
什么是梯度
-
要明白什么是梯度下降法,我们需要先知道梯度是什么。
-
梯度的定义
梯度是一个向量,表示多元函数在某一点处变化最快的方向。对于多元函数 f(x1,x2,…,xn),其梯度记作 ∇f 或 grad f,定义为所有偏导数组成的向量:
- 其中,是函数对的偏导数
-
梯度的几何意义
-
方向:梯度指向函数在该点处局部上升最快的方向。
-
大小:梯度的大小表示函数在该方向的变化率。
-
-
举例说明
多元函数
- 该函数的梯度为∇=()
- 在点(1,1,1)处,梯度为(2,3,2),指向函数上升最快的方向(右上方向)。
- 梯度下降法会沿(-2,-3,-2)方向更新参数,逐步逼近最小值点。
梯度下降法
-
定义:
**梯度下降(Gradient Descent)**是机器学习和优化领域中用于最小化目标函数(通常是损失函数)的核心迭代算法。其核心思想是通过计算函数的梯度来找到函数值下降最快的方向,并沿该方向调整参数以逐步逼近最小值。目的就是为了寻找函数的最小值点。
-
为什么需要使用梯度下降
训练神经网络本质上是一个优化问题:我们需要找到一组参数(权重和偏置),使得神经网络的输出与真实值之间的误差(即损失函数)最小化。由于神经网络可能有数百万甚至数十亿个参数,损失函数是这些参数的复杂非线性函数。解析解(如直接求导数为零的方程)在数学上不可行。而梯度下降是通过通过迭代局部优化,逐步逼近最优解,避免直接求解不可行的全局优化问题,从而使神经网络的误差最小。
-
数学实现
- 是本次梯度下降后的位置。
- 是本此梯度下降前的位置。
- 是学习率(步长),控制更新幅度。
- ∇是当前参数处的梯度。
-
终止条件
- 梯度接近0(达到局部最小值)。
- 迭代次数到达预设上限。
- 函数值变化小于阈值。
-
具体步骤
**1、初始化参数:**随机初始化模型的参数(例如权重和偏置)。
2、计算梯度损失:使用当前参数计算损失函数关于这些参数的梯度。
3、更新参数:将每个参数沿着梯度的方向反方向移动一步,步长由学习率控制。
4、重复迭代:重复计算梯度和更新参数,直到满足终止条件。
梯度下降法的实例演示
-
举例说明
-
一维函数梯度下降
如我们举例一个一维函数该函数的梯度也就是它的导数即。
-
首先,我们需要确定起始点为=1,学习率选择为=0.2
-
那么整个迭代过程如下:
-
可见在数次迭代后,已经接近函数的最小值了。
-
代码实现以上过程:
python代码解读复制代码import numpy as np import matplotlib.pyplot as plt # 定义函数和它的导数 def f(x): return x ** 2 def df(x): return 2 * x # 梯度下降参数 x = 1.0 # 初始点 lr = 0.2 # 学习率 max_iter = 20 # 最大迭代次数 # 存储每次迭代的x和f(x)值用于绘图 x_history = [] f_history = [] # 梯度下降过程 for i in range(max_iter): x_history.append(x) f_history.append(f(x)) # 计算梯度并更新x grad = df(x) x_ = x x = x - lr * grad print(f"迭代 {i + 1}: x{i + 1} = x{i} - {lr:.1f} * f'(x{i}) = {x_:.1g} - {lr:.1g} * 2 * {x_:.1g} = {x:.1g}") # 绘制函数曲线和梯度下降过程 x_vals = np.linspace(-1.5, 1.5, 100) plt.plot(x_vals, f(x_vals), label='f(x) = x²') plt.scatter(x_history, f_history, c='r', label='Gradient Descent Steps') plt.plot(x_history, f_history, 'r--') # 添加箭头显示下降方向 for i in range(len(x_history) - 1): plt.annotate('', xy=(x_history[i + 1], f_history[i + 1]), xytext=(x_history[i], f_history[i]), arrowprops=dict(arrowstyle='->', color='green')) plt.xlabel('x') plt.ylabel('f(x)') plt.title('Gradient Descent for f(x) = x²') plt.legend() plt.grid(True) plt.show() -
图示
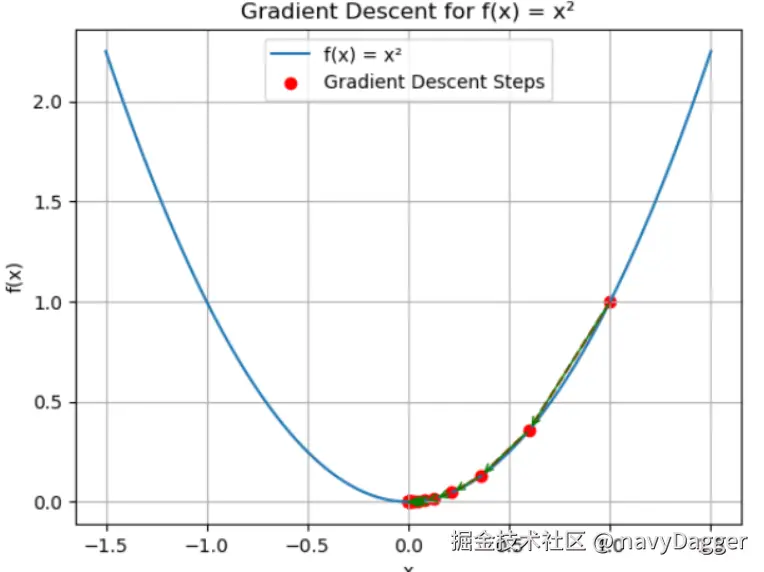
-
-
多维函数梯度下降
如我们举例一个二维函数,该函数的梯度为∇
-
首先,我们确定起始点为,学习率为=0.1
-
那么整个迭代过程如下:
-
经过多次迭代,数据已经十分接近最小值(0,0)了。
-
图示
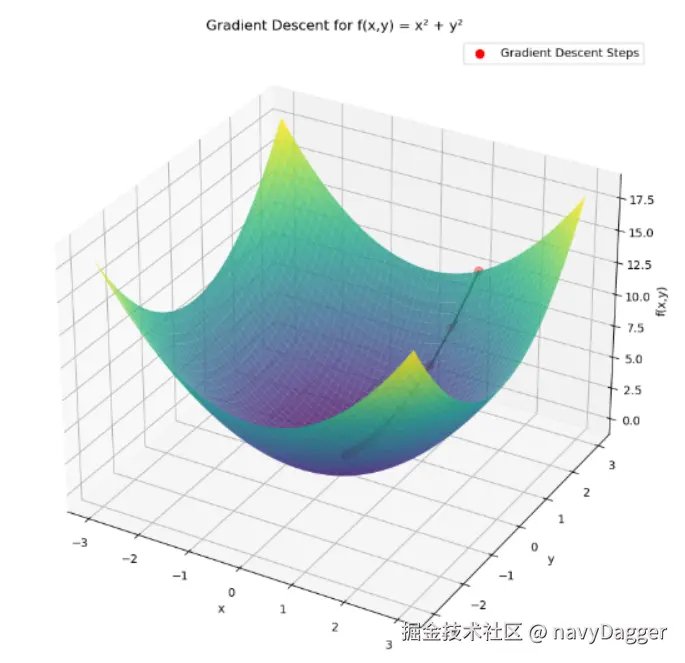
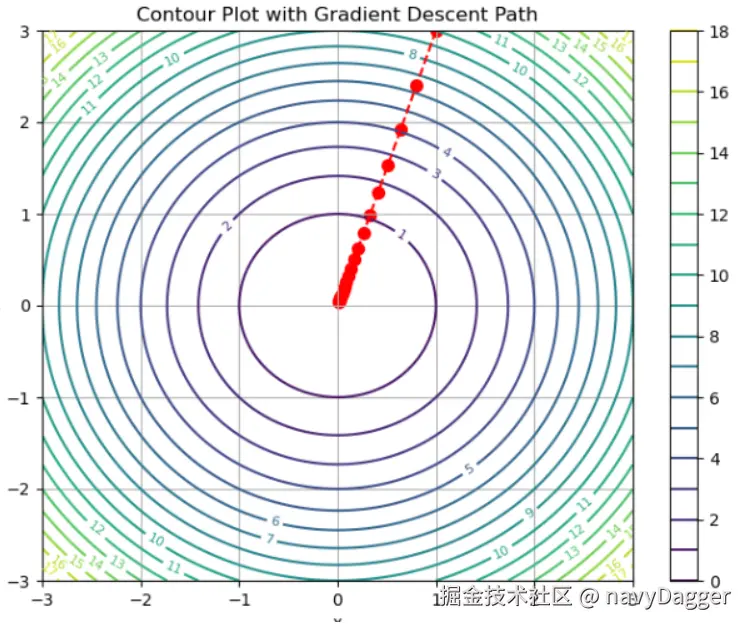
-
-
评论记录:
回复评论: