
前言
伴随着人工智能大模型技术的蓬勃发展,基于大模型的应用也处于积极探索阶段。目前大模型的应用主要集中在如下两个领域:
- 智能体: 大模型落地的关键,提供“即插即用”的通用AI功能,通过
微调,FunctionCalling或MCP技术扩展大模型能力,使其不局限于简单对话。 - 知识库: 大模型减少“幻觉”的关键,将企业数据存储在知识库中,为大模型提供关键的上下文及业务逻辑支持,确保大模型回答准确。
笔者目前分享过包括FunctionCalling、 MCP等技术在内多篇智能体文章收获一些好评。有兄弟私信说:“智能体开发文章很详细,建议同时分享一些关于知识库的相关知识,目前尝试了好多RAG知识库软件AnythingLLM, Dify,但感觉效果一般,也不知道如何提升RAG系统的能力。” 接下来的几篇文章笔者将分享工作生活中学习并使用知识库的相关经验,从知识库的核心原理到知识库的使用技巧,帮大家从0到1上手RAG知识库技术,大家感兴趣点个关注吧。
本篇文章我将和大家聊聊RAG知识库系统的核心原理,用幽默详细的语言向大家分享RAG是如何让大语言模型变得更专业。
一、检索增强生成(RAG)是什么?
RAG(Retrieval-Augmented Generation, 检索增强生成) 是一种将传统信息检索系统与大语言模型相结合的技术架构。它先从大量的外部知识中将有用的信息提取出来,再将这些信息输入大语言模型整理成清晰自然的回答。RAG的架构如下图所示,看起来非常复杂,但相信经过本篇分享逐步拆解分析后,大家能够深刻认识RAG数据准备、数据检索和LLM生成的三个核心环节并掌握这些核心环节是如何串联的。
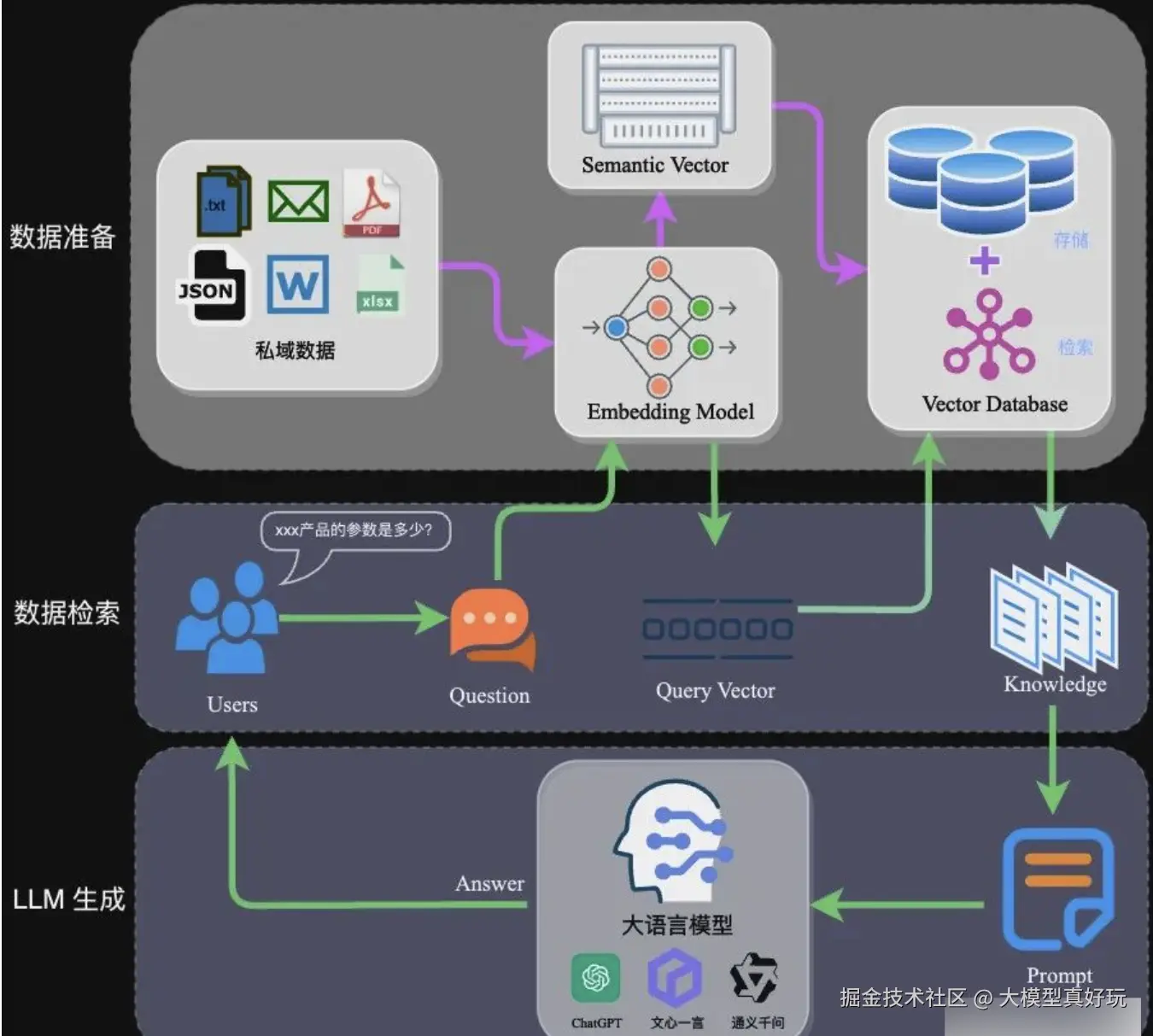
二、RAG数据准备环节
RAG系统搭建的第一步是上传私域数据的文档。这些文档包括.txt, .docx, .json, .pdf, .md等各种各样的格式。所谓的“知识”就是这些文档中的文本信息。我们上传的文档并不是以文件格式直接存储在数据库中(这样和文件夹还有啥区别?)。知识上传后要经过特殊处理才能存放在特殊数据库中,具体步骤如下:
2.1 文本分块
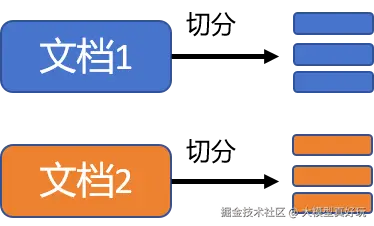
可以把上传的各种文档看成一本超级厚的书,不同的文档就像书中的章节。想象一下你在读书的时候会直接读完一本书或者读完一整个章节嘛?显然不会,我们的阅读习惯基本都是一句一句或者一段一段来阅读。
RAG系统对于知识文本的处理也是这样。上传的文档首先会被拆分成很多小块的数据,拆分的依据可以是按段落切分,按固定文字数切分等,不同的切分策略对于RAG系统的效果有很大影响。
将知识分块主要有如下优点:
- 避免文档太大不好处理:有些文档可能一个就有几百页,直接让电脑分析消耗太大。
- 模型处理长度有限,我们知道模型是有输入输出上下文的,太长的文本模型一次性也处理不了。
- 查找内容更精确,如果一个文档存储成数据库中一项,表明这个文档只有一个标签,很难做到精准查找。
2.2 文本块转换嵌入向量

切分后的文本块不是直接通过文字形式保存在数据库中,而是要经过 生成嵌入模型 (Embedding Model) 转化为向量形式进行存储。
文本向量化有如下两个明显优势:
- 高效的相似性计算:文本向量化之后可直接通过余弦相似度等数学运算高效查询与用户问题相关的片段。如果直接存储文本还涉及到文本字词遍历匹配等操作,效率极低。
- 语义的强相关性:生成嵌入模型是通过大量语言文本训练所得,经它转换后的向量包含了语义信息,可以使得匹配更精确。举个例子:“你对我真好”,“你是大好人”, “你对我真不好”三句话,如果从文本匹配角度来看“你对我真好”和“你对我真不好”有五个字相同,而和“你是大好人”只有两个字相同,但很明显“你对我真好”和“你是大好人”语义更相似而和“你对我真不好”语义完全相反,反映为“你对我真好”和“你是大好人”的嵌入向量余弦相似度要大于“你对我真好”和“你对我真不好”的相似度。
2.3 向量数据库存储

上一阶段所有的文本块都经过生成嵌入模型转化为向量,这些向量要存储到“向量数据库”中。向量数据库可以随时接收新资料,保持知识的更新。这样用户在提问时会检索到最新最相关的文本块。
良好的向量数据库不仅仅保存了文本块向量,还保留了文本块对应的原始文本以及文本块在原始文件中的位置等信息,方便用户查看。
三、RAG数据检索环节
3.1 用户输入
数据准备工作做完就到了用户提问环节,用户输入要查询的问题,我们图中的示例是“xxx产品的参数是多少?”。
3.2 查询向量化

为了快速的在向量数据库中找到与问题相关的文本块,用户输入的问题也需要经过生成嵌入模型(这里必须使用与文本块转换相同的生成嵌入模型)转化为嵌入向量,从而可以与向量库中的向量相互匹配。
3.3 检索相似块
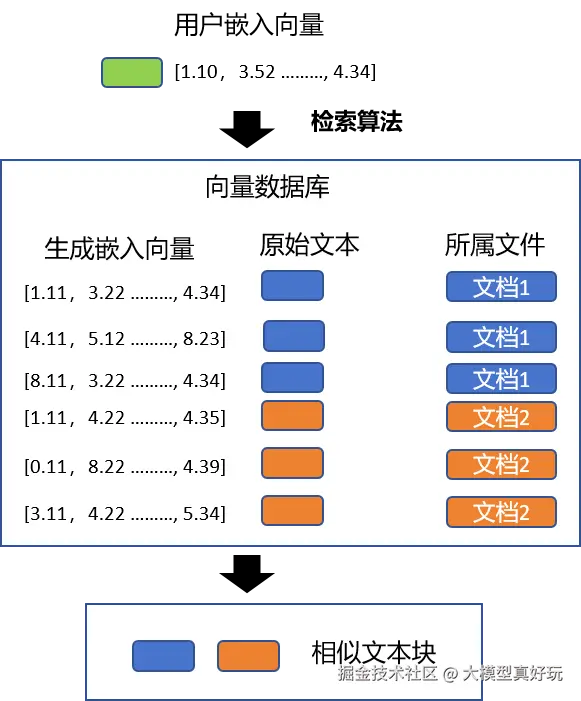
用户问题经过Embedding Model转换后,RAG系统会根据问题的嵌入向量在向量数据中寻找“最可能”的答案匹配。常见的检索算法是“近似最邻近搜索”,该算法会挑出K个最相似的块(K是提前设置的数量),这些文本块中很可能隐藏着问题解答。检索相似块的算法非常快,充分利用了嵌入向量的特性。
3.4 结果重排序ReRank (可选操作)
大家如果平常使用RagFlow等知识库可能遇到过选择ReRank模型的选项(当然也可以不选),那这里的ReRank模型有什么用呢?
ReRank模型又叫结果重排序模型。通俗来说系统为了让答案更靠谱,会对找出来的文本块再排个序,相当于从初筛的答案中找出更加贴切的答案来,这个过程通常会使用更厉害的模型比如交叉编码器(这就是ReRank模型设置的意义)进行打分排序,把评分较高的放在前面。当然并不是所有的RAG系统都这么做,很多公开的知识库系统比如Anythinllm等都是直接利用上一步相似度检索后的结果。
四、LLM生成环节

RAG系统只有在最后一个环节才有大模型的参与。通过上述的操作筛选出文本块后,RAG系统会根据一个Prompt(可自行设置)将这些文本块内容嵌入Prompt模板中,然后再将这个Prompt发送给大模型得到答案。
RAG系统的整个过程可以类比为厨师炒菜,原料就是用来检索的文本块,也就是知识, 火候是大语言模型的语言能力,厨师是大语言模型,端上桌的自然就是美味的答案。
五、总结
看完本篇分享的每个步骤大家再返回文章开头看RAG全貌是不是清晰很多。RAG系统通过数据准备、数据检索和LLM生成三个核心环节把外部知识和大语言模型能力完美结合,使得用户能够收获更专业更准确的知识(从文档中获取的内容尽量避免大模型幻觉)。
RAG系统因其知识随时更新,回答检索靠谱被广泛应用于智能客服、学习助手等领域。作为RAG系统的使用者甚至开发者,我们只有了解RAG系统的核心原理,才能找准RAG系统提升优化的思路,让RAG系统变得更加高效可靠。
以上就是我今天的分享,下一篇我将根据这篇分享中介绍的RAG系统原理以及工作实践中遇到的具体问题总结出一份详细的RAG系统性能提升文档,感兴趣大家可点个关注(RAG性能提升文档本周发表), 大家也可关注我的同名微信公众号:大模型真好玩,免费分享工作生活中大模型开发教程和资料,有什么需要都可通过公众号私信我~
评论记录:
回复评论: