
爆改RagFlow
- 一、Rag理论概述
- 二、Ragflow解析参数说明
- 三、♥ RagFlow源码解析
-
- ==核心代码流程梳理==
-
- 1、OCR识别
- 2、版面分析
- 3、parser功能
-
- ==3.1 PdfParser==
- [来自工业界的知识库 RAG 服务(二),RagFlow 源码全流程深度解析](https://blog.csdn.net/hustyichi/article/details/139162109?ops_request_misc=&request_id=&biz_id=102&utm_term=ragflow%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-139162109.nonecase&spm=1018.2226.3001.4187) 重要点梳理
- 任务1:对解析后的文档的某些字段挖空
一、Rag理论概述
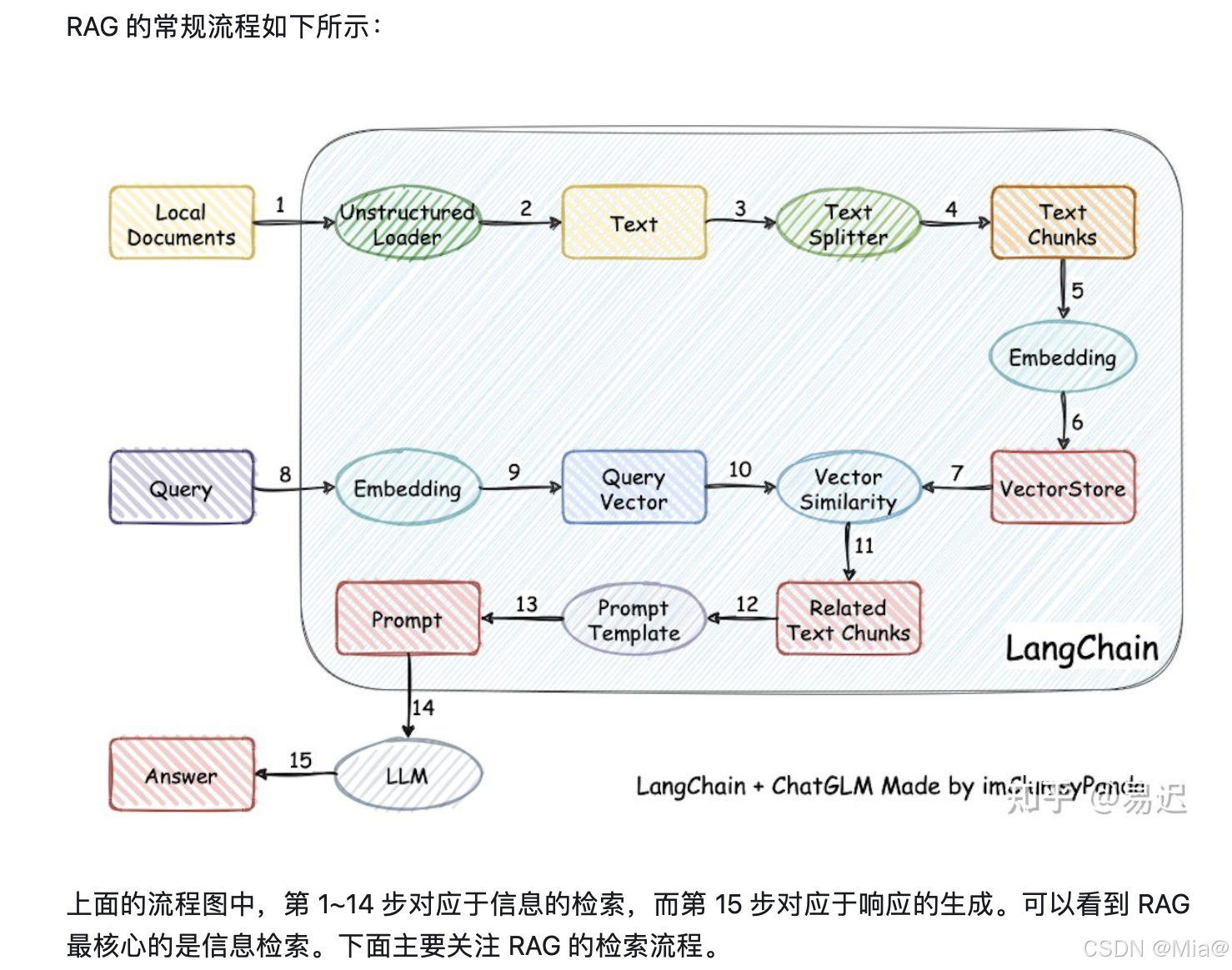


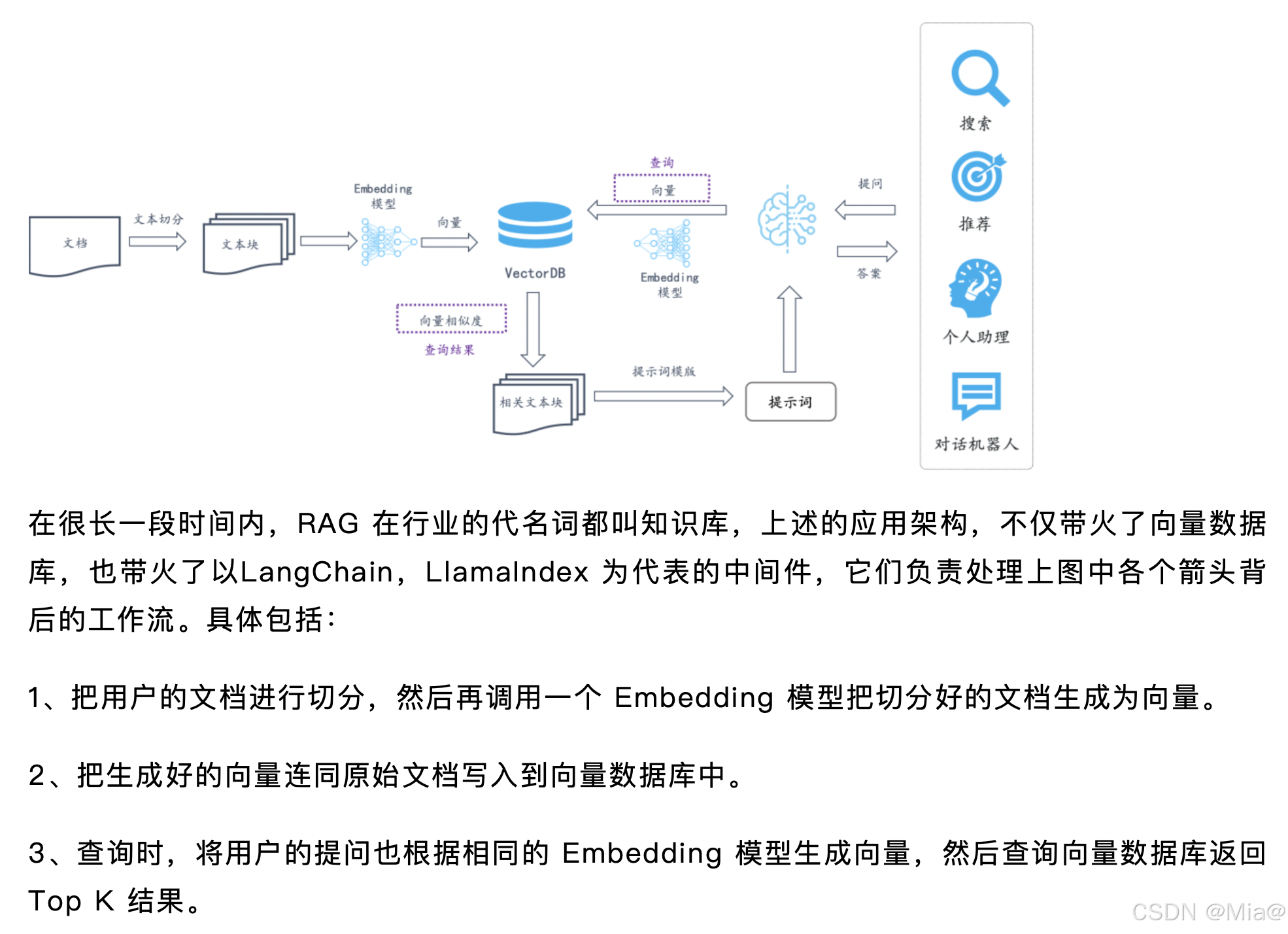

二、Ragflow解析参数说明



三、♥ RagFlow源码解析
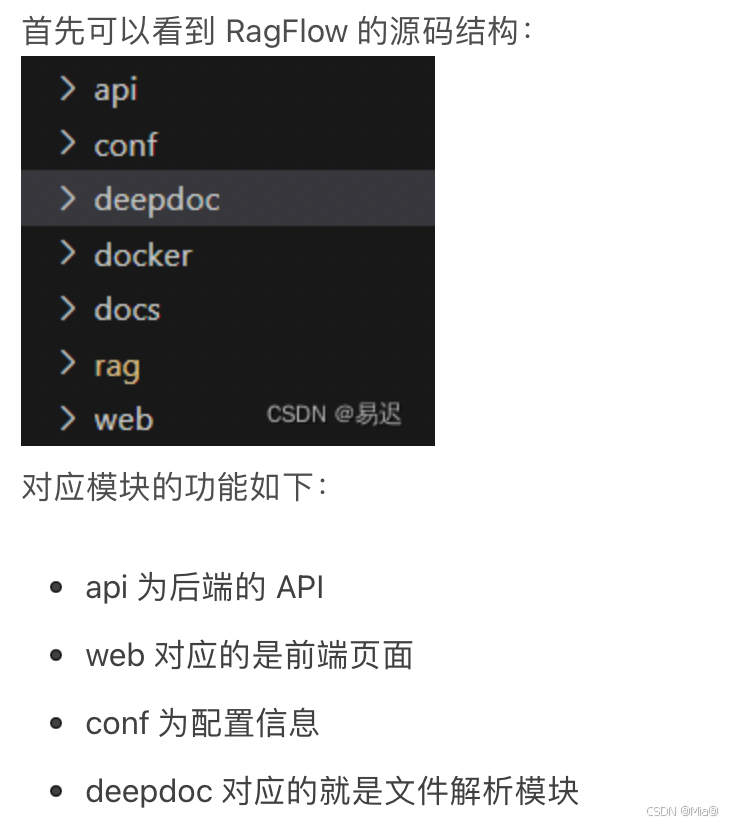

核心代码流程梳理
DeepDoc的模型应该是基于paddleOCR的模型去微调训练的,开源出来的模型是onnx格式的
1、OCR识别
主要代码在ocr.py里——"E:\ragflow-main\deepdoc\vision\ocr.py"
TextRecognizer 做文字识别,TextDetector 做文本框检测,OCR整合检测和识别功能,对外提供调用

2、版面分析
版面分析主要在recognizer.py和layout_recognizer.py里:
"E:\ragflow-main\deepdoc\vision\recognizer.py"和"E:\ragflow-main\deepdoc\vision\layout_recognizer.py"
LayoutRecognizer 继承Recognizer的类,用于对文档图像进行板式分析,识别不同类型的区域,例如表格、标题、段落等。这里用的模型应该还是基于paddleocr里的版面分析模型去优化的。
Recognizer的__call__ 方法,传入图像列表和置信度阈值
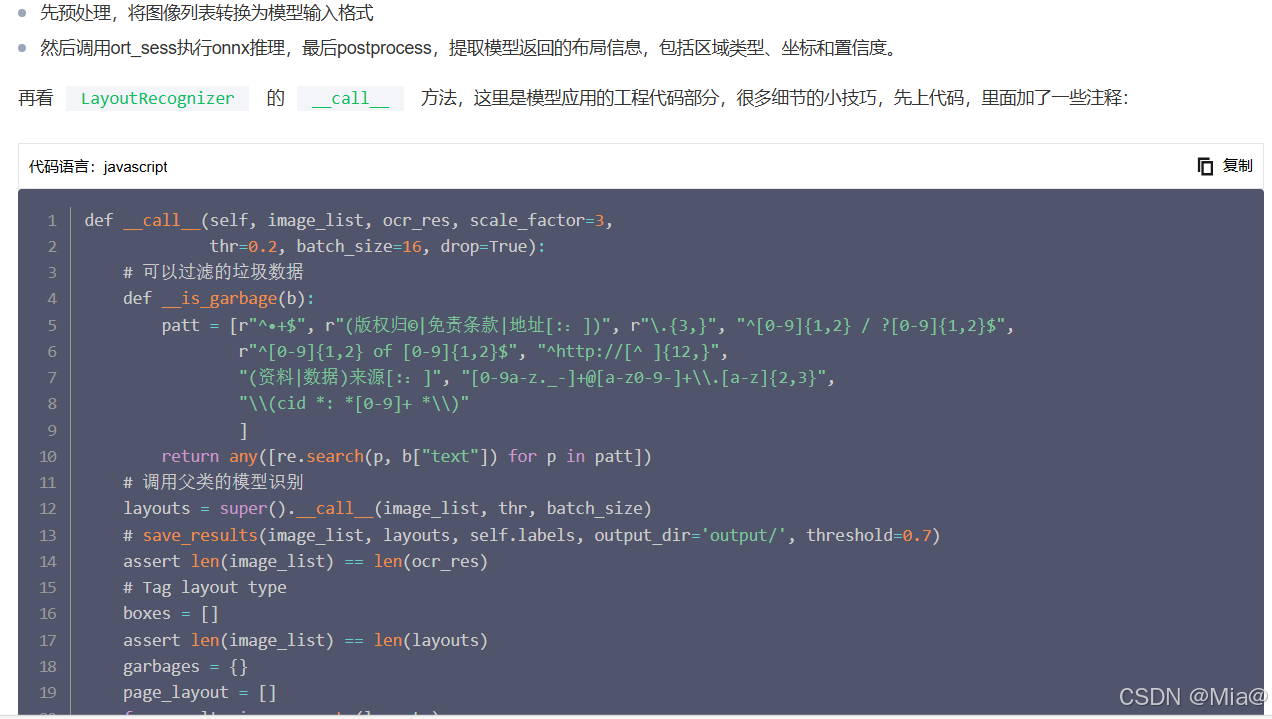
3、parser功能
OCR和版面分析,都是为parser服务的,parser负责解析文档,并拆分为chunk.
框架提供了PdfParser、PlainParser、DocxParser、ExcelParser、PptParser 5种解析器。另外针对resume,提供了专门的简历解析功能
3.1 PdfParser
我们挑选重点的==PdfParser ==也就是HuParser来分析。
3.1.1 首先,初始化
def __init__(self):
self.ocr = OCR()
if hasattr(self, "model_speciess"):
self.layouter = LayoutRecognizer("layout." + self.model_speciess)
else:
self.layouter = LayoutRecognizer("layout")
self.tbl_det = TableStructureRecognizer()
self.updown_cnt_mdl = xgb.Booster()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对表格结构的识别需要OCR、LayoutRecognizer,以及TableStructureRecognizer互相配合,一般都是模型搭配大量的工程trick,靠一些规则来解决一些边界情况。文档解析也是这样,需要多个模型配合,结合一些规则来做,这些规则通常是经验的集合,大白话就是各种case跑出来,遇到问题就加新的规则
***************PdfParser核心的__call__
def __call__(self, fnm, need_image=True, zoomin=3, return_html=False):
# 转图片,处理文本,ocr识别
self.__images__(fnm, zoomin)
# 版面分析
self._layouts_rec(zoomin)
# table box 处理
self._table_transformer_job(zoomin)
# 合并文本块
self._text_merge()
self._concat_downward()
# 过滤分页信息
self._filter_forpages()
# 表格和图表抽取
tbls = self._extract_table_figure(
need_image, zoomin, return_html, False)
# 抽取的文本(去掉表格), 表格
return self.__filterout_scraps(deepcopy(self.boxes), zoomin), tbls

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

3.1.2 pdf转图片
先读PDF文件
def __images__(self, fnm, zoomin=3, page_from=0,
page_to=299, callback=None):
self.lefted_chars = []
self.mea- 1
- 2
- 3
评论记录:
回复评论: