
在数据库的江湖里,批量插入就是一门顶级内功。虽然它不像“分布式事务”那样炫酷,也没有“CAP理论”那么玄妙,但它关乎性能、关乎优雅,更关乎一颗程序员的秃头能不能在五年后依然坚守阵地。
批量插入是什么?简单说,就是把一车苹果塞进数据库,而不是一颗颗扔进去。你可能觉得这是常识,但如果说我们把一百个苹果丢进数据库竟然能慢到让老板生疑,甚至质问你是不是趁机偷摸去吃了十几个……嗯,这就有问题了。
为什么批量插入重要?
想象一下,你在餐馆点了一百份炸鸡。如果服务员每送来一块鸡腿就跑回厨房一趟,这饭还怎么吃?效率高的做法是直接推辆小车,把一百块炸鸡一次送到你面前,这就是批量插入的精髓——少跑路,快上菜。
在现实开发中,程序员面临的挑战是这样的:
- 单条插入慢如蜗牛:一个一个插入,等数据量大了,慢得令人发指。
- 不做批量就会拖垮系统:插入1000条数据的网络请求,硬生生搞出了1000次数据库交互,浪费了无数带宽、CPU、内存。
- 批量插入并非一劳永逸:数据库也有自己的脾气,插得多不一定快,设计不好可能还会搞垮索引。
本文要讲什么
这篇文章不是来教你如何 “用力插入” 的,而是基于一个笔者真实遇到的调优过程来揭示批量插入的真相:不同场景下,不同技术方案的优劣,以及那些隐藏在深处的性能杀手。
我们会聊聊这些问题:
- MyBatis-Plus 的批量插入:是不是拿着开箱即用的工具就能通杀所有场景?
- InsertBatchSomeColumn 究竟“香不香”?为啥它理论上效率爆表,但用起来还得小心翼翼?
- 什么场景下批量插入会变成“批量插雷”?索引、表结构、事务管理,这些让你崩溃的细节我们一一扒光。
以上内容均非空谈,我们会通过一个真实的项目,用一个业务、不同数据量和多种插入方式,还原批量插入在性能上的真实表现。
谁适合读这篇文章?
- 如果你正在开发数据导入功能,并被性能问题困扰,请继续往下读。
- 如果你的数据库插入慢到老板发出灵魂拷问——“这也叫优化?”——那更要读。
- 如果你只是想装个懂数据库性能的大佬,这篇文章也能让你在技术会议上发出“嗯,这个我研究过”的点头声。
批量插入的江湖,没有最优解,只有最适合的策略。接下来,我们一起揭开这门技术的神秘面纱,找到属于你的答案。
数据插入的江湖
初入江湖
这个江湖开始于笔者正在做的一个项目,一个仿腾讯云 IM 的开源即时通讯接入平台:菜鸟 IM;在用户相关服务构建的过程中,涉及到一个很简单的 API - 批量导入用户。 这里就不过多赘述系统开发设计的业务背景,有兴趣的朋友可以去仓库查看。但看似简单的“批量导入”,却暗藏杀机,我们先来看代码:
java 代码解读复制代码...
// 分批处理用户数据
List> userDataBatches = partitionList(importUserReq.getUserData(), 100);
ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() * 2);
List> tasks = new ArrayList<>();
for (List batch : userDataBatches) {
tasks.add(() -> {
List imUserDataList = batch.stream()
.map(data -> ImUserAdapter.buildImUserData(data, appId))
.collect(Collectors.toList());
try {
// 批量插入
imUserDataDao.saveBatch(imUserDataList);
imUserDataList.forEach(user -> successId.add(user.getUserId()));
} catch (Exception e) {
log.error("批量插入失败: {}", e.getMessage(), e);
imUserDataList.forEach(user -> failedId.add(user.getUserId()));
}
return null;
});
}
try {
executor.invokeAll(tasks);
} catch (InterruptedException e) {
log.error("任务中断: {}", e.getMessage(), e);
} finally {
executor.shutdown();
}
...
一上来我们就并发和批量两套组合拳,我相信没有什么数据量能在两套招式下还能拖慢我们的后腿。简单来说:
- 我们首先将用户数据按每批 100 条分成若干批次,便于分块处理,避免一次性处理大量数据导致内存或数据库性能问题。
- 紧接着我们创建一个固定大小的线程池,用于并发执行批量插入任务。
- 遍历分批后的数据列表,为每一批创建一个任务,并加入 tasks 列表。
- 调用
executor.invokeAll(tasks)批量执行所有任务。 这里的核心在于分片和多线程,但是我们的关注点需要放在imUserDataDao.saveBatch上,这是 MyBatis Plus 提供的一个批量插入数据库的方法;我们来看下他的表现,我们来构造一组20 条的数据,先来试个水: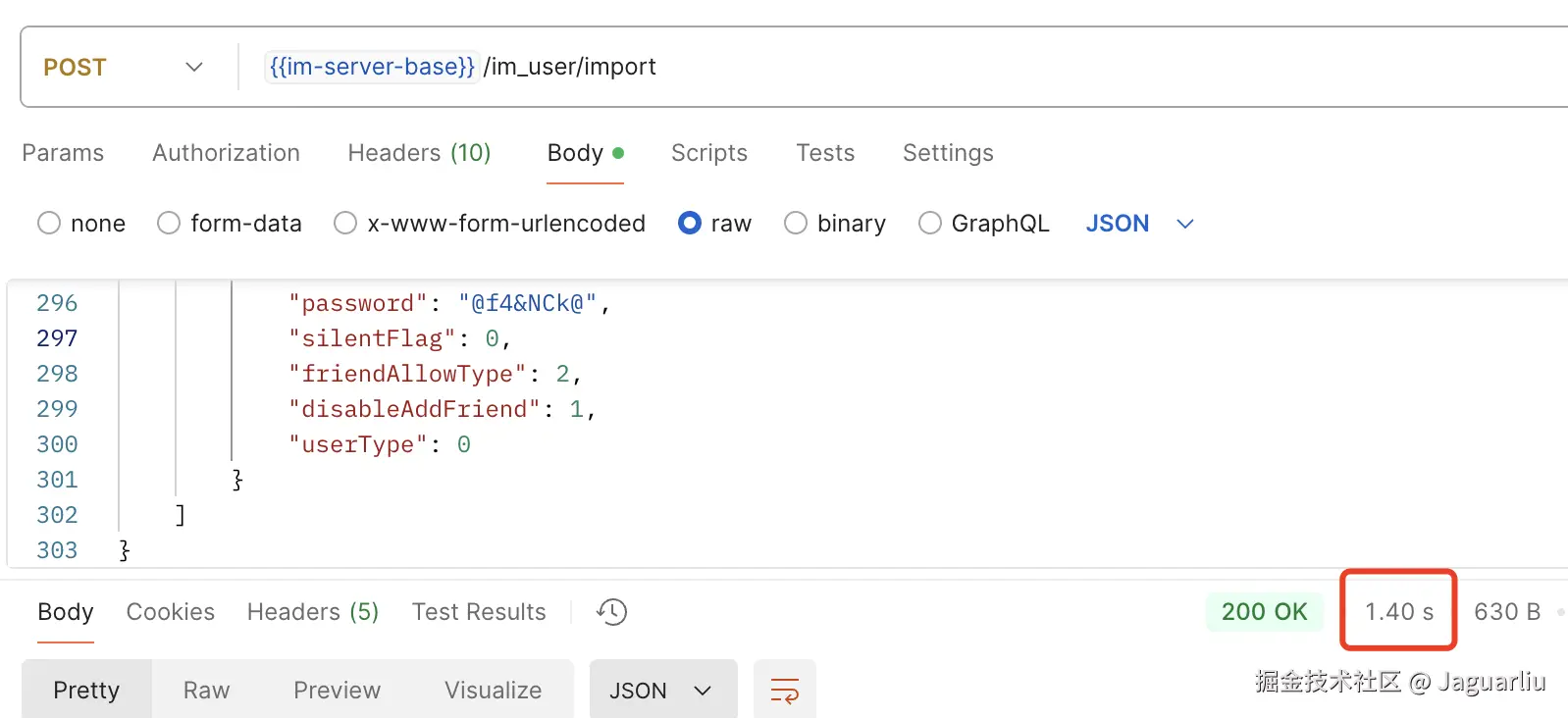 很难想象,20 条数据的插入居然花费了 1.4s。这让人难以接受。要知道,现代数据库插入一条简单记录的耗时通常在毫秒级,1.4 秒的表现仿佛让我们回到了拨号上网的年代。那么,问题出在哪里?
很难想象,20 条数据的插入居然花费了 1.4s。这让人难以接受。要知道,现代数据库插入一条简单记录的耗时通常在毫秒级,1.4 秒的表现仿佛让我们回到了拨号上网的年代。那么,问题出在哪里?

问题分析
面对这样令人发指的性能问题,我们需要冷静拆解,逐层分析瓶颈可能存在的地方:
是 saveBatch 本身的问题吗?
saveBatch 是 MyBatis-Plus 提供的一个常用批量插入方法。它背后其实是循环调用批量 SQL 的封装,也就是说:
- 它会将数据按照指定批次大小拆分(默认 1000 条),然后一批一批执行插入。
- 每一批次都会生成类似这样的 SQL:
INSERT INTO table (col1, col2) VALUES (val1, val2), (val3, val4), ...;如果没有复杂逻辑,单批插入的性能应该很高。
问题看来并不出现saveBatch,吗?经过进一步查阅 MyBatis-Plus 的文档,我们发现问题并不是出现在 saveBatch 本身的实现逻辑上,而是出在默认配置没有启用关键功能。要想让 saveBatch 发挥真正的批量插入威力,需要确保 MyBatis-Plus 的批量操作配置正确。
MyBatis-Plus 的 saveBatch 方法依赖于底层的 JDBC 批量处理功能。默认情况下,许多开发者会忽略这一点,从而导致实际执行的插入操作退化为逐条执行。所以我们需要在项目的配置文件(application.yml)中,添加rewriteBatchedStatements=true的配置。
 ok~这下应该搞定了吧,批量插入的问题要被我们解决了!我们再来 20 条数据看看。
ok~这下应该搞定了吧,批量插入的问题要被我们解决了!我们再来 20 条数据看看。
 立竿见影,就没见过这么快的~1.4s 到 400ms 的优化,只是因为我们添加了一个配置。好了,神功大成,我们无敌了。
立竿见影,就没见过这么快的~1.4s 到 400ms 的优化,只是因为我们添加了一个配置。好了,神功大成,我们无敌了。
但是,如果你真实的去实践了,去观察了执行的控制台日志输出后,你会发出和我一样的疑问:这不还是一条一条插入的吗?
 从控制台输出日志可以看出,这里 MyBatis-Plus 实现的批量插入和我们常规印象中的批量好像不是一个概念,我们期望的批量插入是:
从控制台输出日志可以看出,这里 MyBatis-Plus 实现的批量插入和我们常规印象中的批量好像不是一个概念,我们期望的批量插入是:
sql 代码解读复制代码INSERT INTO table_name (col1, col2, col3)
VALUES
(val1, val2, val3),
(val4, val5, val6),
(val7, val8, val9);
单条 SQL,插入多行数据;同时我也可以分批控制以及可以控制单次的事务;理论上来讲,只要单条插入数据的性能不是瓶颈,这种使用 sql 的方式应该是最快的批量插入;因此我就产生了两个疑问: MyBatis-Plus 为什么没有这样做?拼接 sql 的方式能让我快多少?
saveBatch 是如何实现的
想要搞清楚 MyBatis-Plus 的批量插入为什么看起来像是一个骗局?我们首先得搞明白它的基础——JDBC 的批量提交机制。
JDBC 的批量提交机制
在 JDBC 中,批量提交是通过 Statement 或 PreparedStatement 的 addBatch() 和 executeBatch() 方法实现的。它的核心思想是将多条 SQL 操作放入一个批量中,减少与数据库的交互次数,从而提升性能。 通过一段代码我们来了解下:
java 代码解读复制代码try (Connection connection = dataSource.getConnection()) {
String sql = "INSERT INTO table_name (col1, col2, col3) VALUES (?, ?, ?)";
try (PreparedStatement pstmt = connection.prepareStatement(sql)) {
for (int i = 0; i < 1000; i++) {
pstmt.setString(1, "value1-" + i);
pstmt.setInt(2, i);
pstmt.setString(3, "value3-" + i);
pstmt.addBatch(); // 将语句加入批量
}
pstmt.executeBatch(); // 批量执行
}
}
在这段代码中:
- addBatch():将 SQL 添加到批次中。
- executeBatch():一次性执行批次中的所有 SQL。
- 性能提升:
- 减少网络交互:批量提交的所有 SQL 通过一次网络请求发送给数据库。
- 减少事务开销:如果不手动控制事务,默认情况下整个批量操作在一个隐式事务中完成。
也就是说,我们忽略分批的情况下,默认一批次的数据插入,不会一条一条的执行,而是批量打包为一个 insert 语句包,一次性的丢给数据库去执行;这个过程只需要一次网络传输,而且一个批次的所有记录共用一条 SQL 模板。
了解完 JDBC 的批量提交机制之后,我们来看看saveBatch的源码是如何实现的。
saveBatch源码分析
先看看 saveBatch 的核心实现,这里直接引出一个关键方法:
java 代码解读复制代码public static boolean executeBatch(SqlSessionFactory sqlSessionFactory, Log log,
Collection list, int batchSize,
BiConsumer consumer) {
// 1. 校验批次大小是否有效
Assert.isFalse(batchSize < 1, "batchSize must not be less than one");
// 2. 如果集合为空,直接返回 false
return !CollectionUtils.isEmpty(list) && executeBatch(sqlSessionFactory, log, sqlSession -> {
int size = list.size(); // 数据总量
int idxLimit = Math.min(batchSize, size); // 当前批次限制
int i = 1;
// 3. 遍历数据集合
for (E element : list) {
// 执行具体的插入逻辑(通过 consumer 定义)
consumer.accept(sqlSession, element);
// 达到当前批次的限制时,flush 数据并更新批次计数
if (i == idxLimit) {
sqlSession.flushStatements(); // 刷新批量操作到数据库
idxLimit = Math.min(idxLimit + batchSize, size); // 更新下一个批次的限制
}
i++;
}
});
}
这段代码乍一看不复杂,但隐藏的细节非常有趣!我们一步步剖析:
- 批次大小校验
java 代码解读复制代码Assert.isFalse(batchSize < 1, "batchSize must not be less than one");
首先,它会检查 batchSize 是否有效,确保不能小于 1。
- 如果你传入 batchSize = 0,saveBatch 就直接让你“扑街”——报错毫不客气。
- 这是为了保证最基本的逻辑正确性:每个批次至少要插一条数据,不然批量插入还有啥意义?
- 集合为空的优化处理
java 代码解读复制代码return !CollectionUtils.isEmpty(list) && executeBatch(...);
如果要插入的数据集合是空的,saveBatch 也会直接短路,返回 false。
- 这是一个很实用的优化:空集合没必要再浪费资源走后续逻辑。
- 实战场景中,这种处理可以避免你“辛辛苦苦遍历到最后发现啥都没干”的尴尬。
- 数据分批核心逻辑
java 代码解读复制代码int idxLimit = Math.min(batchSize, size);
int i = 1;
for (E element : list) {
consumer.accept(sqlSession, element); // 执行插入逻辑
if (i == idxLimit) {
sqlSession.flushStatements(); // 刷新当前批次到数据库
idxLimit = Math.min(idxLimit + batchSize, size); // 更新批次限制
}
i++;
}
这段代码可以说是 saveBatch 的核心了!它的执行过程可以用“快递装箱”来打比方:
- 分批装箱:
- 它按照 batchSize(批次大小)把数据分成一批一批的“快递箱”。
- 每次最多装 batchSize 条数据,不超过总数据量 size。
- 送快递(flushStatements):
- 每装满一个箱子,就通过 flushStatements() 把这批数据送到数据库,类似于“快递员来收件”。
- flushStatements 的本质就是批量提交,把之前 addBatch() 的操作执行到数据库。
- 更新下一批次:
- 装完一箱后,计算下一批次的数据范围,并继续“装箱”。
- 插入逻辑的自定义(consumer)
java代码解读复制代码consumer.accept(sqlSession, element);
这里的 consumer 是一个自定义的逻辑,定义了“每一条数据的插入操作”。你可以理解为,这是 saveBatch 的可扩展部分。 通常情况下,consumer 会调用 MyBatis 的 insert 方法,把数据加入 addBatch 列表。比如:
java 代码解读复制代码(sqlSession, element) -> sqlSession.insert("namespace.insert", element);
这让 saveBatch 变得非常灵活——它本身不关心具体的 SQL,而是把实际的插入逻辑交给用户定义。
学习完saveBatch的源码,我们了解了 MyBatis-Plus 的批量的具体实现。解决了我们的一部分疑问,但是,还有一个比较大的问题并没有解决,那就是,在刻板映像中,我们还是会觉得拼接为批量的一条 sql 才是批量插入的完美解决方案,为什么 MyBatis 没支持呢?
insertBatchSomeColumn
其实早在 2018 年,MyBatis-Plus 的“江湖大佬”们就已经另辟蹊径,推出了一个真正意义上可以拼接 SQL 完成批量插入的方法——insertBatchSomeColumn。
这个方法的核心思路是:通过动态拼接 SQL,生成一条包含多条数据的 INSERT 语句。和我们之前分析的 saveBatch 不同,insertBatchSomeColumn 是一个真正符合“批量插入”直觉的操作。
这个方法并不是MyBatis-Plus默认的一个方法,我们需要在 idea 里全局搜索,或者进入源码中直接寻找,在package com.baomidou.mybatisplus.extension.injector.methods;包中,我们可以找到他;而他的实现也相对比较简单,我们能看到他的核心逻辑是拼接 Sql生成一个MappedStatement:
java 代码解读复制代码@Override
public MappedStatement injectMappedStatement(Class mapperClass, Class modelClass, TableInfo tableInfo) {
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
SqlMethod sqlMethod = SqlMethod.INSERT_ONE;
List fieldList = tableInfo.getFieldList();
String insertSqlColumn = tableInfo.getKeyInsertSqlColumn(true, null, false) +
this.filterTableFieldInfo(fieldList, predicate, TableFieldInfo::getInsertSqlColumn, EMPTY);
String columnScript = LEFT_BRACKET + insertSqlColumn.substring(0, insertSqlColumn.length() - 1) + RIGHT_BRACKET;
String insertSqlProperty = tableInfo.getKeyInsertSqlProperty(true, ENTITY_DOT, false) +
this.filterTableFieldInfo(fieldList, predicate, i -> i.getInsertSqlProperty(ENTITY_DOT), EMPTY);
insertSqlProperty = LEFT_BRACKET + insertSqlProperty.substring(0, insertSqlProperty.length() - 1) + RIGHT_BRACKET;
String valuesScript = SqlScriptUtils.convertForeach(insertSqlProperty, "list", null, ENTITY, COMMA);
String keyProperty = null;
String keyColumn = null;
// 表包含主键处理逻辑,如果不包含主键当普通字段处理
if (tableInfo.havePK()) {
if (tableInfo.getIdType() == IdType.AUTO) {
/* 自增主键 */
keyGenerator = Jdbc3KeyGenerator.INSTANCE;
keyProperty = tableInfo.getKeyProperty();
// 去除转义符
keyColumn = SqlInjectionUtils.removeEscapeCharacter(tableInfo.getKeyColumn());
} else {
if (null != tableInfo.getKeySequence()) {
keyGenerator = TableInfoHelper.genKeyGenerator(this.methodName, tableInfo, builderAssistant);
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
}
}
}
String sql = String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);
SqlSource sqlSource = super.createSqlSource(configuration, sql, modelClass);
return this.addInsertMappedStatement(mapperClass, modelClass, methodName, sqlSource, keyGenerator, keyProperty, keyColumn);
}
在 MyBatis-Plus 的世界里,injectMappedStatement 是一个超级工具,它的使命就是动态生成 SQL 映射,让我们写少量代码甚至不写代码,就能轻松实现复杂的数据库操作。
我们来剖析下在这个类中injectMappedStatement的具体实现。
- 准备工具与原材料
java 代码解读复制代码KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE; // 默认无主键生成器
SqlMethod sqlMethod = SqlMethod.INSERT_ONE; // 插入一条数据的方法
List fieldList = tableInfo.getFieldList(); // 获取表的字段信息
这几行代码的作用就像准备生产工具和原材料:
- keyGenerator:用来控制主键生成逻辑,默认情况下没有主键生成器。
- sqlMethod:定义了操作类型,这里是“插入一条数据”。
- fieldList:从 TableInfo(表信息)中获取所有字段,后面会用到它来动态生成 SQL。
- 拼接 SQL 的“SELECT 模板”
java 代码解读复制代码String insertSqlColumn = tableInfo.getKeyInsertSqlColumn(true, null, false) +
this.filterTableFieldInfo(fieldList, predicate, TableFieldInfo::getInsertSqlColumn, EMPTY);
String columnScript = LEFT_BRACKET + insertSqlColumn.substring(0, insertSqlColumn.length() - 1) + RIGHT_BRACKET;
这里是“拼 SQL 模板”的关键步骤:
- tableInfo.getKeyInsertSqlColumn:获取主键的 SQL 字段。
- 比如:id 是主键,它会返回 "id,"。
- filterTableFieldInfo:根据 predicate(过滤条件)过滤字段,并将每个字段拼成 SQL。
- 比如字段有 name 和 age,它会生成 "name, age,"。
- columnScript:拼接成括号包裹的完整字段列表。
- 输出结果:(id, name, age)
这部分就像是为插入操作画了一张“插槽模板”:这些字段告诉数据库“我要插入这些东西”。
- 拼接 SQL 的“VALUES 模板”
java 代码解读复制代码String insertSqlProperty = tableInfo.getKeyInsertSqlProperty(true, ENTITY_DOT, false) +
this.filterTableFieldInfo(fieldList, predicate, i -> i.getInsertSqlProperty(ENTITY_DOT), EMPTY);
insertSqlProperty = LEFT_BRACKET + insertSqlProperty.substring(0, insertSqlProperty.length() - 1) + RIGHT_BRACKET;
String valuesScript = SqlScriptUtils.convertForeach(insertSqlProperty, "list", null, ENTITY, COMMA);
这部分的作用是生成插入数据对应的“占位符”:
- tableInfo.getKeyInsertSqlProperty:获取主键对应的属性占位符。
- 比如主键是 id,对应的占位符是 #{id}。
- filterTableFieldInfo:和字段列表一样,把每个字段的占位符都拼接起来。
- 比如字段 name 和 age,会生成:#{name}, #{age}。
- valuesScript:通过 foreach 把占位符应用到多条记录上。 输出结果:
css 代码解读复制代码(#{list[0].id}, #{list[0].name}, #{list[0].age}),
(#{list[1].id}, #{list[1].name}, #{list[1].age}),
...
这就像给“插槽模板”填充了数据,让每一条记录有对应的占位符。
- 主键生成器的特殊处理
java 代码解读复制代码if (tableInfo.havePK()) {
if (tableInfo.getIdType() == IdType.AUTO) {
keyGenerator = Jdbc3KeyGenerator.INSTANCE; // 自增主键
keyProperty = tableInfo.getKeyProperty();
keyColumn = SqlInjectionUtils.removeEscapeCharacter(tableInfo.getKeyColumn());
} else if (null != tableInfo.getKeySequence()) {
keyGenerator = TableInfoHelper.genKeyGenerator(this.methodName, tableInfo, builderAssistant);
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
}
}
这里是主键生成逻辑的处理:
- 自动递增主键:
- 如果主键是 AUTO_INCREMENT,用 Jdbc3KeyGenerator 自动生成主键。
- 手动指定主键:
- 如果主键使用了序列(如 Oracle 的 sequence),就会用序列生成器来生成主键。
主键的生成逻辑被封装在这里,让插入操作可以智能处理有无主键的情况。
- 生成最终 SQL 脚本
java 代码解读复制代码String sql = String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);
SqlSource sqlSource = super.createSqlSource(configuration, sql, modelClass);
这一部分是重头戏,把前面拼接的“字段”和“数据”模板组装成完整的 SQL. 最终生成的 SQL:
sql 代码解读复制代码INSERT INTO user_table (id, name, age)
VALUES
(#{list[0].id}, #{list[0].name}, #{list[0].age}),
(#{list[1].id}, #{list[1].name}, #{list[1].age}),
...
- 返回最终 MappedStatement
java 代码解读复制代码return this.addInsertMappedStatement(mapperClass, modelClass, methodName, sqlSource, keyGenerator, keyProperty, keyColumn);
这一步将生成的 SQL 包装成 MyBatis 的 MappedStatement,并交给框架去管理和执行。
那新的疑问产生了,既然有这个方法,且自从 2018年就有了,为什么MyBatis-Plus 里并没有默认使用这个方法呢,我们继续探究。
insertBatchSomeColumn如何使用
为什么一个 ORM框架不默认支持一个我们直觉上觉得应该是更快的实现方法呢,问题的要点还是在快,那insertBatchSomeColumn究竟快不快,我们还是在同样的场景在,将 saveBatch 切换为我们的insertBatchSomeColumn。
因为 MyBatis-Plus 默认并没有直接支持这个方法(需要自己扩展)。接下来,我们将详细介绍如何在项目中正确引入这个“批量插入的快刀”。
第一步:创建自定义 SQL 注入器
MyBatis-Plus 支持通过扩展 DefaultSqlInjector 来添加自定义 SQL 方法,比如 insertBatchSomeColumn。我们需要新建一个 MySqlInjector 类。
java 代码解读复制代码public class MySqlInjector extends DefaultSqlInjector {
@Override
public List getMethodList(Configuration configuration, Class mapperClass, TableInfo tableInfo) {
// 从全局配置中获取数据库配置
GlobalConfig.DbConfig dbConfig = GlobalConfigUtils.getDbConfig(configuration);
// 构建基础方法列表
Stream.Builder builder = Stream.builder()
.add(new Insert(dbConfig.isInsertIgnoreAutoIncrementColumn())) // 普通插入
.add(new Delete()) // 删除
.add(new Update()) // 更新
.add(new SelectCount()) // 查询总数
.add(new SelectMaps()) // 查询 Map 集合
.add(new SelectObjs()) // 查询单个字段集合
.add(new SelectList()); // 查询列表
// 如果表有主键,添加 ById 系列方法
if (tableInfo.havePK()) {
builder.add(new DeleteById())
.add(new DeleteByIds())
.add(new UpdateById())
.add(new SelectById())
.add(new SelectByIds());
} else {
logger.warn(String.format("%s ,Not found @TableId annotation, Cannot use Mybatis-Plus 'xxById' Method.",
tableInfo.getEntityType()));
}
// **重点:添加 `insertBatchSomeColumn` 方法**
// 这里会自动跳过标记为 `FieldFill.UPDATE` 的字段,确保不会插入更新字段
builder.add(new InsertBatchSomeColumn(column -> column.getFieldFill() != FieldFill.UPDATE));
return builder.build().collect(Collectors.toList());
}
}
第二步:配置注入器到 MyBatis-Plus
在项目的 MyBatis-Plus 配置类中,注册我们刚刚创建的 MySqlInjector。
java 代码解读复制代码@Configuration
public class MybatisPlusConfig {
/**
* 配置分页插件(如果有分页需求)
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); // MySQL 分页
return interceptor;
}
/**
* 注册自定义的 SQL 注入器
*/
@Bean
public MySqlInjector mySqlInjector() {
return new MySqlInjector();
}
}
第三步:在 Mapper 接口中添加 insertBatchSomeColumn 方法
MyBatis-Plus 的扩展方法需要你在 Mapper 接口中手动声明,insertBatchSomeColumn 也不例外。
java 代码解读复制代码@Mapper
public interface UserMapper extends BaseMapper {
/**
* 批量插入(使用 `insertBatchSomeColumn`)
*
* @param list 数据集合
* @return 插入条数
*/
int insertBatchSomeColumn(@Param("list") List list) ;
}
第四步:在 Service 中调用 insertBatchSomeColumn
有了扩展的 Mapper 方法,就可以在业务逻辑中直接调用了!和普通的批量插入方法一样,insertBatchSomeColumn 支持直接传入数据列表。
java 代码解读复制代码@Resource
private ImUserDataMapper imUserDataMapper;
/**
* 批量插入用户数据
*
* @param userList 用户数据列表
*/
public void batchInsertUsers(List userList) {
imUserDataMapper.insertBatchSomeColumn(userList);
}
java 代码解读复制代码List> tasks = new ArrayList<>();
for (List batch : userDataBatches) {
tasks.add(() -> {
List imUserDataList = batch.stream()
.map(data -> ImUserAdapter.buildImUserData(data, appId))
.collect(Collectors.toList());
try {
// 批量插入
imUserDataDao.batchInsertUsers(imUserDataList);
imUserDataList.forEach(user -> successId.add(user.getUserId()));
} catch (Exception e) {
log.error("批量插入失败: {}", e.getMessage(), e);
imUserDataList.forEach(user -> failedId.add(user.getUserId()));
}
return null;
});
}
完成以上步骤之后,我们来测试下insertBatchSomeColumn效果了。结果几乎是可想而知了,这里我就不放图了(偷个懒)20 条数据的插入和 saveBatch 没有区别甚至小胜一筹!
那就更奇怪了,为什么明明性能差不多,为什么不用呢?其实我们可以从insertBatchSomeColumn这个类的注释里发现一些端倪。
 这些注释简直堪比“开发者的自我揭发”。
这些注释简直堪比“开发者的自我揭发”。
“不同的数据库支持度不一样!!!”这就像一个厨师告诉你:“这道菜在西安吃肯定香,但我只在西安做过,别拿去别的地方埋汰我!”
也就是说insertBatchSomeColumn 只在 MySQL 下测试过,其他数据库你用得好不好,纯靠天意。MySQL 支持多行 VALUES 插入的优化非常好,所以这个方法在 MySQL 中表现很优秀。但如果换成 Oracle、PostgreSQL 甚至 SQLite,性能可能会扑街。
“如果你使用自增有报错或主键值无法回写到 entity, 就不要跑来问为什么了, 因为我也不知道!!!”这句话我理解为“功能能用,但出了问题你就自认倒霉吧。”
看起来吧,其实到了这里,我们几乎就已经能明白,为什么 MyBatis-Plus 的批量没有选用拼接 sql 的这种方式了。但是知道了为什么不用但我还是想知道他们在效率上的优劣。
决战紫荆之巅
我们决定用实验来验证——虽然insertBatchSomeColumn看起来有点问题,但是理论上他应该是更快的,既然 insertBatchSomeColumn 看上去这么“香”,那它在实际场景中到底表现如何?问题的要点还是在“快”,我们来看看它到底“快不快”。
实验场景
- 表结构:和之前 saveBatch 的实验一样,用一个简单的用户表 user_table。
- 数据量:1000 条、10,000 条、100,000 条。
- 测试方法:
- 用 saveBatch 插入数据,记录耗时。
- 切换为 insertBatchSomeColumn 插入数据,记录耗时。
- 比较两者的性能。
这部分代码就比较简单了,简单贴一下:
java 代码解读复制代码@SpringBootTest
public class InsertPerformanceTest {
private static final String LOG_FILE_PATH = "performance-test.log";
private static final Logger log = LoggerFactory.getLogger(InsertPerformanceTest.class);
@Resource
private ImUserDataMapper imUserDataMapper;
private static final int[] DATA_SIZES = {100, 1000, 10000,100000}; // 不同数据量
@Test
public void testInsertPerformance() {
for (int size : DATA_SIZES) {
List testData = generateTestData(size);
logToFileAndConsole("=== 测试开始: 数据量 " + size + " ===");
// 测试逐条插入
// measureExecutionTime("逐条插入", () -> insertWithForLoop(testData));
// 测试批量插入(自定义 SQL)
measureExecutionTime("批量插入", () -> insertWithBatch(testData));
// 测试 InsertBatchSomeColumn
measureExecutionTime("InsertBatchSomeColumn 插入", () -> insertWithInsertBatchSomeColumn(testData));
logToFileAndConsole("=== 测试结束: 数据量 " + size + " ===");
}
}
private void measureExecutionTime(String operationName, Runnable operation) {
long start = System.currentTimeMillis();
try {
operation.run();
} catch (Exception e) {
logToFileAndConsole(operationName + " 失败: " + e.getMessage());
}
long end = System.currentTimeMillis();
logToFileAndConsole(operationName + " 耗时: " + (end - start) + " ms");
}
// 逐条插入
private void insertWithForLoop(List data) {
for (ImUserData user : data) {
imUserDataMapper.insert(user);
}
}
// 逐条插入
private void insertWithBatch(List data) {
imUserDataMapper.insert(data);
}
// MyBatis-Plus 的 InsertBatchSomeColumn
private void insertWithInsertBatchSomeColumn(List data) {
imUserDataMapper.insertBatchSomeColumn(data);
}
// 生成测试数据
private List generateTestData(int size) {
List testData = new ArrayList<>();
for (int i = 0; i < size; i++) {
ImUserData user = new ImUserData();
user.setUserId(IdGenerator.generate(1001));
user.setAppId(1001);
user.setNickName("测试用户" + i);
user.setPassword("password" + i);
user.setPhoto("https://example.com/photo" + i);
user.setEmail("user" + i + "@example.com");
user.setPhone("123456789" + i);
user.setUserSex(1);
user.setBirthDay("1990-01-01");
user.setLocation("测试城市");
user.setSelfSignature("测试签名");
user.setFriendAllowType(1);
user.setForbiddenFlag(0);
user.setDisableAddFriend(0);
user.setUserType(1);
user.setDelFlag(0);
testData.add(user);
}
return testData;
}
private void logToFileAndConsole(String message) {
System.out.println(message); // 打印到控制台
try (BufferedWriter writer = new BufferedWriter(new FileWriter(LOG_FILE_PATH, true))) {
writer.write(message);
writer.newLine();
} catch (IOException e) {
System.err.println("日志写入失败: " + e.getMessage());
}
}
}
重要的是测试的结果也是很 amazing:
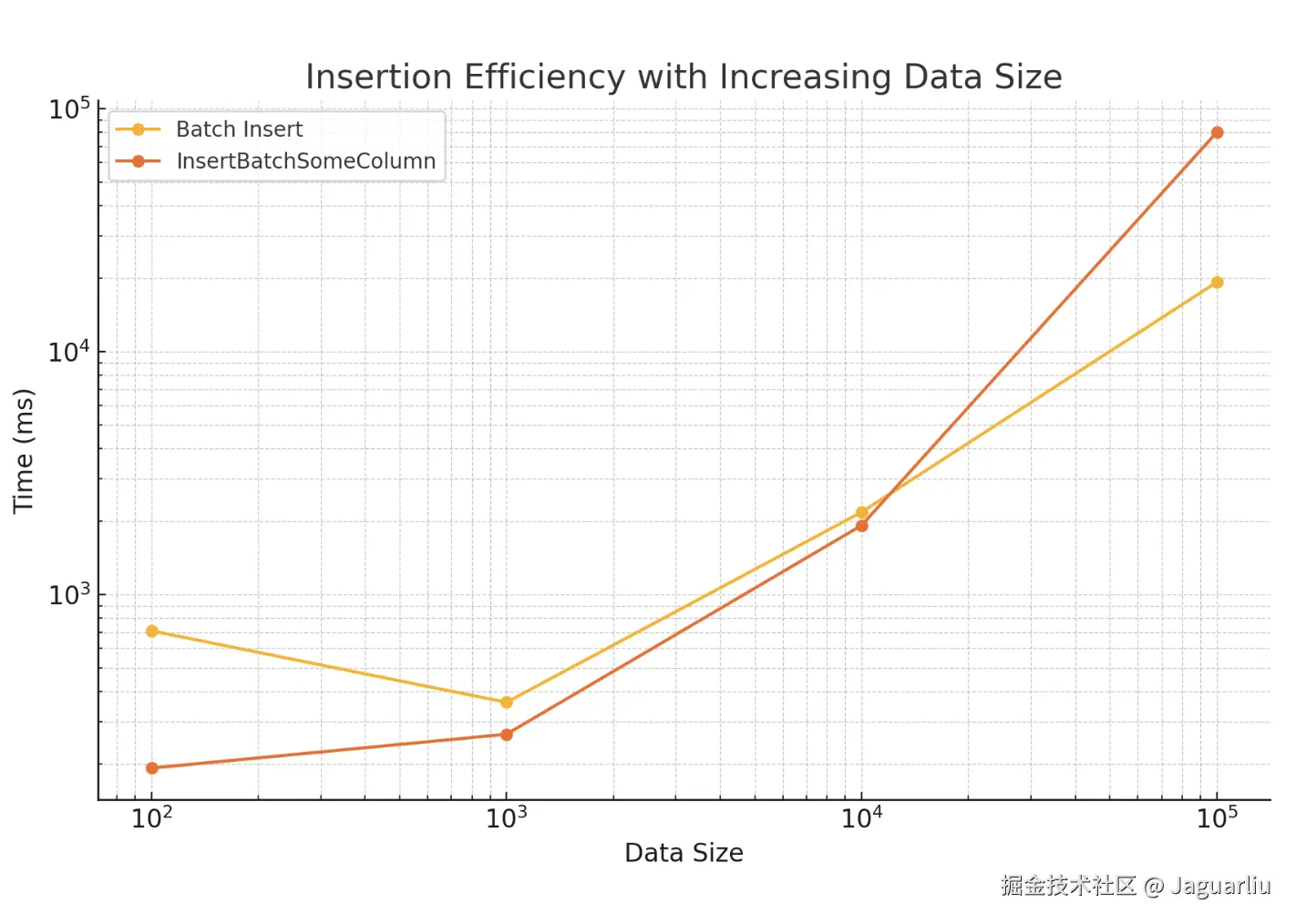 从图上可以看到,其实数据量不大的时候,批量提交和拼接一条 sql 的效率并不是有很大差异,但是当数据量巨大的时候,拼接 sql 的效率居然明显下降了,这就更难怪MyBatis-Plus 不选用他啦。
从图上可以看到,其实数据量不大的时候,批量提交和拼接一条 sql 的效率并不是有很大差异,但是当数据量巨大的时候,拼接 sql 的效率居然明显下降了,这就更难怪MyBatis-Plus 不选用他啦。
江湖不是打打杀杀
朋友,这就是江湖的复杂之处。当我们看着 insertBatchSomeColumn 的拼接 SQL,心里已经开始沸腾:“这不就是我想要的批量插入吗?用一条 SQL 搞定一切,岂不是吊打 saveBatch?”
可是,江湖上有句老话:“想当然的快,不一定是真正的快。” 从设计的角度,MyBatis-Plus 没有默认用 insertBatchSomeColumn 是有原因的。简单总结一下,主要有以下几个坑:
1. 场景局限性:数据量太大,SQL 太长
insertBatchSomeColumn 最大的特点是用一条 SQL 插入多行数据。但是,这种方式有一个致命的短板:数据量太大时,SQL 太长,直接爆掉。
-
问题一:SQL 长度限制
- 大部分数据库对 SQL 语句的长度有限制(比如 MySQL 默认是 4MB)。
- 如果你用 insertBatchSomeColumn 插入 10 万条数据,这条 SQL 很可能直接超出限制,报错了事。
-
问题二:解析压力
- SQL 语句越长,数据库解析 SQL 的时间也越长。
- 如果你拼了一个超级长的 VALUES,即使没有超过限制,数据库的解析过程也可能拖慢插入效率。
-
对比saveBatch:
- 它一次只发送一小批数据到数据库(比如 1000 条),SQL 很短,既不会超限,也不会给数据库解析带来太大压力。
2. 适配性问题:不同数据库的行为差异
ORM 框架最重要的特点是 “通用性”,它得让你的代码在 MySQL、PostgreSQL、Oracle 这些数据库上都跑得动。但问题来了,不同数据库对批量插入的支持并不一致。
-
MySQL 的快乐,在 MySQL 中,insertBatchSomeColumn 是天然适配的。VALUES 部分可以支持多个记录,性能也很好。
-
Oracle 并不直接支持类似 MySQL 的多行插入语法。虽然可以通过
INSERT ALL或UNION ALL来模拟多行插入,但这些方法在语法上较为繁琐,且性能可能不如 MySQL 的原生支持高效。尤其是UNION ALL的方式,在处理大量数据时可能会导致性能下降。(Oracle也提供了 批量绑定(Bulk Binding) :在 PL/SQL 中使用FORALL语句的方式,但是相较于原生支持复杂度还是较高)。 -
PostgreSQL 的问题,PostgreSQL 虽然支持多行 VALUES,但批量插入的性能未必比传统的逐条插入高,具体表现还取决于场景。
-
对比saveBatch
- saveBatch 是基于 JDBC 的 addBatch 和 executeBatch 实现的,JDBC 是数据库驱动的统一接口,各种数据库都支持,兼容性更好。
3. 灵活性:字段动态控制
insertBatchSomeColumn 的字段是固定的,它会根据 TableInfo 中定义的字段来拼接 SQL。如果你的某条记录需要动态处理某些字段,比如:
- 某些字段需要特定条件下赋值。
- 某些字段需要根据数据库默认值处理。
这时候,insertBatchSomeColumn 就显得“呆板”了。
对比saveBatch:saveBatch 的每条记录是独立的,可以动态调整每条记录的字段内容,更灵活。
总结:批量插入的江湖哲学
批量插入看似是开发中的小事,但其实它隐藏着许多复杂性。通过对 MyBatis-Plus 提供的两种插入方式(saveBatch 和 insertBatchSomeColumn)的深度探讨,我们可以得出以下关键结论:
- saveBatch:稳健的“江湖中人”
saveBatch 是 MyBatis-Plus 的默认实现,它基于 JDBC 的批处理能力,具有稳定性强、兼容性广、实现简单的特点。无论你的数据库是 MySQL、Oracle,还是 PostgreSQL,saveBatch 都能满足大多数场景的需求。虽然它在性能上可能不如理想中的批量插入快,但它能在数据量大、逻辑复杂的情况下稳稳地完成任务。
适合的场景:
- 数据量较大(比如超过 10 万条)。
- 表结构复杂,字段插入需要动态控制。
- 需要在多种数据库之间切换,追求通用性。
- insertBatchSomeColumn:锋利的“武林奇兵”
insertBatchSomeColumn 则是为高性能场景量身定制的“快刀”。它通过动态拼接 SQL,将多条数据用一条 SQL 插入数据库,极大地提升了插入效率。然而,它的优势是建立在特定场景的基础上,比如只支持 MySQL、无法很好处理自增主键、需要开发者精心配置字段等。
适合的场景:
- 数据库是 MySQL,且对多行 VALUES 优化非常好。
- 数据量适中(几千到几万条,不超过 SQL 长度限制)。
- 表结构简单,字段固定,不依赖数据库默认值。
- 没有“万能的武功”,只有“适配的选择”
MyBatis-Plus 的设计哲学并不是追求极致的性能,而是追求兼容性和易用性,这也是为什么 saveBatch 是默认实现而非 insertBatchSomeColumn。但对于极端性能需求的场景,insertBatchSomeColumn 无疑是一个值得尝试的选择。
江湖感言:快与稳,选你所需
在技术的江湖中,“快”与“稳”总是很难两全。我们希望用 insertBatchSomeColumn 的快刀斩乱麻,但也要记得,这把刀可能只适用于某些特定的“江湖环境”。而 saveBatch 则是那个你永远可以依靠的“老朋友”,即使它不够快,但它足够稳。
最终的选择权,永远掌握在你的手中。无论你选择哪条路,记得:
- 理解工具的优劣,选择适合场景的实现。
- 在实验中找到平衡,优化性能的同时确保稳定性。
- 批量插入只是项目的一部分,别让它拖累你更大的目标。
江湖再见,愿你批量插入的道路畅通无阻!
评论记录:
回复评论: