'DT'), ('dog', 'NN'), ('runs', 'VBZ'), ('fast', 'RB'), ('.', '.')] ,其中DT表示限定词,NN表示名词,VBZ表示动词第三人称单数形式,RB表示副词,.表示标点符号。
(二)数据加载与批量处理
将处理好的数据加载到模型中进行训练或推理,并进行批量处理以提高效率是数据处理的后续关键步骤。下面给出代码示例。
在深度学习中,通常使用数据加载器(DataLoader)来加载数据。以 PyTorch 为例,假设已经有处理好的图像数据集,并且数据集的结构为每个类别对应一个文件夹,文件夹中包含该类别的图像文件。首先,定义一个自定义数据集类:
- import torch
- from torch.utils.data import Dataset
- from PIL import Image
- import os
-
-
- class CustomImageDataset(Dataset):
- def __init__(self, root_dir, transform=None):
- self.root_dir = root_dir
- self.transform = transform
- self.classes = sorted(os.listdir(root_dir))
- self.class_to_idx = {cls_name: i for i, cls_name in enumerate(self.classes)}
- self.image_files = []
- self.labels = []
- for class_name in self.classes:
- class_dir = os.path.join(root_dir, class_name)
- for file_name in os.listdir(class_dir):
- if file_name.endswith(('.jpg', '.jpeg', '.png')):
- image_path = os.path.join(class_dir, file_name)
- self.image_files.append(image_path)
- self.labels.append(self.class_to_idx[class_name])
-
- def __len__(self):
- return len(self.image_files)
-
- def __getitem__(self, idx):
- image = Image.open(self.image_files[idx]).convert('RGB')
- label = self.labels[idx]
- if self.transform:
- image = self.transform(image)
- return image, label

在上述代码中,CustomImageDataset类继承自Dataset类,实现了__init__、__len__和__getitem__方法。__init__方法用于初始化数据集,包括读取图像文件路径和对应的标签;__len__方法返回数据集的大小;__getitem__方法根据索引获取图像和标签,并对图像进行预处理(如果有定义预处理操作)。
接下来,使用DataLoader进行数据加载和批量处理:
- from torchvision import transforms
- from torch.utils.data import DataLoader
-
- # 定义数据预处理操作
- transform = transforms.Compose([
- transforms.Resize((224, 224)),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
- ])
-
- # 创建数据集实例
- dataset = CustomImageDataset(root_dir='your_dataset_path', transform=transform)
-
- # 创建数据加载器,设置批量大小为32
- dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
-
- # 遍历数据加载器进行训练或推理
- for images, labels in dataloader:
- # 这里进行模型的训练或推理操作
- print(images.shape)
- print(labels.shape)
在这段代码中,首先定义了数据预处理操作,然后创建了CustomImageDataset数据集实例,并将其传入DataLoader中。DataLoader的batch_size参数设置为 32,表示每次从数据集中加载 32 个样本组成一个批次;shuffle=True表示在每次迭代时打乱数据集的顺序,这样可以增加模型训练的随机性和泛化能力。在遍历数据加载器时,可以获取到批量的图像数据和标签数据,用于模型的训练或推理操作。
模型训练与优化:提升模型性能
在深度学习的旅程中,模型训练与优化是决定模型性能优劣的关键环节。它不仅需要我们精心设计训练流程,还要求我们巧妙地调整超参数,以挖掘模型的最大潜力。在蓝耘 GPU 智算云平台上,凭借其强大的算力支持,我们能够更高效地进行这一关键任务。
(一)自定义训练流程
根据自己的需求定义模型训练流程是提升模型性能的重要一步。这其中,损失函数和优化器的选择与设置起着核心作用。
损失函数,作为衡量模型预测值与真实值之间差异的指标,其选择直接影响模型的学习方向。在分类任务中,交叉熵损失函数(Cross - Entropy Loss)是常用的选择。以 PyTorch 为例,使用交叉熵损失函数的代码如下:
- import torch
- import torch.nn as nn
-
- # 假设模型输出为logits,真实标签为labels
- logits = torch.randn(32, 10) # 32个样本,10个类别
- labels = torch.randint(0, 10, (32,)) # 随机生成32个样本的真实标签
-
- criterion = nn.CrossEntropyLoss()
- loss = criterion(logits, labels)
- print('Loss:', loss.item())
在上述代码中,首先导入必要的库torch和nn。然后创建了模型的输出logits和真实标签labels。通过nn.CrossEntropyLoss()创建了交叉熵损失函数的实例criterion,并使用criterion(logits, labels)计算损失值。
对于回归任务,均方误差损失函数(Mean Squared Error Loss,MSE)则更为合适。代码示例如下:
- import torch
- import torch.nn as nn
-
- # 假设模型输出为predictions,真实值为targets
- predictions = torch.randn(32, 1) # 32个样本,每个样本1个预测值
- targets = torch.randn(32, 1) # 32个样本的真实值
-
- criterion = nn.MSELoss()
- loss = criterion(predictions, targets)
- print('Loss:', loss.item())
这里通过nn.MSELoss()创建均方误差损失函数实例criterion,并计算预测值与真实值之间的均方误差损失。
优化器负责调整模型的参数,以最小化损失函数。常见的优化器有随机梯度下降(SGD)、Adam 等。以 Adam 优化器为例,在 PyTorch 中的设置代码如下:
- import torch
- import torch.optim as optim
- from torchvision.models import resnet18
-
- model = resnet18()
- optimizer = optim.Adam(model.parameters(), lr=0.001)
在这段代码中,首先导入torch和optim模块,然后创建了一个resnet18模型实例model。接着,使用optim.Adam创建了 Adam 优化器实例optimizer,并将模型的参数model.parameters()传入,同时设置学习率lr为 0.001。学习率是优化器中的一个重要超参数,它控制着参数更新的步长,对模型的收敛速度和性能有显著影响。
下面给出一个完整的自定义训练流程的代码框架:
- import torch
- import torch.nn as nn
- import torch.optim as optim
- from torch.utils.data import DataLoader
-
- # 假设已经定义好模型、数据集和数据加载器
- model = YourModel()
- dataset = YourDataset()
- dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
-
- criterion = nn.CrossEntropyLoss()
- optimizer = optim.Adam(model.parameters(), lr=0.001)
-
- # 训练模型
- for epoch in range(10): # 假设训练10个epoch
- model.train()
- for inputs, labels in dataloader:
- optimizer.zero_grad()
- outputs = model(inputs)
- loss = criterion(outputs, labels)
- loss.backward()
- optimizer.step()
- print(f'Epoch {epoch + 1}, Loss: {loss.item()}')
在这个框架中,首先定义了模型model、数据集dataset和数据加载器dataloader。然后选择了交叉熵损失函数criterion和 Adam 优化器optimizer。在训练循环中,通过optimizer.zero_grad()清空梯度,model(inputs)进行前向传播,criterion(outputs, labels)计算损失,loss.backward()进行反向传播计算梯度,最后optimizer.step()更新模型参数。
(二)超参数调优
超参数调优是提升模型性能的关键手段,它能够找到一组最优的超参数组合,使模型在特定任务上表现最佳。超参数不同于模型在训练过程中自动学习的参数,如神经网络的权重和偏置,它们是在训练前手动设置的参数,却对模型的性能有着巨大的影响。
以神经网络为例,学习率决定了模型在训练过程中参数更新的步长。如果学习率设置过小,模型的训练速度会非常缓慢,需要更多的训练时间和计算资源才能收敛;而如果学习率设置过大,模型可能会在训练过程中无法收敛,甚至出现振荡或发散的情况。批量大小则决定了每次训练时从数据集中选取的样本数量。较小的批量大小会导致训练过程中的噪声较大,但可以更频繁地更新参数,可能有助于模型跳出局部最优解;较大的批量大小可以使梯度估计更加稳定,但可能需要更多的内存,并且在某些情况下可能会使模型陷入局部最优。
常用的超参数调优方法包括网格搜索和随机搜索。
网格搜索是一种简单直观的超参数调优方法,它通过穷举指定的参数组合,计算每一组参数在验证集上的表现,最终选择表现最好的参数组合。在 Scikit - learn 库中,可以使用GridSearchCV类来实现网格搜索。以下是一个使用GridSearchCV对支持向量机(SVM)进行超参数调优的代码示例
- from sklearn.model_selection import GridSearchCV
- from sklearn.svm import SVC
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
-
- # 加载数据集
- iris = load_iris()
- X = iris.data
- y = iris.target
-
- # 划分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义SVM模型
- svm = SVC()
-
- # 定义超参数网格
- param_grid = {
- 'C': [0.1, 1, 10],
- 'kernel': ['linear', 'rbf', 'poly'],
- 'degree': [2, 3, 4]
- }
-
- # 创建网格搜索对象
- grid_search = GridSearchCV(svm, param_grid, cv=5, scoring='accuracy')
-
- # 进行网格搜索
- grid_search.fit(X_train, y_train)
-
- # 输出最佳参数组合和对应的得分
- print('Best parameters:', grid_search.best_params_)
- print('Best score:', grid_search.best_score_)
在上述代码中,首先加载了鸢尾花数据集,并将其划分为训练集和测试集。然后定义了 SVM 模型svm和超参数网格param_grid,其中包含了需要调优的超参数C、kernel和degree及其取值范围。接着创建了GridSearchCV对象grid_search,并将 SVM 模型、超参数网格、交叉验证折数cv和评分指标scoring传入。最后通过grid_search.fit(X_train, y_train)进行网格搜索,找到最佳的超参数组合,并输出最佳参数组合和对应的得分。
随机搜索则是从指定的参数分布中随机采样参数组合,计算这些组合在验证集上的表现,选择表现最优的组合。在 Scikit - learn 库中,可以使用RandomizedSearchCV类来实现随机搜索。以下是一个使用RandomizedSearchCV对随机森林分类器进行超参数调优的代码示例:
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.model_selection import RandomizedSearchCV
- from sklearn.datasets import make_classification
- from sklearn.model_selection import train_test_split
- from scipy.stats import randint
-
- # 生成分类数据集
- X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
-
- # 划分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义随机森林分类器
- rf = RandomForestClassifier(random_state=42)
-
- # 定义超参数分布
- param_dist = {
- 'n_estimators': randint(50, 200),
- 'max_depth': randint(3, 10),
- 'min_samples_split': randint(2, 10)
- }
-
- # 创建随机搜索对象
- random_search = RandomizedSearchCV(rf, param_distributions=param_dist, n_iter=50, cv=5, scoring='accuracy', random_state=42)
-
- # 进行随机搜索
- random_search.fit(X_train, y_train)
-
- # 输出最佳参数组合和对应的得分
- print('Best parameters:', random_search.best_params_)
- print('Best score:', random_search.best_score_)
在这段代码中,首先生成了一个分类数据集,并将其划分为训练集和测试集。然后定义了随机森林分类器rf和超参数分布param_dist,使用scipy.stats库中的randint来定义超参数的取值范围。接着创建了RandomizedSearchCV对象random_search,并将随机森林分类器、超参数分布、采样次数n_iter、交叉验证折数cv、评分指标scoring和随机种子random_state传入。最后通过random_search.fit(X_train, y_train)进行随机搜索,找到最佳的超参数组合,并输出结果。
在蓝耘 GPU 智算云平台上进行超参数调优时,由于平台提供了强大的算力支持,可以大大缩短调优所需的时间。在使用网格搜索或随机搜索等方法时,可以同时并行运行多个参数组合的训练任务,充分利用平台的多 GPU 资源,加速超参数调优的过程,从而更快地找到最优的超参数组合,提升模型的性能 。
总结与展望:回顾与期待
通过本教程,我们深入探索了蓝耘 GPU 智算云平台的使用方法,从前期的注册登录、实例创建,到环境搭建、模型加载与推理、数据处理、模型训练与优化,再到模型部署与应用以及错误处理和性能优化,全面掌握了在该平台上开展 AI 开发的关键技能。蓝耘 GPU 智算云平台凭借其强大的算力资源、灵活的功能特性和高性价比的优势,为 AI 开发者提供了一个高效、便捷的开发环境。在模型训练过程中,其强大的 GPU 集群能够显著缩短训练时间,让我们更快地验证模型的有效性;在模型部署方面,平台提供的全流程支持使得我们能够轻松将训练好的模型应用到实际场景中。
展望未来,随着 AI 技术的不断发展,对算力的需求将持续增长。蓝耘 GPU 智算云平台有望不断升级和完善,提供更强大的算力资源、更丰富的功能和更优质的服务。在算力方面,可能会引入更先进的 GPU 型号,进一步提升计算速度和效率;在功能上,可能会加强对新兴 AI 技术和应用场景的支持,如量子计算与 AI 的融合、元宇宙中的 AI 应用等。对于开发者而言,蓝耘智算云平台将成为他们在 AI 领域不断创新和突破的有力助手。无论是科研人员进行前沿的 AI 研究,还是企业开发具有创新性的 AI 产品和服务,都可以借助蓝耘平台的优势,加速项目的进展,实现更大的价值。在未来的 AI 发展浪潮中,蓝耘 GPU 智算云平台必将发挥更加重要的作用,助力我们在人工智能的广阔天地中取得更多的成果。

 微信名片
微信名片

评论记录:
回复评论: