
目录
(五)小结:Retrieval 是 RAG 系统中的“地基工程”
三、索引优化策略(Indexing Optimization)
(二)元信息附加(Metadata Attachments)
2. 知识图谱索引(Knowledge Graph Index)
四、Query Optimization:提升查询质量以增强 RAG 精度
(一) 查询扩展(Query Expansion):丰富原始问题,增强上下文语义
Chain-of-Verification (CoVe) 验证链
(二)查询转换(Query Transformation):优化问题表达以匹配知识结构
2. HyDE(Hypothetical Document Embedding)
(三)查询路由(Query Routing):根据语义将查询分流至最合适的检索路径
五、向量化嵌入与语义召回 —— Embedding 的核心作用与进化
2. Retriever 与 Generator 对齐(Alignment)
六、插件式适配器的兴起 —— 在有限资源下释放 RAG 潜能
(一)UPRISE:自动提示检索器(Prompt Retriever)
(二)AAR:通用型适配器(Augmentation-Adapted Retriever)
(三)PRCA:奖励驱动的上下文适配器(Pluggable Reward-Driven Contextual Adapter)
(四)BGM:桥接模型 Bridge Seq2Seq 的动态适配
(五)PKG:白盒模型的指令式知识整合(Prompt-aware Knowledge Grounding)
干货分享,感谢您的阅读!
在 Retrieval-Augmented Generation(RAG)体系中,Retrieval 模块是整个流程的“信息引擎”。它承担着连接大语言模型(LLM)与外部知识源的关键职责,其性能直接影响生成内容的准确性、相关性与可靠性。一个优秀的检索系统,必须在速度、精度与可扩展性之间取得平衡。
本节将围绕 检索源、检索粒度、检索预处理、嵌入模型的选择 四个核心维度展开探讨,并结合实际应用中常见的技术实践进行分析。
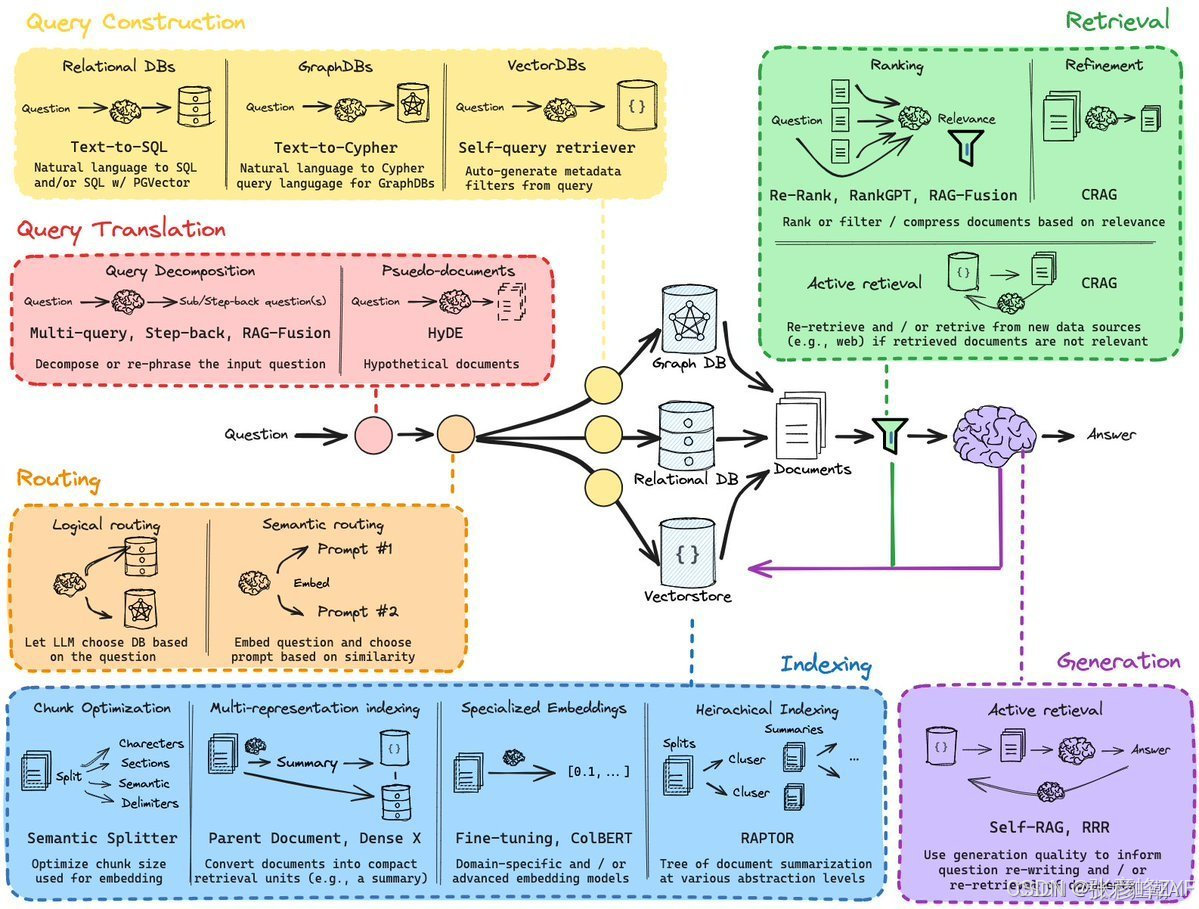
一、知识注入的关键前奏——RAG 系统中的检索综述
随着大语言模型(LLM)能力的飞速提升,Retrieval-Augmented Generation(RAG)成为融合外部知识与生成模型的关键架构,广泛应用于智能问答、企业知识库、代码助手、搜索引擎等场景。而在整个 RAG 架构中,Retrieval 模块不仅是知识注入的起点,更是影响生成结果准确性与可信度的决定性因素。
(一)模块定位:连接语言模型与知识世界的桥梁
RAG 的核心思想是将大语言模型的“生成能力”与外部知识的“事实性”结合起来。而 Retrieval 模块正是这一结合的“中介”:
- 上游连接 Embedding 向量空间与文档库
- 下游为 LLM 提供上下文提示(Prompt)或检索结果
它通过将用户查询语句转化为向量,检索语义相近的文档片段,并作为“上下文知识”注入 LLM,使生成结果更具相关性、事实性、实时性。
(二)核心任务:四大关键问题的协调解法
Retrieval 模块并非单一任务,而是由多个技术子任务协同完成,每个环节都对检索质量产生深远影响:
| 核心问题 | 技术挑战 | 工程影响 |
|---|---|---|
| 检索源选择 | 数据结构多样、更新频率不一 | 决定知识范围与质量 |
| 检索粒度设置 | 粒度太大冗余、太小丢上下文 | 决定召回效率与相关性 |
| 文本预处理 | 噪声、格式不统一、段落不连贯 | 决定语义清晰度 |
| 嵌入模型选型 | 模型能力、速度、适配性差异大 | 决定语义向量质量 |
这些问题彼此关联,例如粒度与预处理策略相互影响,嵌入模型的选择又受数据域特性制约,因此构建高效 Retrieval 系统需要在技术合理性与工程可行性之间寻找最佳平衡点。
(三)系统特征:性能、精度与可扩展性的三角权衡
一个优秀的检索模块,在系统设计上需要具备以下三大能力:
- 高相关性(Relevance):召回内容需紧密贴合用户意图;
- 高可扩展性(Scalability):应支持百万量级文档与并发查询;
- 低响应延迟(Latency):适配在线生成、实时问答等场景。
这三者构成经典的“系统三角”,在不同场景中取舍各异。例如,企业内部知识问答倾向优先相关性与可扩展性,而在线搜索助手则对响应延迟尤为敏感。
(四)应用视角:从技术模块走向业务场景
在工程实践中,Retrieval 不仅仅是技术组件,更深刻地影响业务可用性:
- 在 金融问答系统 中,检索的精确度直接影响合规风险;
- 在 代码生成助手 中,检索粒度影响生成代码的上下文质量;
- 在 企业知识库 中,知识时效性要求检索支持动态增量更新。
因此,构建 Retrieval 模块时应不仅考虑模型与算法,还需立足业务场景,用系统视角理解“可用的知识检索”,才能真正释放 RAG 架构的潜能。
(五)小结:Retrieval 是 RAG 系统中的“地基工程”
如果将 LLM 视作 RAG 架构中的“语言天赋”,那么 Retrieval 就是决定生成结果“靠不靠谱”的知识地基。只有构建起精准、高效、可扩展的检索能力,后续的生成与对齐模块才能发挥最大效用。
在后续章节中,我们将深入剖析 Retrieval 模块中的各个关键子问题,包括:
- 检索数据源的选型与管理;
- 文本切分策略与粒度控制;
- 向量化处理与嵌入模型评估;
- 向量检索系统的技术选型与优化。
通过技术原理与工程案例的结合,我们将逐步揭示如何打造一个面向生产的高质量检索系统,为 RAG 架构的实际落地奠定坚实基础。
二、外部知识的类型与粒度 —— RAG 数据源的发展与演进
在 Retrieval-Augmented Generation(RAG)架构中,“检索数据源”(Retrieval Source)的选择及其“粒度划分”(Granularity)策略,直接决定了模型生成的准确性、上下文契合度以及任务表现。因此,理解不同类型的数据源及其粒度演化,是深入掌握 RAG 技术演进路径的关键一环。
我们围绕两个核心维度展开分析:
- 检索数据源的类型(结构化 vs 半结构化 vs 非结构化 vs 自生内容)
- 检索单元的粒度(Token、句子、段落、文档等)
并以图表和代表性方法为例,系统性解析现有技术路线。
(一)检索数据源的多样化趋势
1. 非结构化数据:RAG 最早的原始形态
RAG 最初依赖的大多为非结构化文本数据,如 Wikipedia、Common Crawl、开放问答语料等。这类数据具有覆盖广泛、内容丰富的特点,特别适合开放领域问答(ODQA)场景。典型数据版本如:
- Wikipedia HotpotQA(2017年)
- DPR Wikipedia Dump(2018年)
随着任务不断深化,RAG 模型也开始使用跨语言数据(如 CREA-ICL)以及特定领域数据(如医学、法律等)进行检索增强,以提升领域适应能力。
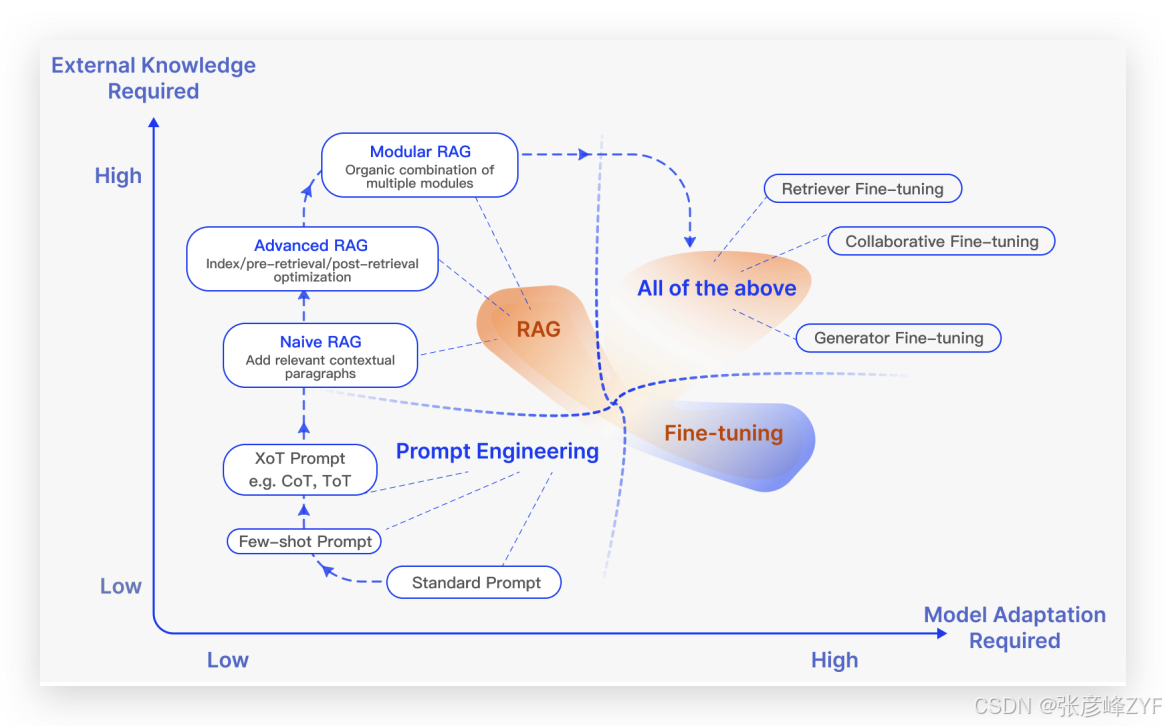
如图所示展示了各类模型在“是否需要外部知识”和“是否需改动模型结构”两方面的权衡。RAG 初期偏向“低改动+高利用”的 Prompt Engineering 路线,随着 Modular RAG 的提出,则向深度整合 Fine-tuning 方向演进。
2. 半结构化数据:复杂文本结构带来的挑战
随着文本内容向 PDF 等富文档形式发展,RAG 面临了新的挑战。PDF 通常包含文本与表格混排信息,传统的分词策略可能会错误切割表格,导致信息语义被破坏。另一方面,检索引擎在进行语义相似性计算时,也难以有效处理嵌套结构的数据。
研究者尝试了如下策略以解决这一问题:
- 利用 LLM 的代码生成能力,生成 Text-to-SQL 查询(如 TableGPT);
- 将表格结构转换为自然语言,再作为普通文本处理(如 PKG);
尽管初具成效,但现有方案仍不完美,表明这是未来 RAG 在“文档-表格混合场景”下的重要研究方向。
3. 结构化数据:引入知识图谱以提升精准性
结构化数据如知识图谱(Knowledge Graph, KG)为 RAG 带来更高的准确性与逻辑一致性。例如:
- KnowledGPT 通过生成结构化查询并存入用户定制的 KB,实现对 LLM 的知识增强;
- G-Retriever 融合图神经网络(GNN)与 PCST 优化算法,对知识图进行结构检索,提升 LLM 对图结构语义的理解能力;
然而,构建与维护结构化数据代价较高,需要大量人工验证与更新,这限制了其大规模应用的可扩展性。
4. LLM 自生内容:向“自我增强”过渡
除外部数据源外,部分研究关注于LLM 内部生成内容的再利用,通过“模型记忆”或“生成代检索”等方式构建新型反馈循环:
- SelfMem:迭代生成高质量记忆池,通过检索-生成-回填实现自我增强;
- GenRead:用 LLM 直接替代检索器生成上下文内容,其生成内容往往更契合语言模型的预训练目标;
- SKR:判断问题是否为“未知知识”,并选择性启用检索增强;
这些方法在一定程度上减少了对外部知识源的依赖,打开了模型内部知识激活与结构重用的新思路。
(二)检索粒度的演进与策略选择
除数据源类型外,检索粒度同样决定了最终生成效果的上下文质量和可控性。
1. 粒度维度与分类
目前主流粒度类型从细到粗可分为:
- Token(单词级别)
- Phrase(短语)
- Sentence(句子)
- Proposition(命题)
- Chunk(段落/子文档)
- Document(整篇文档)
- Multi-Source(多种异构结合)
下表系统整理了不同方法的检索粒度及使用场景。

从中可以看出:
- DenseX 提出了“命题级”(Proposition)检索单元的概念,即以信息最小闭包单元作为粒度,兼顾上下文完整性与语义准确性;
- RAG-Robust、RETRO++、Self-RAG 等更倾向于使用 Chunk(段落)作为单元,便于与 LLM 进行上下文拼接;
- 文档级(Document)检索如 RePLUG、DSP 更适用于长上下文生成任务;
- 精细控制粒度选择的方案如 SKR、Self-RAG 提出Adaptive Granularity概念,可动态根据任务需求进行粒度调节;
2. 粒度选择的权衡逻辑
- 粗粒度(Chunk/Doc):上下文信息更完整,但可能引入冗余内容干扰模型注意力;
- 细粒度(Phrase/Sentence):信息密度更高,便于精确匹配,但容易丢失语义上下文完整性;
- 适配性粒度策略:如 FLARE 使用 Adaptive 方式在推理时动态选择最佳粒度,平衡性能与精度;
粒度选择不仅影响检索精度,也影响生成速度与内存消耗。因此,如何设计任务驱动的粒度调控机制,仍是当前研究的重点。
(三)小结与趋势洞察思考
从本章的系统梳理中我们可以看出:
- 数据源维度:RAG 正从“单一文本源”逐渐扩展至“结构化+半结构化+自生内容”多元融合格局;
- 粒度控制维度:由固定粒度向任务适配、上下文动态调节的方向演进;
- 未来趋势:
- 更智能的数据类型识别与粒度匹配策略;
- 利用多模态信息(图文表)进行统一检索;
- 检索与生成的融合边界将逐渐模糊,向“生成即检索”的统一范式发展。
RAG 在数据利用上的演进不仅扩展了语言模型的“知识边界”,也促使生成模型的行为逐步具备“搜索、理解与选择”的能力,未来仍有广阔的创新空间值得探索。
三、索引优化策略(Indexing Optimization)
在 RAG 系统的构建流程中,索引阶段承担着将原始文档处理为可被检索利用的嵌入向量(Embeddings)的关键任务。该阶段通常包括文档切分、向量转换和存入向量数据库等步骤。索引质量的高低,直接决定了后续检索阶段能否获得与问题高度相关的上下文,因此索引构建不仅是预处理的一环,更是对生成效果的前置保障。
评论记录:
回复评论: