
前言
Stable Diffusion 是一种基于扩散技术的深度学习文本转图像模型,利用潜在扩散模型(Latent Diffusion Model,LDM)来生成高质量的图像。它主要用于生成以文字描述为条件的详细图像,但也可应用于其他任务,如 inpainting(图像修复)、outpainting(图像扩展)以及根据文字提示词生成图像到图像(image-to-image)的转换。
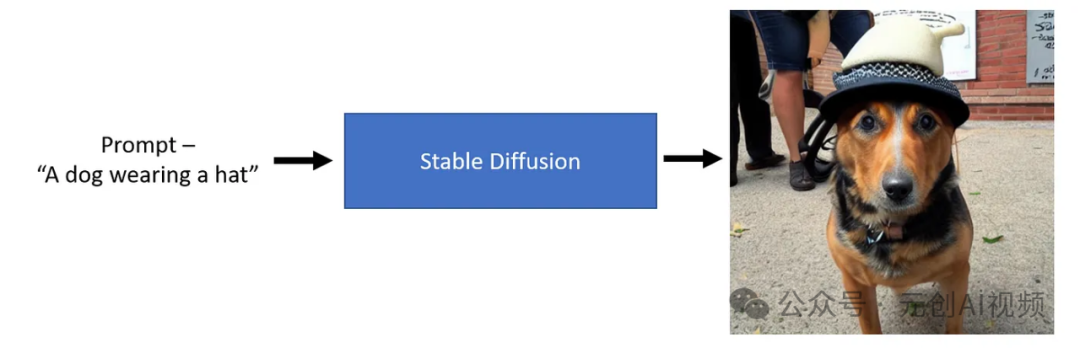
从上图可以看出,只需提供一个文本提示,例如“一只戴着帽子的狗”,Stable Diffusion模型就可以生成一张代表文本的图像,这太神奇了!
扩散模型可以生成高质量的图像,Stable Diffusion模型是一种特殊的扩散模型,称为潜在扩散模型(LDM)。原始扩散模型往往会消耗更多的内存,因此创建了潜在扩散模型,它可以在称为潜在空间的低维空间中进行扩散过程。从高层次上讲,扩散模型是机器学习模型,它被denoise逐步训练成随机高斯噪声,以获得结果,即image。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~

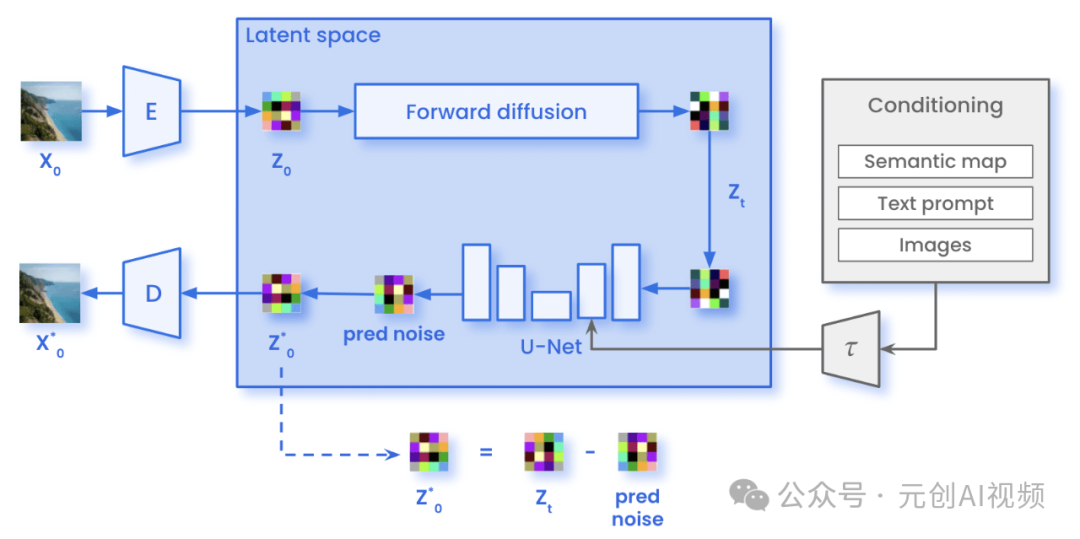
Stable Diffusion 模型架构
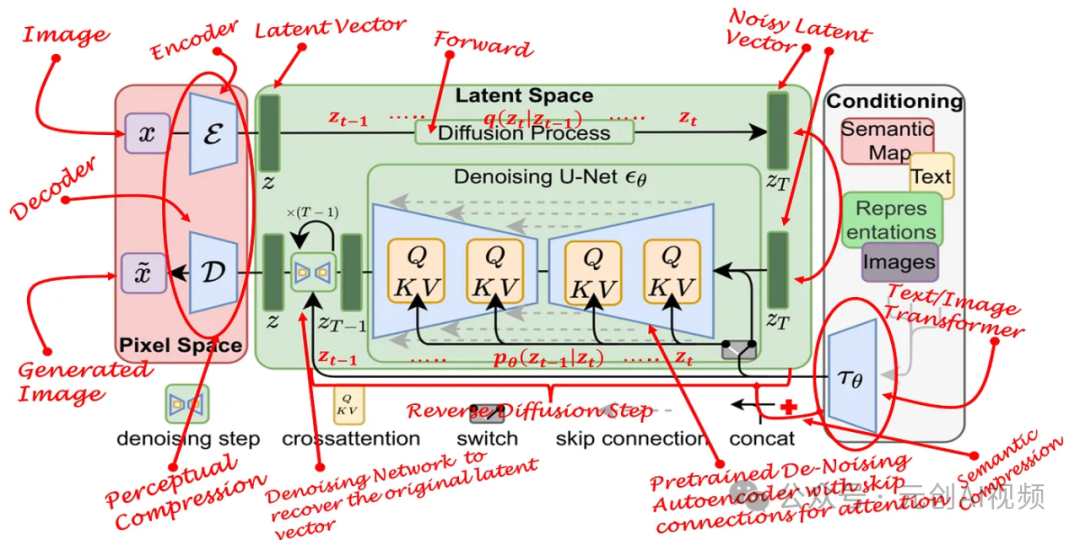
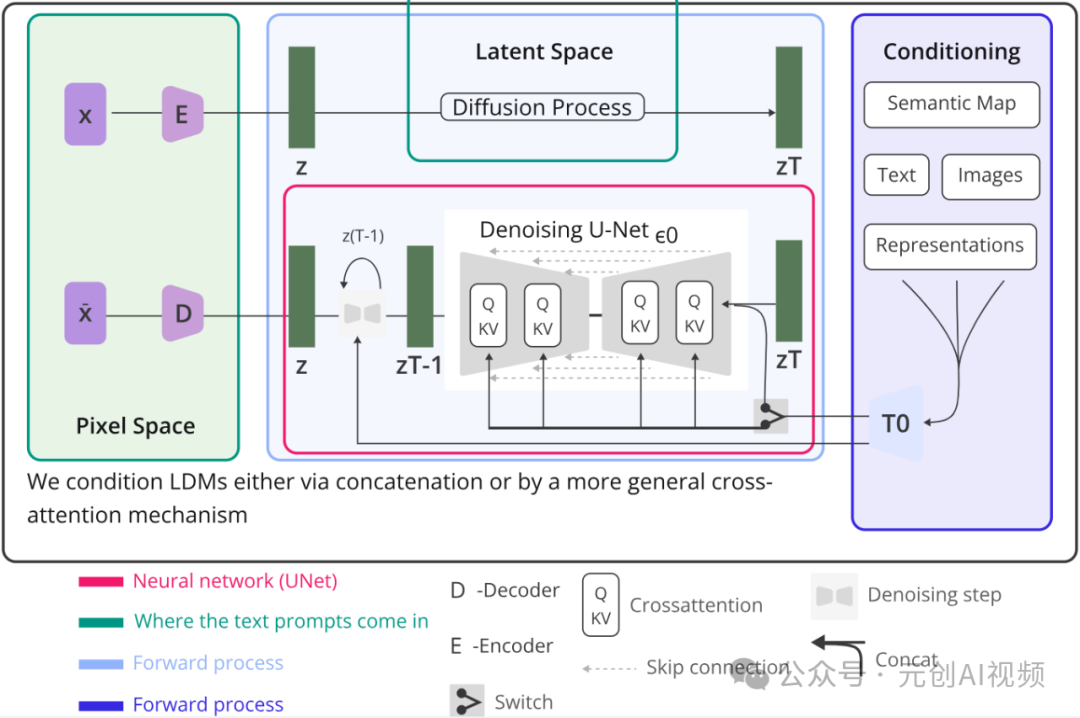
Stable Diffusion 模型架构示意图
Conditioning(条件信息):包含语义图(Semantic Map)、文本(Text)、表示(Representations)和图像(Images)等信息。这些条件信息通过一个网络T0编码,作为生成过程的辅助输入。
Latent Space(潜在空间):扩散过程在潜在空间中进行,潜在空间表示通过噪声预测网络(Denoising U-Netεθ)从初始噪声逐步去噪,生成图像的潜在表示。
Pixel Space(像素空间):最终从潜在空间的表示通过解码器D还原出图像,生成高分辨率的图像。
Stable Diffusion 工作过程
1.编码(Encoding):输入的图像X通过编码器E转换到潜在空间Z。
2.扩散过程(Diffusion Process):扩散过程在潜在空间中进行,从初始的潜在表示Zt逐步去噪,还原出更清晰的潜在表示。通过多个时间步的去噪操作,每一步利用Denoising U-Net预测并去除噪声。中间结果zT-1, zT-2, … , z0表示逐步去噪的潜在表示。
3.解码(Decoding):最终的潜在表示z0通过解码器D转换回像素空间,生成最终的图像。
关键步骤和组件
Denoising Step(去噪步骤):在潜在空间中逐步去除噪声的过程,每一步通过εθ进行。
Cross Attention(交叉注意力):在去噪过程中,利用交叉注意力机制融合来自条件信息的语义信息,增强生成效果。
Switch(切换):在去噪步骤中,可能涉及不同特征图之间的切换操作,以丰富特征表示。
Skip Connection(跳跃连接):在去噪网络中,跳跃连接帮助保留高分辨率的信息,提高去噪效果。
Concat(拼接):在特定步骤,将不同来源的特征进行拼接,融合多种信息以提高生成质量。
潜在扩散可以通过在较低维度的潜在空间上应用扩散过程(而不是使用实际像素空间)来减少内存和计算复杂性,这是标准扩散和潜在扩散模型之间的主要区别。在潜在扩散中,模型经过训练以生成图像的潜在(压缩)表示。
扩散过程图示
Stable Diffusion模型采用文本输入和种子。然后,文本输入通过CLIP 模型生成大小为77x768的文本嵌入,种子用于生成大小为4x64x64的高斯噪声,该噪声成为第一个潜在图像表示。
注意:你会注意到图像中提到了一个额外的维度(1x),例如用于文本嵌入的1x77x768,这是因为它代表批量大小为1。
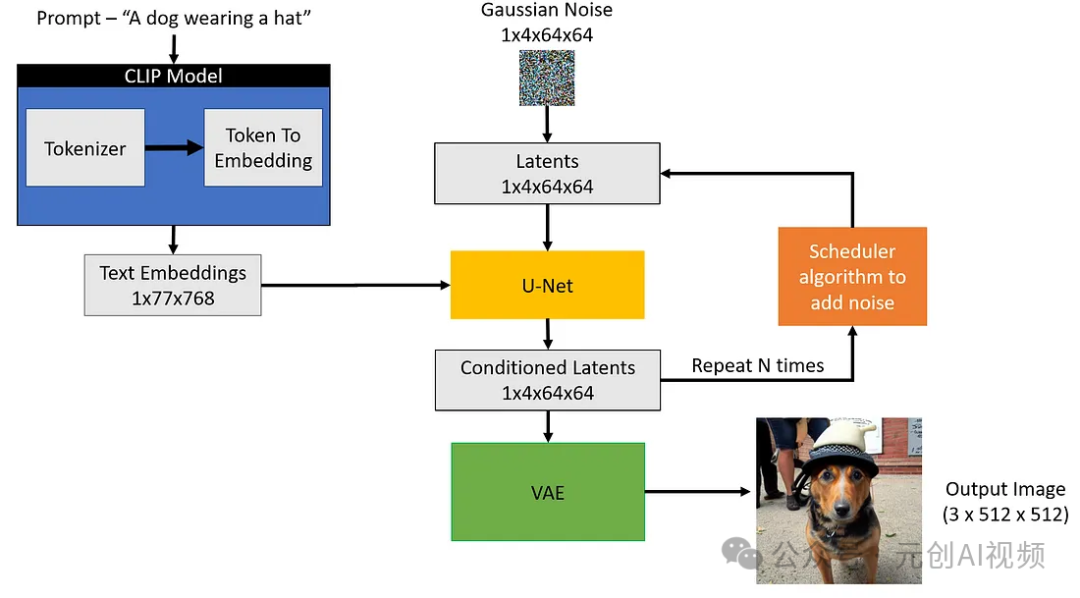
扩散过程图示
接下来,U-Net在对文本嵌入进行条件化的同时,迭代地对随机潜在图像表示进行去噪。U-Net的输出是预测的噪声残差,然后通过调度器算法将其用于计算条件化的潜在图像。此去噪和文本条件化过程重复N次(我们将使用50次)以检索更好的潜在图像表示。此过程完成后,VAE解码器将对潜在图像表示(4x64x64)进行解码,检索最终的图像(3x512x512)。此迭代去噪是获得良好输出图像的重要步骤,典型步骤在30-80范围内。
让我们看一下从噪声到最终图像的生成过程。
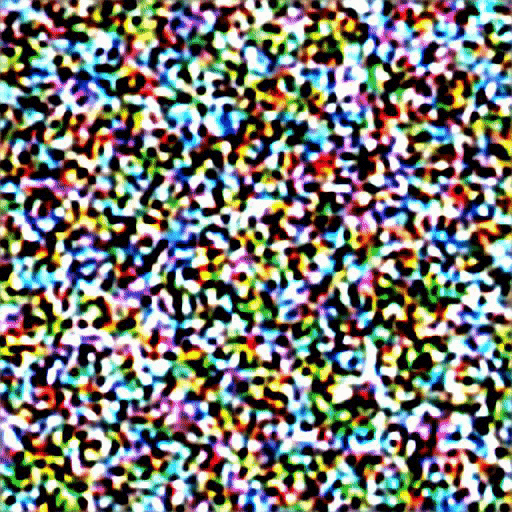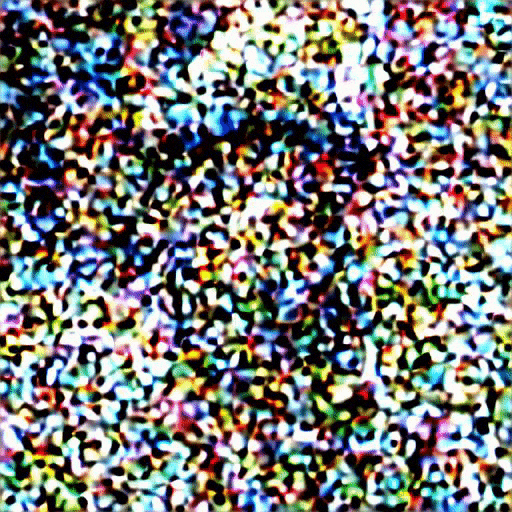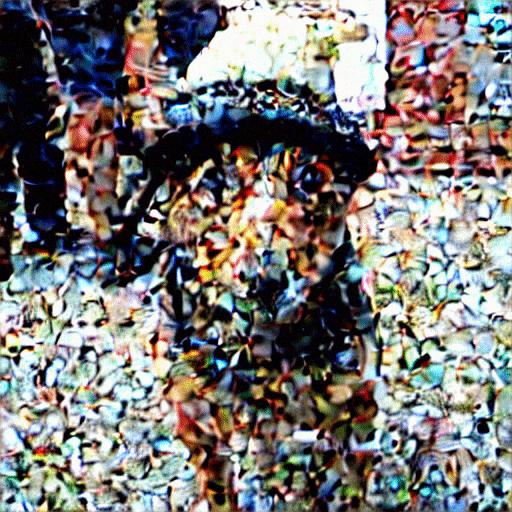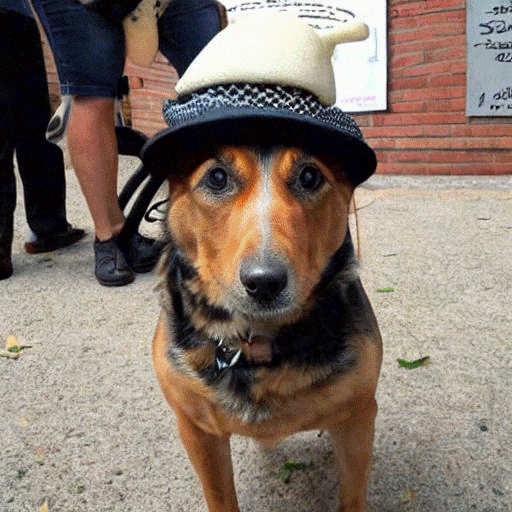
稳定扩散的核心组件
Stable Diffusion有三个主要组成部分:文本编码器,在本例中为CLIP 文本编码器;自动编码器,在本例中为变分自动编码器(VAE);U-Net。让我们深入研究每个组件,并了解它们在扩散过程中的用途。
文本编码器CLIP,即Contrastive Language-Image Pre-training,对比语言-图像预训练。CLIP模型有两个主要组件,一个文本编码器(嵌入文本)和一个图像编码器(嵌入图像)。对于文本编码器,使用了经典的Transformer模型;对于图像编码器,则通常会使用Vision Transformer (ViT)模型。
任何机器学习模型都不理解文本数据,因此对于这些模型,我们都需要将文本转换为包含文本含义的数字,称为embeddings。将文本转换为数字的过程可以分为两个部分。
1.标记器-将每个单词分解为子单词,然后使用查找表将它们转换为数字。
2.标记到嵌入编码器-将这些数字子单词转换为包含该文本表示的表示。
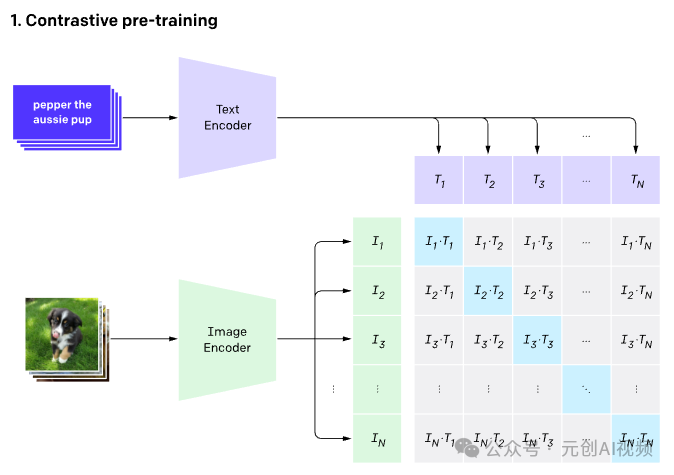
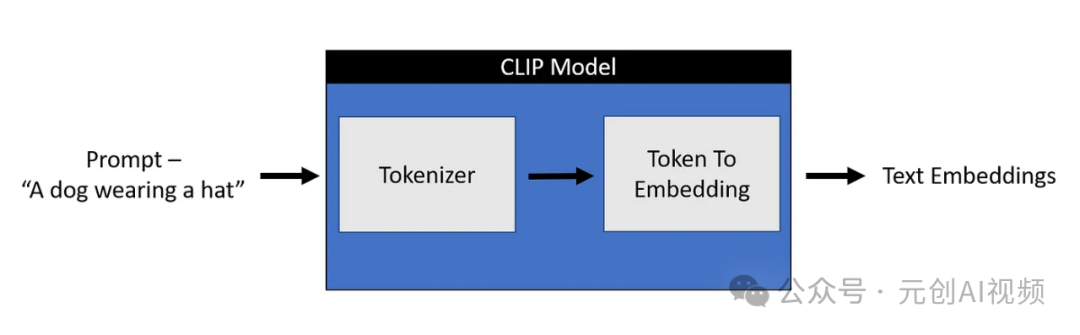
Stable Diffusion仅使用CLIP训练的编码器将文本转换为嵌入。这成为 U-net的输入之一。在高层次上,CLIP使用图像编码器和文本编码器来创建在潜在空间中相似的嵌入,这种相似性更准确地定义为对比目标。
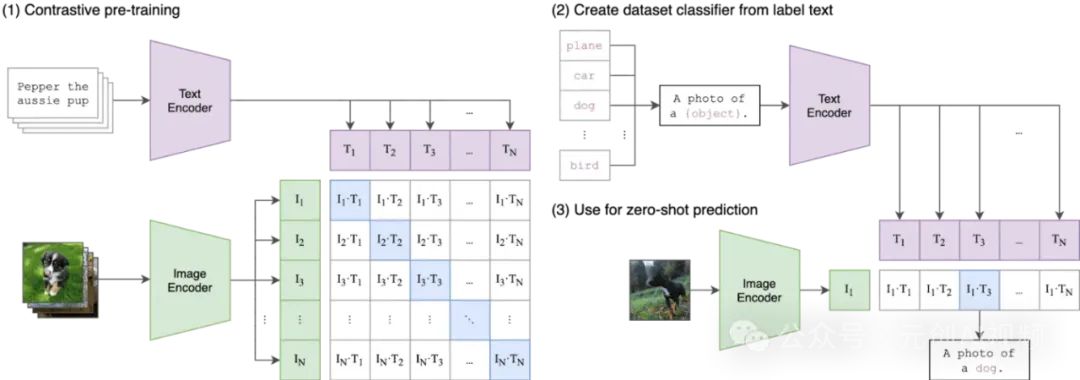
CLIP预先训练了一个图像编码器和一个文本编码器,以预测哪些图像与数据集中的哪些文本配对。然后,我们利用这种行为将CLIP转变为零样本分类器。我们将数据集的所有类别转换为标题,例如“一张狗的照片”,并预测CLIP估计的与给定图像最佳配对的标题类别。
**变分自动编码器VAE,**它是机器学习和人工智能中使用的一种生成模型。它是一种概率模型,旨在以无监督的方式学习输入数据的低维表示。VAE 特别适用于生成与训练数据相似的新数据样本等任务。
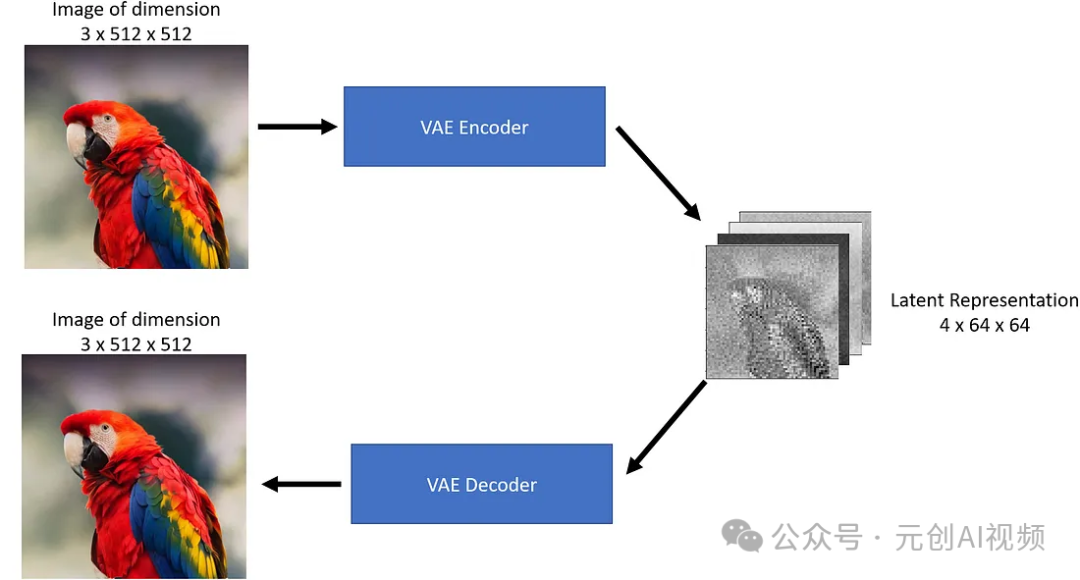
自动编码器包含两个部分:
1.Encoder将图像作为输入并将其转换为低维潜在表示。
2.Decoder将潜在表示转换回图像。
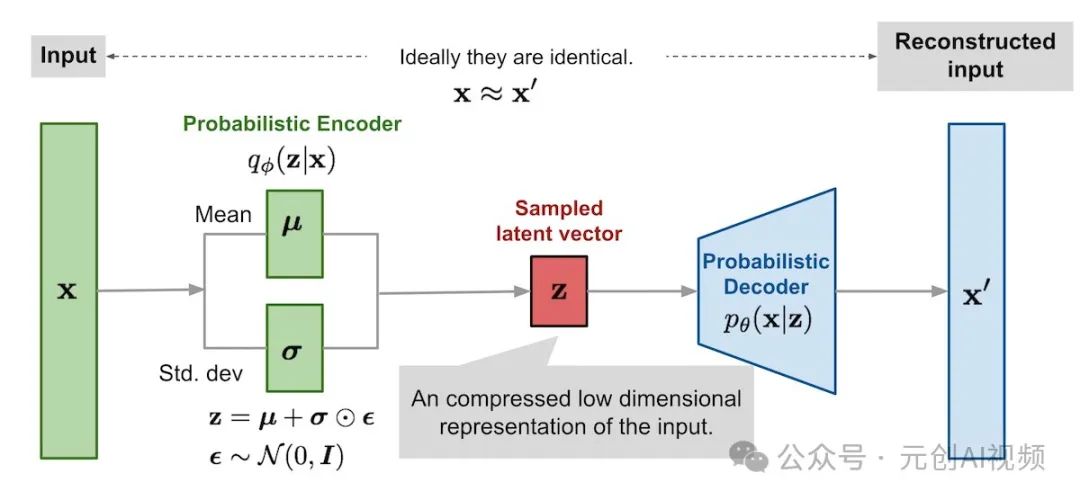
变分自动编码器
正如我们上面看到的,编码器就像一个压缩器,将图像压缩成较低的尺寸,解码器则从压缩版本重新创建原始图像。
VAE将3x512x512尺寸的图像压缩为4x64x64尺寸的图像,压缩比为48倍!让我们将这四个潜在表征通道可视化。

从理论上讲,这种潜在表示应该能够捕获大量有关原始图像的信息。让我们对这种表示使用解码器,看看我们能得到什么。

从上图我们可以看出,VAE解码器能够从48x压缩的潜在表示中恢复原始图像。这令人印象深刻!如果你仔细观察解码后的图像,你会发现它与原始图像并不相同,请注意眼睛周围的差异。这就是为什么VAE编码器/解码器不是无损压缩的原因。
稳定扩散可以在没有VAE组件的情况下完成,但我们使用VAE的原因是为了减少生成高分辨率图像的计算时间。潜在扩散模型可以在VAE编码器产生的潜在空间中执行扩散,一旦我们通过扩散过程获得了所需的潜在输出,我们就可以使用VAE解码器将它们转换回高分辨率图像。
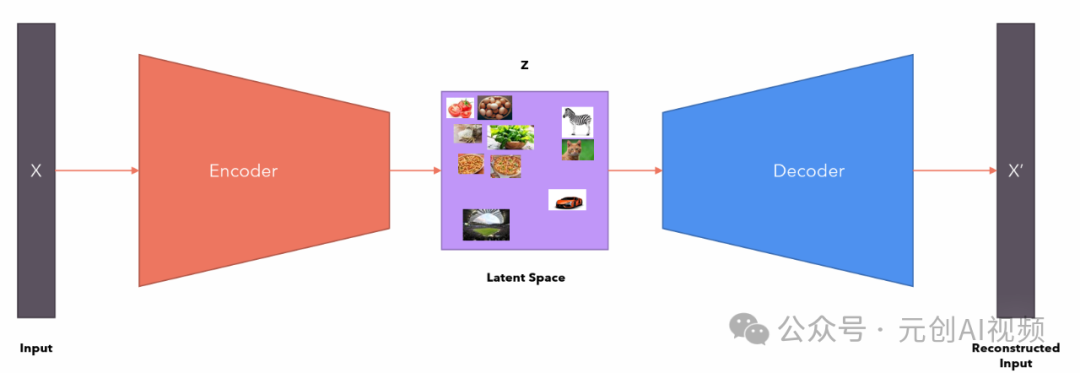
就像你使用Python生成1到100之间的随机数一样,你是从1到100之间的均匀(伪)随机分布中进行采样。同样,我们可以从潜在空间中采样以生成随机向量,将其提供给解码器并生成新数据。

要理解潜在空间(latent space),可以借助柏拉图洞穴寓言进行说明。

在这个寓言中,我们看到囚犯们看到了雕像的影子,他们相信他们看到的是实际的物体(可观察的数据)。但与此同时,实际的物体就在他们身后(潜在的、隐藏的数据)。
U-Net模型,它是一种很经典的卷积神经网络结构,它由对称的编码器和解码器组成,具有很好的特征提取和细节恢复能力。在Stable Diffusion中,U-Net是一个核心的模块,主要负责图像生成过程中的去噪和提取,以生成新的图像。
U-net架构图
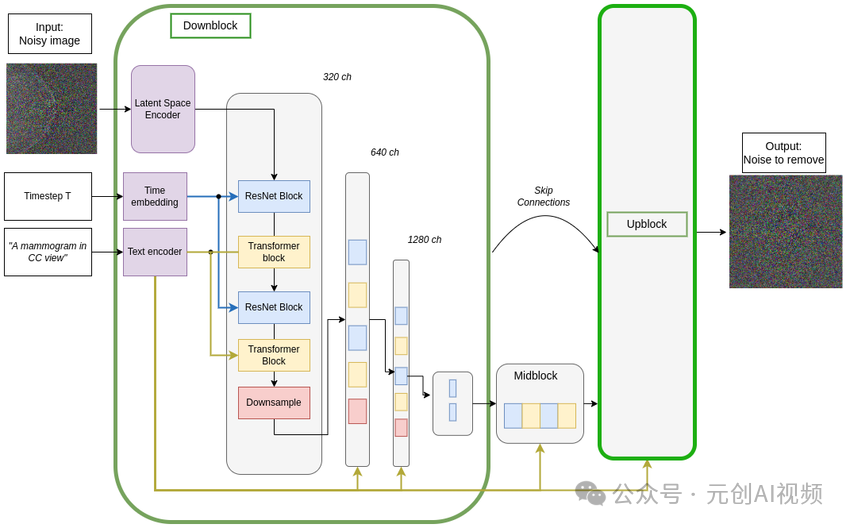
反向扩散过程的去噪UNet架构,上块结构是下块的镜像
Middle block:在U-Net架构中,middle block(中间块)是模型的一个关键组成部分,通常位于编码器和解码器之间。它的主要功能是在最底层的分辨率下处理特征,结合了多个操作以增强模型的表现。
Skip-connected decoder:一种在深度学习模型中使用的架构,在U-Net的图像生成和分割任务中,它的主要功能是通过跳接连接(skip connections)将编码器中的高分辨率特征图直接传递到解码器中,以便在重建图像时保留更细致的空间信息。
U-Net模型接受两个输入:
1.Noisy latent或Noise噪声潜在向量是VAE编码器产生的潜在向量(如果提供了初始图像)并添加了噪声,或者如果我们想仅基于文本描述创建随机的新图像,它可以接受纯噪声输入。
2.Text embeddings,由输入文本提示生成的基于CLIP的嵌入。
U-Net模型的输出是输入噪声潜在函数所包含的预测噪声残差,换句话说,它预测从噪声潜在函数中减去的噪声,以返回原始的去噪潜在函数。
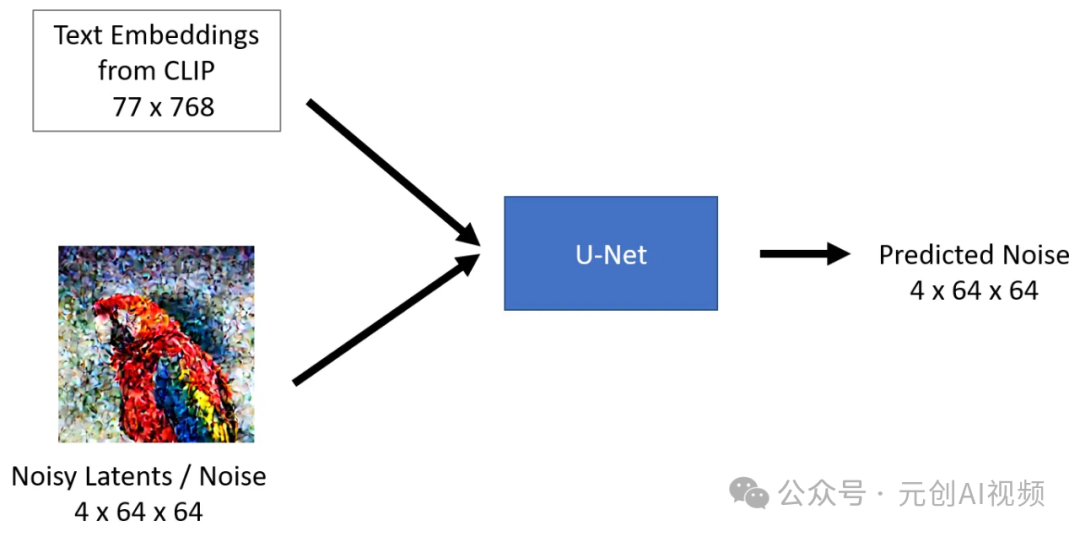
U-Net表示
在这个过程中,我们不仅导入了unet,还导入了一个scheduler(调度器)。Schedular的作用是确定在扩散过程中的给定步骤中向Latent添加多少噪声。让我们可视化schedular函数。
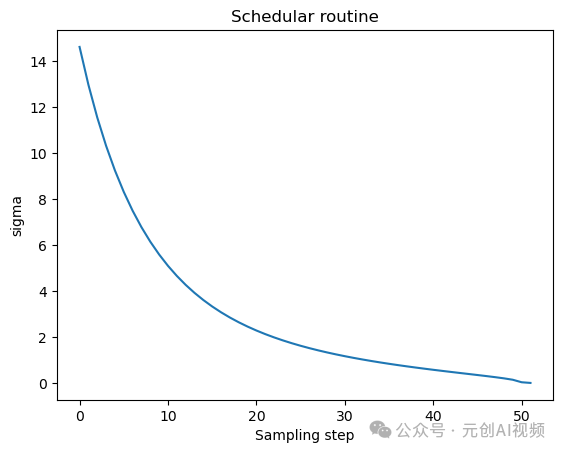
扩散过程遵循此采样计划,我们从高噪声开始,逐渐对图像进行去噪。让我们形象地看一下这个过程。
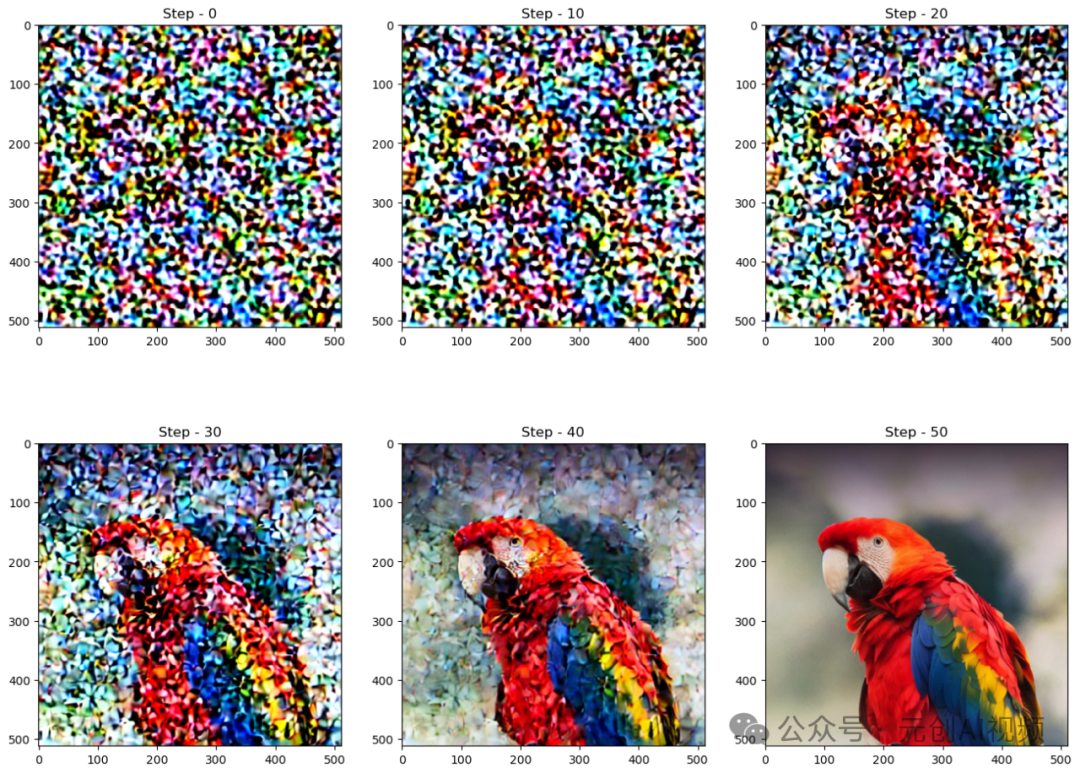
让我们看看U-Net如何去除图像中的噪音,我们给图像添加一些噪声。从右边图可以看出,U-Net的输出比传递的原始噪声输入更清晰。

Stable Diffusion使用U-Net通过几个步骤逐渐减去潜在空间中的噪声以达到所需的输出。随着每一步,添加到潜在中的噪声量都会减少,直到我们达到最终的去噪输出。U-Net有一个编码器和一个解码器,由ResNet块组成。Stable Diffusion的U-Net还具有交叉注意层,使它们能够根据提供的文本描述调节输出。交叉注意层通常添加到U-Net的编码器和解码器部分,位于ResNet块之间。
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。
2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。
3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。
4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!

评论记录:
回复评论: