
在深度学习中,注意力机制(Attention Mechanism)可以帮助模型聚焦在重要的信息上,而忽略不相关的内容。注意力评分函数(Scoring Function) 是这一机制的核心,它决定了查询(Query)和键(Key)之间的相关性,从而影响最终的注意力分布。
本文将深入探讨注意力评分函数,介绍其数学原理,并提供 PyTorch 代码示例,帮助读者理解其计算过程。
1. 什么是注意力评分函数?
可以把注意力评分函数想象成一个“匹配度打分器”,它的任务是衡量某个查询和一组键的匹配程度,并生成一个得分。例如,在阅读一篇文章时,我们会更关注与当前问题相关的内容,而不会平均地分配注意力。同样,深度学习模型会使用注意力评分函数来计算查询与不同键的相关性。
2. 计算注意力权重
数学上,注意力汇聚的输出是值(Value)的加权和,其中权重由注意力评分函数生成并经过 Softmax 归一化。设查询为 ,键-值对 ,注意力机制的计算方式如下:
其中 是注意力评分函数,它决定了查询 与键 之间的匹配程度。

3. 掩蔽 Softmax 操作(Masked Softmax)
概念:
掩蔽 Softmax 操作是对标准的 Softmax 进行扩展,用于确保在某些情况下,输入的无效部分(如填充的词元或无意义的部分)不会影响注意力的计算。常见应用是在处理自然语言时,输入句子可能包含填充字符,而这些填充字符应该被忽略。
公式:
普通的 Softmax 是通过以下公式计算权重的:
对于掩蔽 Softmax,我们将无效部分的得分设置为负无穷,使其在 Softmax 运算后权重为 0:
然后,通过 Softmax 将所有得分归一化,确保无效部分的权重为 0。
重要补充说明
- 在注意力机制中,每个 要对所有的 计算注意力分数,然后 Softmax 得到一个权重分布。因此我们需要掩码的是 ,目的是告诉 :某些 是无效的,不要关注它们。
- 掩 是没有意义的:如果一个 是无效的,它就不会参与注意力权重计算。在训练过程中,这种无效的 会提前处理掉,而不是通过 softmax 掩掉。
具体示例:
场景:假设我们在做自然语言处理任务时,输入的文本序列可能需要填充(Padding)到相同的长度,这些填充的部分没有实际意义,我们希望它们在注意力计算中不被考虑。比如,我们有两个文本序列:
- 序列 1:
["我", "喜欢", "学习"] - 序列 2:
["今天", "是", "晴天", "天气", "很好"]
为了保证它们可以在批处理时统一长度,我们为它们做了填充:
- 序列 1 填充后:
["我", "喜欢", "学习", "", " ", " "] - 序列 2 填充后:
["今天", "是", "晴天", "天气", "很好", ""]
现在,我们希望在计算注意力时忽略
代码实现:
python 代码解读复制代码import torch
from torch import nn
from torch.nn import functional as F
# d2l.py
def masked_softmax(X, valid_lens):
"""
执行掩蔽 Softmax 操作。
该函数会根据有效长度 valid_lens 对输入张量 X 进行掩蔽处理。
掩蔽部分将被置为一个非常小的负数(例如 -1e6),以确保它们在 Softmax 操作中得到零的权重。
参数:
X (Tensor): 需要执行 Softmax 的输入张量。
通常是一个 3D 张量,形状为 (batch_size, num_queries, num_kv_pairs)。
valid_lens (Tensor): Tensor 或 None
一个 1D 或 2D 张量,指定每个样本或每个查询对应的有效长度(不应被掩码的部分),
用于屏蔽填充(padding)位置,使其在 softmax 中的权重为 0。
返回:
Tensor: 执行掩蔽 Softmax 后的结果。与输入 X 形状相同,但掩蔽部分的权重会变成零。
"""
if valid_lens is None:
return F.softmax(X, dim=-1)
# 获取 X 的形状 (batch_size, num_queries, num_kv_pairs)
shape = X.shape
if valid_lens.dim() == 1:
# 如果 valid_lens 是一维的,将它扩展为二维,重复有效长度,适配每个序列
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
# 确保 valid_lens 是一个一维张量
valid_lens = valid_lens.reshape(-1)
# 将 X reshape 为 2D:(batch_size * num_queries, num_kv_pairs)
X = X.reshape(-1, shape[-1])
# 创建掩蔽操作,超出有效长度的位置被替换为一个非常小的负数(-1e6)
X = torch.where(
valid_lens.unsqueeze(-1) > torch.arange(X.shape[-1], device=X.device),
X, # 对应有效位置保留原值
torch.tensor(-1e6) # 对于无效位置,使用极小值 -1e6
)
# 执行 Softmax 操作,返回 Softmax 的结果,dim=-1 表示按最后一个维度(num_kv_pairs)计算 Softmax
return F.softmax(X.reshape(shape), dim=-1)
1. 示例
python 代码解读复制代码import torch
import d2l
X = torch.rand(2, 3, 6) # 随机生成一个2x3x6的张量
valid_lens = torch.tensor([3, 5]) # 代表每个序列的有效长度
# 计算掩蔽softmax
masked_softmax_result = masked_softmax(X, valid_lens)
print(masked_softmax_result)
2. 输出
less 代码解读复制代码tensor([[[0.3525, 0.3262, 0.3212, 0.0000, 0.0000, 0.0000],
[0.4367, 0.3333, 0.2300, 0.0000, 0.0000, 0.0000],
[0.3241, 0.4090, 0.2669, 0.0000, 0.0000, 0.0000]],
[[0.1997, 0.2488, 0.2743, 0.1112, 0.1659, 0.0000],
[0.1426, 0.1428, 0.2078, 0.2703, 0.2365, 0.0000],
[0.1072, 0.2731, 0.2692, 0.1078, 0.2427, 0.0000]]])
3. 解释
valid_lens表示每个序列的有效长度。在这个例子中,序列1的有效长度为 ,序列2的有效长度为 。- 在
masked_softmax中,我们会根据valid_lens来掩蔽掉不需要参与计算的部分(例如填充 - 对于序列1,只有前3个位置("我"、"喜欢"和"学习")会参与注意力计算,而填充部分
- 对于序列2,前5个位置("今天"、"是"、"晴天"、"天气"和"很好")会参与注意力计算,剩余的部分
4. 加性注意力(Additive Attention)
概念:
加性注意力是一种计算查询和键之间匹配度的方法,常用于查询和键长度不同的情况。它通过一个神经网络(MLP)计算查询和键的加权得分,然后通过 Softmax 归一化得到注意力权重。
公式:
加性注意力的得分是通过一个多层感知机(MLP)计算的,公式为:
其中:
- 和 是映射查询和键的权重矩阵。
- 是一个激活函数,用于增强模型的非线性能力。
- 是用于得分的权重向量。
注意力权重是通过 Softmax 对得分进行归一化得到的:
具体示例:
场景: 假设我们有两个词(查询和键)和它们对应的值,我们需要计算它们之间的相关性,并基于这些相关性加权求和值。在加性注意力中,查询和键的维度可能不相同,我们使用一个神经网络来计算它们之间的相关性。
- 查询(Query):
q = [2, 3],维度为 2 - 键(Key):
k = [1, 4],维度为 2 - 值(Value):
v = [[10, 20], [30, 40]],维度为 2
加性注意力会计算查询和键之间的匹配度(得分),然后将得分转换为注意力权重,再用这个权重加权求和值。
代码实现:
python 代码解读复制代码class AdditiveAttention(nn.Module):
"""加性注意力(Additive Attention)
通过学习可加权的打分函数(score function)来计算 query 与 key 之间的注意力权重。
"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
"""
初始化加性注意力机制模块。
参数:
key_size: 输入中 key 的特征维度大小。
query_size: 输入中 query 的特征维度大小。
num_hiddens: 用于将 key 和 query 映射到统一空间的隐藏单元数(打分函数中的隐藏层维度)。
dropout: dropout 随机失活比例。
"""
super(AdditiveAttention, self).__init__(**kwargs)
# 将 key 映射到 num_hiddens 维度
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
# 将 query 映射到 num_hiddens 维度
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
# 打分权重,输出为一个标量
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
# dropout 用于注意力权重上防止过拟合
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
"""
计算注意力输出。
参数:
queries: 查询张量,形状为 (batch_size, num_queries, query_size)
keys: 键张量,形状为 (batch_size, num_kv_pairs, key_size)
values: 值张量,形状为 (batch_size, num_kv_pairs, value_dim)
valid_lens: 每个样本中有效 key 的数量,用于掩码无效部分(padding)
返回:
输出张量,形状为 (batch_size, num_queries, value_dim)
"""
# 将 query 和 key 映射到相同维度空间
queries, keys = self.W_q(queries), self.W_k(keys)
# 扩展维度以便广播相加:
# queries: (batch_size, num_queries, 1, num_hiddens)
# keys: (batch_size, 1, num_kv_pairs, num_hiddens)
# 相加后 features: (batch_size, num_queries, num_kv_pairs, num_hiddens)
features = queries.unsqueeze(2) + keys.unsqueeze(1)
# 应用非线性激活函数(加性注意力中使用 tanh)
features = torch.tanh(features)
# w_v 映射到一个打分值,再 squeeze 去除最后一维:
# scores: (batch_size, num_queries, num_kv_pairs)
scores = self.w_v(features).squeeze(-1)
# 对打分进行 masked softmax,掩掉无效的 key
self.attention_weights = masked_softmax(scores, valid_lens)
# 使用注意力权重加权求和 value:
# 输出形状:(batch_size, num_queries, value_dim)
return torch.bmm(self.dropout(self.attention_weights), values)
1. 示例:
python 代码解读复制代码# 示例数据
queries = torch.normal(0, 1, (2, 1, 20)) # 批量大小为2,查询数为1,特征维度为20
keys = torch.ones((2, 10, 2)) # 键的数量为10,特征维度为2
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1) # 值的矩阵
valid_lens = torch.tensor([2, 6]) # 有效长度
# 创建加性注意力模型并计算注意力输出
attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8, dropout=0.1)
attention.eval()
output = attention(queries, keys, values, valid_lens)
print(output)
2. 输出:
less 代码解读复制代码tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=)
3. 解释:queries 和 keys 的维度不同是怎么实现相加的?
- 第一步:
queries和keys分别线性变换到num_hiddens的空间queries.shape: [2, 1, 20] --> [2, 1, 8]keys.shape: [2, 10, 2] --> [2, 10, 8]
- 第二步:通过
features = queries.unsqueeze(2) + keys.unsqueeze(1)进行广播操作,将查询和键的向量扩展成匹配的形状。queries.shape: [2, 1, 8] --> [2, 1, 1, 8]keys.shape: [2, 10, 8] --> [2, 1, 10, 8]- 广播规则触发后:queries 会复制成
[2, 1, 10, 8],keys 会复制成[2, 1, 10, 8] features.shape: [2, 1, 10, 8]
- 第三步:使用
tanh激活函数计算加性得分,然后通过w_v权重计算最终得分:scores.shape: [2, 1, 10] => attention_weights.shape: [2, 1, 10]。 - 第四步:通过 Softmax 计算得到的注意力权重将影响最终输出的加权和。
torch.bmm(attention_weights, values)=>
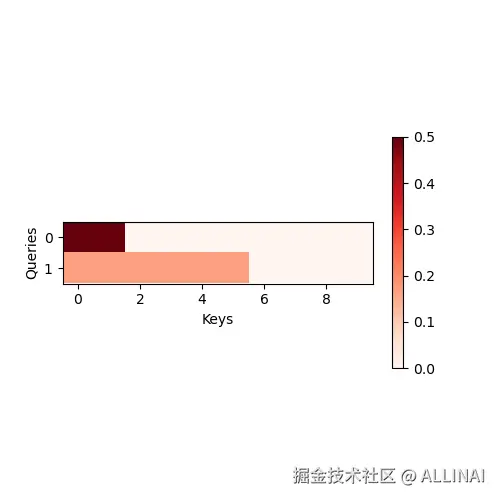
4. 热图:
python 代码解读复制代码d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')
d2l.plt.show()
5. 缩放点积注意力(Scaled Dot-Product Attention)
概念:
缩放点积注意力是一种计算查询(Query)和键(Key)之间相关性的方法。它通过计算查询和键的点积(即两个向量的内积)来得到它们之间的相关性。为了防止点积值过大,通常会对结果进行缩放。
实际示例:
假设我们有一个查询词 "吃",它需要根据这个查询来判断它和候选键之间的相似度。与加性注意力不同,缩放点积注意力直接通过计算查询和键之间的点积来计算它们的相关性。
代码实现
python 代码解读复制代码import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout):
super(DotProductAttention, self).__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1] # 查询和键的维度
# 计算查询和键的点积,注意进行缩放
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
# 计算注意力权重
self.attention_weights = masked_softmax(scores, valid_lens)
# 返回加权求和的值
return torch.bmm(self.dropout(self.attention_weights), values)
1. 示例:
python 代码解读复制代码# 示例:查询和键的维度
queries = torch.normal(0, 1, (2, 1, 2)) # 2 个查询,每个查询有 1 个词,特征维度是 2
keys = torch.ones((2, 10, 2)) # 2 个样本,每个样本 10 个键,每个键的维度是 2
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1) # 10 个值,每个值的维度是 4
valid_lens = torch.tensor([2, 6]) # 每个句子的有效长度
attention = DotProductAttention(dropout=0.5)
output = attention(queries, keys, values, valid_lens)
print(output)
2. 输出:
less 代码解读复制代码tensor([[[ 0.0000, 1.0000, 2.0000, 3.0000]],
[[ 8.0000, 9.3333, 10.6667, 12.0000]]])
3. 解释:
DotProductAttention类通过计算查询和键之间的点积来衡量它们的相关性,并对点积结果进行缩放。- 计算出注意力权重后,输出是这些权重加权求和的值。
6. 小结
- 注意力评分函数决定了查询与键的匹配程度,影响最终的注意力权重。
- 掩蔽 Softmax 用于屏蔽无效位置,确保计算时不受填充影响。
- 加性注意力 适用于查询和键长度不同的情况,计算复杂度较高。
- 缩放点积注意力 计算更高效,适用于查询和键长度相等的情况。
理解这些基础知识后,我们可以更深入地学习多头注意力(Multi-Head Attention)和自注意力(Self-Attention),这将在 Transformer 结构中发挥重要作用!
评论记录:
回复评论: