
阅读提示:我今天才开始尝试爬虫,写的不好请见谅。
一、准备工具
- requests库:发送HTTP请求并获取网页内容。
- BeautifulSoup库:解析HTML页面并提取数据。
- pandas库:保存抓取到的数据到CSV文件中。
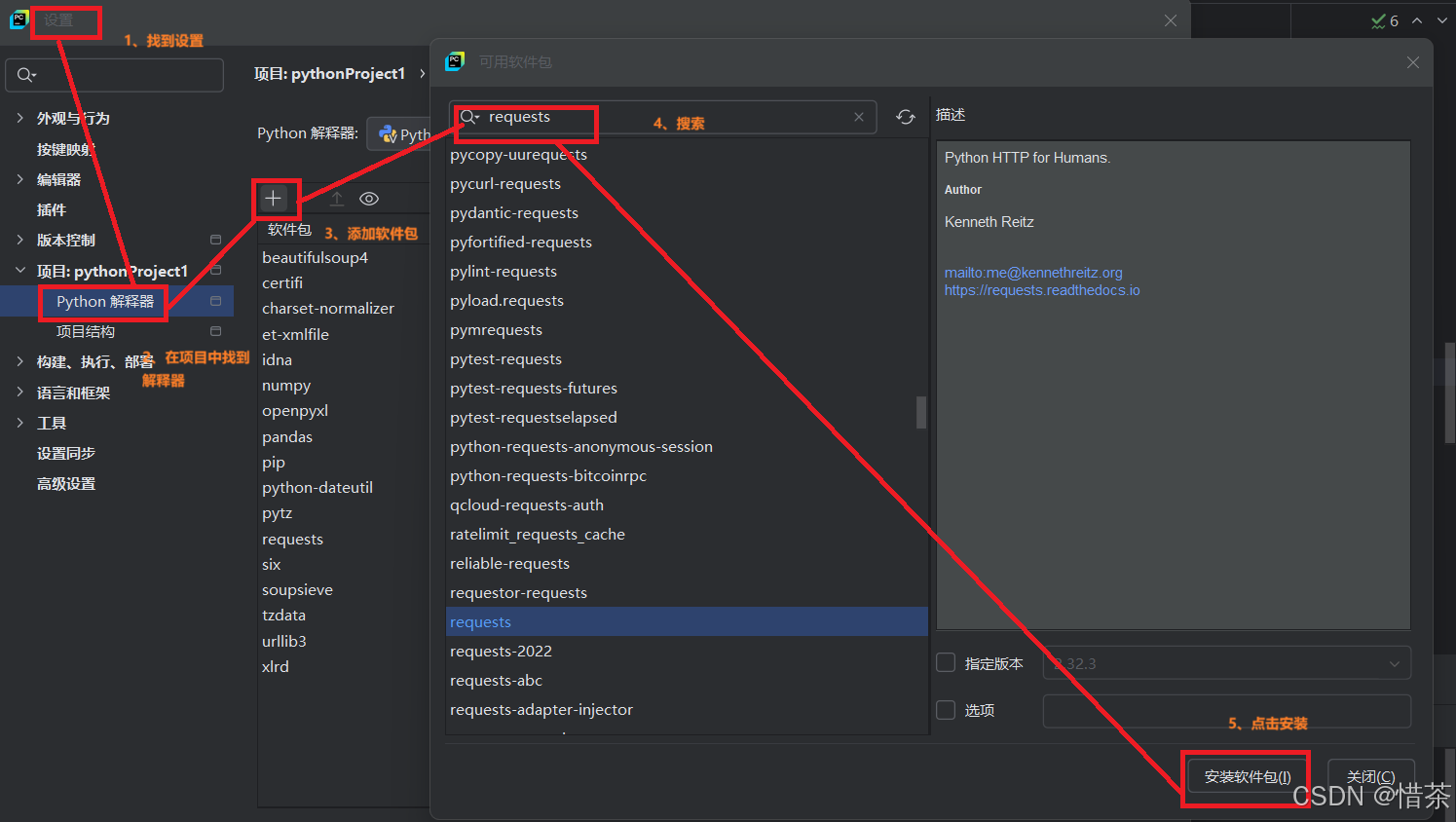
二、爬取步骤
- 发送请求: 对于目标网页,使用
requests.get()发送HTTP请求并获取网页的HTML内容。 - 解析HTML: 使用
BeautifulSoup解析网页,并寻找包含信息的HTML元素。 - 提取数据: 找到合适的HTML标签和类名,提取信息。
- 分页爬取: 如果网站有分页,可以在代码中处理分页逻辑,循环抓取每一页的数据。
- 保存数据: 使用
pandas或内置的文件写入功能,将抓取到的数据保存到CSV文件中。
三、爬虫代码
网页
- <div class="pic">
- <em>1em>
- <a href="https://movie.douban.com/subject/1292052/">
-
![]() 100" alt="肖申克的救赎" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp">
100" alt="肖申克的救赎" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp"> -
-
">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
v:average">9.7
" content="10.0">
3148544人评价
">
希望让人自由。

爬虫代码:(我这里只爬虫了一部分)
-
- from bs4 import BeautifulSoup
- import requests
- import pandas as pd
-
- def getFilm():
- try:
- # 添加请求头
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
- }
-
- # 获取网页内容
- res = requests.get("https://movie.douban.com/top250?start=0&filter=", headers=headers, timeout=10)
- res.encoding = 'utf-8' # 修正编码设置
-
- # 解析网页
- soup = BeautifulSoup(res.text, 'html.parser')
-
- # 获取数据
- film_data=soup.find('div',class_='hd')
- if not film_data:
- print("未找到信息")
- print(res.status_code) # 应该是200
- return None
- name=soup.find('span',class_='title').text.strip()
- score=soup.find('span',class_='rating_num').text.strip()
- word=soup.find('p',class_='quote')
- dictum=word.find('span').get_text()
- df=pd.DataFrame({'电影名':[name],'评分':[score],'寄语':dictum})
- return df
-
- except Exception as e:
- print(f"发生错误: {e}")
- return None
-
- def main():
- df= getFilm() # 修正变量名
- if df is not None:
- print(df) # 打印DataFrame
- else:
- print("未能获取数据")
-
- if __name__ == '__main__':
- main()
-

四、拓展(设置请求头)
请求头(HTTP Headers)是客户端(如浏览器或爬虫)在发送 HTTP 请求时,附带的一组 键值对(Key-Value)信息,用于告诉服务器 你是谁、你想获取什么、以及如何返回数据。
| 请求头字段 | 示例值 | 作用 |
| User-Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64) | 告诉服务器你的浏览器或设备类型 |
| Accept | text/html,application/xhtml+xml | 告诉服务器你希望接收的数据类型 |
| Accept-Language | zh-CN,zh;q=0.9 | 告诉服务器你希望返回的语言 |
| Referer | https://www.google.com/ | 告诉服务器你从哪个页面跳转过来 |
| Host | movie.douban.com | 告诉服务器你要访问的域名 |
| Cookie | sessionid=abc123 | 用于身份验证(如登录状态) |
| Connection | keep-alive | 控制 TCP 连接是否保持 |
| Accept-Encoding | gzip, deflate | 告诉服务器你支持的压缩方式 |
评论记录:
回复评论: