
Feign的性能优化
在微服务架构中,服务之间的通信是系统高效运行的核心环节,而 Feign 作为一种声明式的 HTTP 客户端,为开发者提供了简洁优雅的服务调用方式。然而,随着系统规模的增长和流量的增加,Feign 的性能问题可能会逐渐显现,例如高延迟、连接资源耗尽、过多的序列化开销等。这些问题不仅会降低系统的整体响应速度,还可能导致服务的不可用甚至雪崩效应。

使用连接池优化 HTTP 客户端
在 Feign 默认配置下,通常使用 HttpURLConnection 作为底层 HTTP 客户端。这种实现简单直接,但并不高效,尤其是在高并发场景下,每次请求都会创建新的连接,而连接的创建和销毁是非常昂贵的操作,可能导致资源浪费、延迟增加,甚至请求失败。
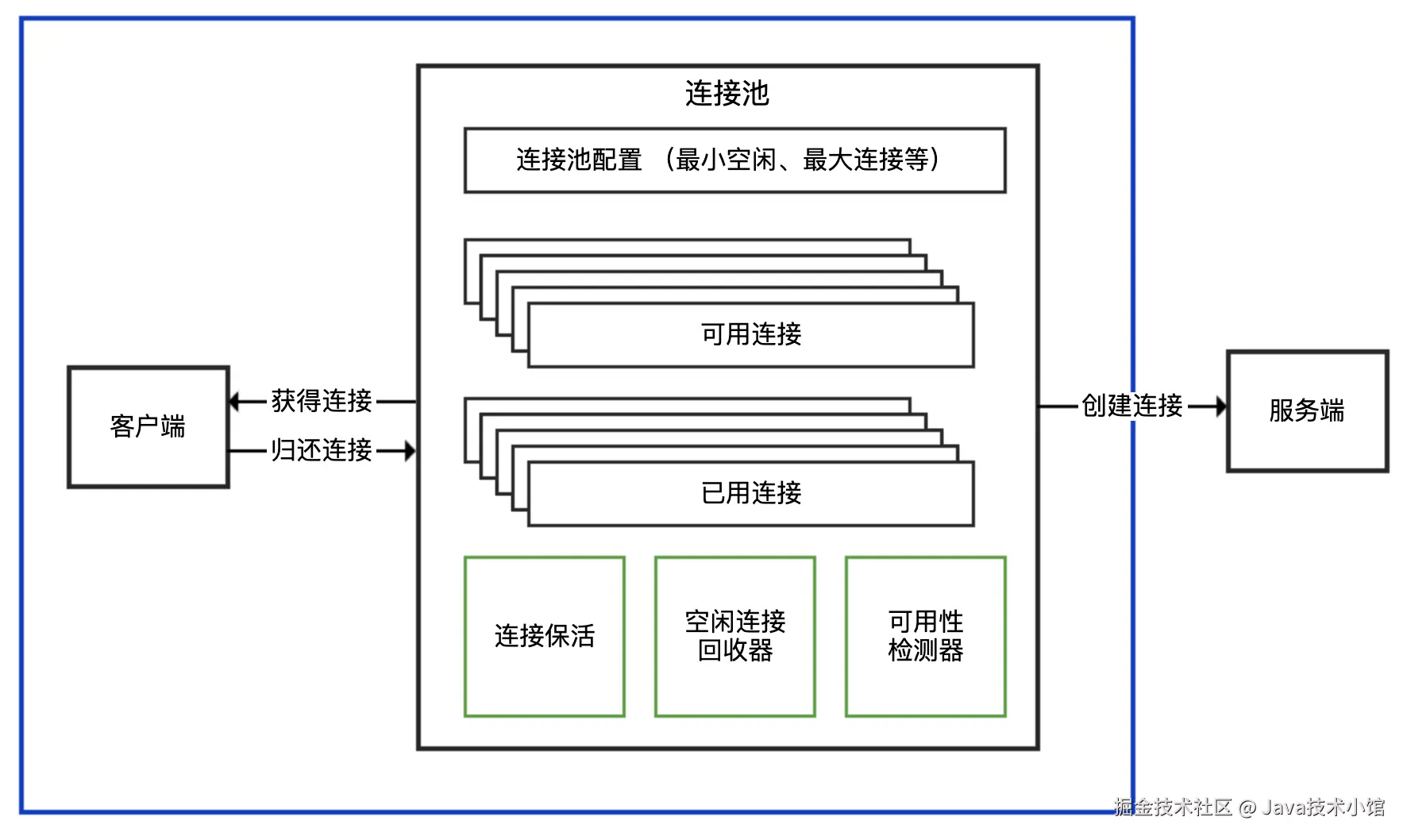
连接池的作用
连接池的核心思想是复用已经创建的连接来处理多个 HTTP 请求,从而减少连接的创建和销毁开销,优化性能。具体作用包括:
- 减少资源开销:连接池通过复用已有的连接,减少了频繁创建和销毁连接所需的 CPU 和内存消耗。
- 降低延迟:复用连接可以消除建立 TCP 连接的三次握手过程,大幅降低请求的响应时间。
- 提升吞吐量:通过管理连接的并发使用,可以支持更高的请求并发度,避免资源被耗尽。
替换 Feign 的默认客户端
默认的 HttpURLConnection 不支持连接池管理,因此需要将其替换为更高效的 HTTP 客户端,如 Apache HttpClient 或 OkHttp。
1. 使用 Apache HttpClient
Apache HttpClient 是一个功能强大的 HTTP 客户端库,支持连接池管理和多种优化配置。
less 代码解读复制代码@Bean
public ApacheHttpClient feignClient() {
return new ApacheHttpClient(HttpClients.custom()
.setMaxConnTotal(200) // 设置最大连接数
.setMaxConnPerRoute(50) // 设置每个路由的最大连接数
.setDefaultRequestConfig(RequestConfig.custom()
.setConnectTimeout(5000) // 设置连接超时时间
.setSocketTimeout(5000) // 设置读超时时间
.build())
.build());
}
2. 使用 OkHttp
OkHttp 是另一个高效的 HTTP 客户端库,默认支持连接池并提供更轻量的实现。
scss 代码解读复制代码@Bean
public OkHttpClient okHttpClient() {
return new OkHttpClient.Builder()
.connectionPool(new ConnectionPool(50, 5, TimeUnit.MINUTES)) // 配置连接池大小与存活时间
.connectTimeout(5, TimeUnit.SECONDS) // 设置连接超时时间
.readTimeout(5, TimeUnit.SECONDS) // 设置读取超时时间
.build();
}
在使用 OkHttp 时,需要添加 Feign 的 OkHttp 适配器:
typescript 代码解读复制代码@Bean
public Feign.Builder feignBuilder(OkHttpClient okHttpClient) {
return Feign.builder().client(new feign.okhttp.OkHttpClient(okHttpClient));
}
连接池的关键配置
- 最大连接数(Max Connections)
定义连接池中允许的最大连接数。对于高并发场景,应该根据系统的吞吐量需求适当增大此值。 - 每个路由的最大连接数(Max Connections Per Route)
控制同一目标服务的最大连接数,以避免单个服务占用过多连接资源。 - 空闲连接的存活时间(Keep-Alive Time)
设置空闲连接在连接池中的存活时间,过短会导致频繁的连接关闭与创建,过长则可能浪费资源。 - 连接超时与读取超时
-
- 连接超时:控制连接建立的最大时间,防止因目标服务不可用导致的长时间阻塞。
- 读取超时:设置等待响应数据的最大时间,避免长时间的无效等待。
实际效果
通过连接池优化 HTTP 客户端,可以显著降低连接相关的开销,提高请求的吞吐量和系统的整体性能。以下是优化后的关键指标:
- 吞吐量:在并发请求数较高时,吞吐量可提升 2-5 倍,具体取决于配置和系统负载。
- 响应时间:相比未优化的连接,平均响应时间可减少 20%-50%。
- 资源占用:大幅降低系统的 CPU 和内存消耗。
注意事项
- 合理的连接池配置:需要根据系统实际流量和服务特性,进行连接数和超时的调优,避免过小或过大的配置。
- 监控和调整:使用工具(如 Micrometer 或 Prometheus)监控连接池的使用率,及时调整配置以适应动态流量需求。
- 连接池泄漏问题:确保连接正确释放,例如在出现异常时及时关闭连接,避免连接泄漏。
通过连接池优化 Feign 的 HTTP 客户端,不仅能提升单机的性能表现,还为整个微服务体系的高效运行提供了坚实的基础。
启用压缩传输
在微服务架构中,数据在服务之间的传输往往占用大量的带宽,尤其是在服务通信频繁且数据量大的场景中,传输效率会直接影响服务的响应时间和系统的吞吐能力。启用压缩传输是一种提升传输效率的重要手段,通过减少传输数据的大小,降低网络延迟和带宽使用,从而提升整体性能。

压缩传输的原理
压缩传输是指在服务端对数据进行压缩后再发送,客户端接收到压缩数据后进行解压。常用的 HTTP 压缩算法包括 GZIP、Deflate 和 Brotli。这些算法可以有效减少文本数据(如 JSON、XML)和部分二进制数据的体积,从而提高数据传输效率。
启用压缩传输的优点
- 减少传输体积:压缩可以大幅降低数据大小,一般可减少 50%-90%,具体取决于数据的内容和压缩算法。
- 降低网络延迟:数据量减少后,传输时间缩短,特别是在高延迟网络环境中效果更为明显。
- 节省带宽:对于需要跨网络或云环境的通信,减少流量成本尤为重要。
- 提高吞吐量:网络瓶颈得到缓解后,单个服务节点可以处理更多的并发请求。
在 Feign 中启用压缩传输
默认情况下,Feign 不启用压缩传输,因此需要手动配置。在启用压缩前,需确保客户端和服务端均支持压缩格式。
配置 Feign 的压缩传输
在 Feign 中,可以通过配置支持 GZIP 等压缩格式,以下是实现步骤:
- 启用压缩功能
使用 Spring Cloud Feign 时,可以在配置文件中直接启用 GZIP 压缩。
yaml 代码解读复制代码feign:
compression:
request:
enabled: true # 启用请求压缩
mime-types: text/xml,application/json,application/xml,text/plain
min-request-size: 2048 # 仅当请求体大于此值时才压缩
response:
enabled: true # 启用响应解压
mime-types:指定需要压缩的 MIME 类型,比如 JSON、XML 等常见类型。min-request-size:防止压缩小体积的数据导致额外开销。
- 配置压缩拦截器
如果使用自定义 Feign 客户端,需要显式添加压缩拦截器:
typescript 代码解读复制代码@Bean
public RequestInterceptor gzipRequestInterceptor() {
return requestTemplate -> requestTemplate.header("Accept-Encoding", "gzip");
}
3. 服务端配置
确保服务端也支持 GZIP 解压。以 Spring Boot 为例,可通过配置 application.properties:
ini 代码解读复制代码server.compression.enabled=true
server.compression.mime-types=application/json,application/xml,text/html,text/plain
server.compression.min-response-size=2048
压缩算法的选择
- GZIP
-
- 优点:广泛支持,压缩率高,对文本数据效果显著。
- 缺点:压缩速度较慢,占用一定的 CPU 资源。
- 适用场景:传输体积较大的 JSON 或 XML 数据。
- Brotli
-
- 优点:相比 GZIP,压缩比更高,解压速度更快。
- 缺点:支持度稍逊于 GZIP。
- 适用场景:需要极致压缩效率的应用。
- Deflate
-
- 优点:压缩速度快,占用资源低。
- 缺点:压缩率较 GZIP 略低。
- 适用场景:对压缩率要求不高但希望快速响应的场景。
注意事项
- 压缩和性能的权衡
压缩虽然可以减少传输体积,但会消耗一定的 CPU 资源。因此,建议为大数据量的传输启用压缩,而小数据量的传输则可避免压缩带来的开销。 - 避免对已经压缩的数据再次压缩
对于图片、视频、ZIP 文件等已压缩的数据,启用压缩可能无效甚至增加体积。因此,应根据 MIME 类型合理配置。 - 客户端和服务端的兼容性
客户端和服务端需协商支持的压缩算法,例如通过 HTTP 的Accept-Encoding和Content-Encoding头部。 - 监控和调优
配置压缩后,应通过日志和监控工具评估其对响应时间和资源消耗的影响,及时调整配置。
实际效果
启用压缩传输后,系统性能提升主要体现在以下方面:
- 减少带宽使用:适合低带宽、高延迟的网络环境,例如移动网络。
- 提升响应速度:特别是在大体积数据传输场景中,压缩后数据量减少,响应速度显著提高。
- 节省资源成本:对于依赖云服务的微服务系统,压缩传输可以显著降低流量费用。
通过启用压缩传输,Feign 客户端可以在高效利用网络资源的同时,保障服务通信的快速和稳定,是优化微服务性能的重要手段之一。
减少序列化与反序列化开销
在微服务通信中,序列化与反序列化的性能对系统的整体效率有直接影响。Feign 作为一个 HTTP 客户端,需要将对象序列化为请求体,发送到服务端后再进行反序列化。而不合理的序列化机制可能带来额外的性能开销,影响服务的响应时间和吞吐量。
序列化与反序列化的工作原理
- 序列化:将 Java 对象转化为字节流或其他传输格式(如 JSON、XML)以便传输。
- 反序列化:将收到的数据流解析为 Java 对象,以供应用程序使用。
虽然 JSON 和 XML 是 Feign 默认支持的序列化格式,但它们的性能开销较高,尤其是解析复杂数据结构时,可能成为性能瓶颈。
减少序列化与反序列化开销的策略
1. 选择高效的序列化协议
默认的 JSON 或 XML 序列化方式简单易用,但解析效率较低,可以考虑替换为更高效的序列化协议:
- Protocol Buffers (Protobuf) :由 Google 开发,序列化速度快、体积小,适合高性能场景。
- Apache Avro:支持动态模式和二进制序列化,适合大规模数据处理。
- MessagePack:类似 JSON 的二进制格式,兼顾人类可读性和高效性。
实现步骤:
- 在 Feign 客户端中配置支持高效序列化协议的编解码器:
typescript 代码解读复制代码@Bean
public Encoder feignEncoder() {
return new ProtobufEncoder(); // 使用 Protobuf 编码
}
@Bean
public Decoder feignDecoder() {
return new ProtobufDecoder(); // 使用 Protobuf 解码
}
2. 确保服务端也支持对应的序列化协议,以保证兼容性。
2. 减少序列化数据体积
序列化数据的体积直接影响传输效率和解析时间,减少数据体积可以显著降低开销:
- 移除冗余字段:只传输必要的数据,避免无意义的字段。
- 压缩数据:结合压缩传输功能,对大体积数据使用 GZIP 或 Brotli 压缩。
- 优化数据结构:使用简单、扁平化的结构代替深层嵌套的复杂对象。
例如,将深度嵌套的 JSON 对象转换为扁平化的形式可以减少解析时间和内存占用。
3. 使用高性能的序列化库
在使用 JSON 的场景中,不同的序列化库性能差异显著:
- Jackson:Spring 默认使用的 JSON 序列化库,功能丰富但解析速度稍慢。
- Gson:轻量级 JSON 库,适合简单场景。
- Fastjson:解析速度快,适合高性能要求的场景,但存在潜在的安全问题。
- Kryo:支持二进制格式,性能优于 Jackson 和 Gson。
实现步骤:
- 在 Feign 中使用自定义的序列化工具:
typescript 代码解读复制代码@Bean
public Encoder feignEncoder() {
return new JacksonEncoder(); // 使用 Jackson
}
@Bean
public Decoder feignDecoder() {
return new JacksonDecoder();
}
4. 避免不必要的反序列化
在某些场景下,可以直接传输二进制数据,避免序列化和反序列化过程。例如:
- 文件传输:直接传输文件字节流,而不是将文件对象转换为 JSON 或 XML。
- 图像或音频数据:使用 Base64 编码会显著增加数据体积,应直接传输原始二进制数据。
通过使用 Feign 的 ByteArrayResource 或 InputStream 来处理二进制数据:
less 代码解读复制代码@RequestLine("POST /upload")
Response uploadFile(@RequestBody byte[] file);
5. 优化对象映射
当需要将复杂的对象进行序列化时,优化对象映射规则可以提高性能:
- 禁用无用特性:例如在 Jackson 中禁用
FAIL_ON_UNKNOWN_PROPERTIES。 - 预定义对象映射规则:使用注解(如
@JsonIgnore)控制序列化的字段,减少数据转换的开销。
ini 代码解读复制代码ObjectMapper mapper = new ObjectMapper();
mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
6. 使用缓存减少重复解析
对于频繁访问的相同数据,可以通过缓存减少序列化与反序列化的次数。例如,将反序列化后的对象缓存到内存中,而不是每次请求都重新解析。
scss 代码解读复制代码private final Cache cache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build();
调整超时设置
在分布式系统中,调用超时是影响服务稳定性和性能的一个重要因素。如果 Feign 客户端的超时设置不合理,可能会导致调用阻塞、系统资源耗尽、甚至雪崩效应。因此,合理调整 Feign 的超时设置是优化性能的重要手段之一。
Feign 中的超时设置概述
Feign 提供了两种关键的超时设置:
- 连接超时(Connect Timeout) :客户端建立与服务端的 TCP 连接所允许的最大时间。连接超时通常反映网络的可达性问题。
- 读取超时(Read Timeout) :客户端等待服务端返回响应的最大时间。读取超时通常涉及服务端的响应时间性能。
默认情况下,Feign 的超时设置可能过于宽松或者没有明确指定,这在高并发场景下容易导致资源占用过多或调用延迟积累。
调整超时设置的意义
- 快速失败:在网络异常或服务端不可用时,及时触发失败,释放资源,避免长时间的等待。
- 资源保护:减少线程占用时间,避免因大量调用阻塞导致系统资源枯竭。
- 提高系统吞吐量:通过合理的超时策略,可以避免单个请求拖累整体性能,提升服务的响应速度和并发能力。
如何调整 Feign 的超时设置
1. 在配置文件中设置超时
在 Spring Cloud 中,可以通过配置文件为 Feign 调整超时:
yaml 代码解读复制代码feign:
client:
config:
default:
connectTimeout: 5000 # 连接超时时间(毫秒)
readTimeout: 10000 # 读取超时时间(毫秒)
connectTimeout:设置连接建立的最大等待时间。readTimeout:设置从服务端读取响应的最大时间。
最佳实践:
- 对于连接超时(
connectTimeout),通常设置较短(如 1-5 秒),因为建立连接的过程应该是迅速的。 - 对于读取超时(
readTimeout),可以根据服务的响应时间性能适当放宽(如 3-10 秒)。
2. 动态调整超时
在某些场景下,服务的调用链可能复杂且动态变化,使用固定的超时值可能不足以应对实际需求。这时可以动态配置超时:
使用 Request.Options 动态传递超时设置:
typescript 代码解读复制代码@Bean
public Request.Options feignRequestOptions() {
return new Request.Options(5000, 10000); // 连接超时5秒,读取超时10秒
}
这种方式可以为特定的 Feign 客户端配置自定义的超时值。
3. 不同服务设置不同超时
如果系统中存在多种服务,服务响应时间差异较大,可以为不同服务设置不同的超时配置。例如:
yaml 代码解读复制代码feign:
client:
config:
serviceA:
connectTimeout: 3000
readTimeout: 5000
serviceB:
connectTimeout: 5000
readTimeout: 15000
这种方式可以为慢响应服务(如批量任务)提供更宽松的超时,同时为高并发服务提供更严格的限制。
4. 结合熔断器进行优化
超时设置与熔断器(如 Hystrix 或 Sentinel)密切相关,合理的超时值可以与熔断器策略配合使用:
- 超时后快速失败,避免耗尽线程资源。
- 熔断器提供降级服务,防止用户体验受损。
例如,设置超时时间短于熔断器的超时时间:
yaml 代码解读复制代码hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 15000 # 熔断器超时
feign:
client:
config:
default:
connectTimeout: 3000
readTimeout: 10000 # Feign 超时
5. 结合重试机制
在合理调整超时的基础上,可以结合 Feign 的重试机制,进一步增强调用的鲁棒性:
yaml 代码解读复制代码retryer:
period: 100
maxPeriod: 1000
maxAttempts: 3
period:重试的初始等待时间。maxPeriod:每次重试的最大等待时间。maxAttempts:最大重试次数。
通过重试机制,在短暂的网络抖动或瞬态故障时可以提高请求成功率。
注意事项
- 平衡超时值与业务需求:超时时间太短可能导致误判,影响系统可用性;过长则可能浪费资源或影响吞吐量。
- 监控和优化:通过监控工具(如 Prometheus、Zipkin)分析服务的响应时间分布,动态优化超时配置。
- 超时和重试的平衡:在使用重试机制时,超时值过长可能导致重试累积拖垮系统,需谨慎调整。
实际案例
场景 1:高并发服务
- 连接超时:500 毫秒
- 读取超时:1000 毫秒
- 配合熔断器快速降级,提升系统吞吐量。
场景 2:批处理服务
- 连接超时:2000 毫秒
- 读取超时:30000 毫秒
- 配合重试机制,适应长耗时任务。
通过合理调整 Feign 的超时设置,可以有效提高系统的响应效率和稳定性,在高并发、复杂调用链场景中尤为重要。
启用异步调用
在分布式系统中,传统的同步调用会阻塞线程,等待服务响应完成后才能继续执行,这种方式可能在高并发场景下造成性能瓶颈。而异步调用则可以通过非阻塞的方式处理请求,大幅提高资源利用率和系统吞吐量。Feign 提供了异步调用的能力,可以通过配置和编程模型优化性能。
异步调用的基本原理
Feign 的异步调用基于 Java CompletableFuture,通过非阻塞的方式处理 HTTP 请求。在异步模式下:
- 客户端线程发起调用后立即返回,不会阻塞等待响应。
- Feign 内部将请求封装为一个异步任务,并在后台完成调用。
- 响应结果通过回调(Callback)或
CompletableFuture的thenApply等方法处理。
这种方式能够充分利用系统资源,避免线程长时间阻塞,适合延迟较高或 I/O 密集型服务的调用场景。
异步调用的实现
启用 Feign 的异步调用,需要结合 Spring Cloud 和 Feign 的配置与实现。
1. 引入支持异步调用的依赖
需要确保项目中使用了 Feign 的异步 HTTP 客户端,例如 Apache HttpClient 或 OkHttp。在 pom.xml 中添加:
xml 代码解读复制代码<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
dependency>
<dependency>
<groupId>org.apache.httpcomponents.client5groupId>
<artifactId>httpclient5artifactId>
dependency>
2. 启用异步模式
在 Feign 接口中定义方法返回类型为 CompletableFuture:
kotlin 代码解读复制代码@FeignClient(name = "example-service")
public interface ExampleClient {
@GetMapping("/example")
CompletableFuture getExampleData();
}
此时,Feign 会将请求转换为异步调用。
3. 使用异步结果
调用方可以通过以下方式处理返回的 CompletableFuture:
- 直接获取结果:
ini 代码解读复制代码CompletableFuture future = exampleClient.getExampleData();
String result = future.get(); // 阻塞获取结果
- 使用回调处理:
kotlin 代码解读复制代码exampleClient.getExampleData()
.thenApply(response -> {
// 处理响应
System.out.println("Response: " + response);
return response;
})
.exceptionally(ex -> {
// 异常处理
ex.printStackTrace();
return "Error";
});
异步调用的优势
- 线程资源效率:避免线程长时间阻塞,提高线程利用率,适合高并发场景。
- 系统吞吐量提升:通过非阻塞模型,可以更快地处理请求,减少线程上下文切换的开销。
- 延迟优化:客户端可以并行处理多个任务,而无需等待单个任务完成。
异步调用的注意事项
- 回调地狱问题:复杂的异步逻辑可能导致嵌套过深的问题,需要通过
CompletableFuture的组合方法(如thenApply、thenCombine等)优化代码结构。 - 异常处理:异步调用过程中可能发生异常,需要通过
exceptionally或handle方法进行捕获和处理,避免未处理异常导致任务中断。 - 性能监控和调优:异步调用可能对客户端和服务端增加压力,尤其在高并发场景下,需要配合监控工具(如 Prometheus)跟踪系统性能指标,确保系统稳定性。
- 与其他框架的兼容性:如果服务端或调用链涉及其他同步框架,可能需要额外的封装和适配,确保异步调用的无缝衔接。
实际案例
场景:批量数据处理
假设需要调用多个微服务获取数据并汇总,异步调用可以显著减少总耗时:
ini 代码解读复制代码CompletableFuture serviceA = exampleClientA.getData();
CompletableFuture serviceB = exampleClientB.getData();
CompletableFuture result = serviceA.thenCombine(serviceB, (dataA, dataB) -> {
// 合并两个服务的结果
return dataA + " " + dataB;
});
result.thenAccept(System.out::println);
通过异步调用,多个服务可以并行处理,大幅提升效率。启用异步调用能够帮助开发者充分利用 Feign 的能力,尤其在高并发或延迟敏感场景中,是性能优化的重要策略之一。
减少请求的频率和数据量
在微服务系统中,频繁的请求和大数据量的传输可能导致网络带宽占用过高、服务性能下降甚至超时异常。通过减少请求的频率和传输数据量,可以有效降低系统开销,提升服务响应速度和稳定性。Feign 客户端的优化也应注重这一方面。
减少请求频率的策略
- 批量处理请求
-
- 原理:将多个小请求合并为一个大请求,通过一次调用完成多个操作,减少网络交互次数。
- 实现方式:
-
-
- 在服务端和客户端接口中设计批量操作方法。
- 例如,通过 RESTful API 的 POST 方法一次发送多个对象的数据。
-
less 代码解读复制代码@FeignClient(name = "batch-service")
public interface BatchServiceClient {
@PostMapping("/processBatch")
ResponseEntity processBatch(@RequestBody List dataList);
}
-
- 适用场景:批量数据上传、日志传输、文件处理等场景。
- 请求合并(Request Collapsing)
-
- 原理:对于短时间内发起的多个相同请求,将其合并为一个请求,从而降低请求频率。
- 实现方式:使用工具库(如 Hystrix 或 Resilience4j)支持的请求合并特性,通过合并机制将多次请求聚合处理。
- 优点:减少冗余的服务调用,特别适用于高并发读取场景。
- 使用缓存
-
- 原理:对于高频率、低变化的数据,通过本地缓存或分布式缓存(如 Redis)减少对服务的重复请求。
- 实现方式:
-
-
- 在客户端层面加入缓存机制,例如 Spring Cache。
- 在网关层增加缓存拦截器。
-
typescript 代码解读复制代码@Cacheable("userDetails")
public UserDetails getUserDetails(String userId) {
return userServiceClient.getUserDetails(userId);
}
-
- 适用场景:数据变化频率较低,且对实时性要求不高的场景。
减少数据量的策略
- 数据压缩
-
- 原理:对传输的数据进行压缩,减少网络传输的字节数。
- 实现方式:
-
-
- 在 HTTP 客户端启用压缩,例如在 Feign 中通过配置 GZIP 或 Deflate。
- 配置 Spring Boot 的
server.compression.enabled。
-
yaml 代码解读复制代码feign.compression.request.enabled: true
feign.compression.response.enabled: true
2. 数据筛选与裁剪
-
- 原理:根据实际需要,只传输必要的字段,避免传输冗余数据。
- 实现方式:
-
-
- 在服务端接口中设计数据裁剪功能,例如通过参数指定需要返回的字段。
- 使用轻量化的 DTO(数据传输对象)代替完整的实体类传输数据。
-
less 代码解读复制代码@FeignClient(name = "user-service")
public interface UserServiceClient {
@GetMapping("/user/{id}")
UserDTO getUserDetails(@PathVariable("id") String id);
}
3. 分页和分块传输
-
- 原理:对于大批量数据请求,通过分页(Pagination)或分块(Chunking)的方式分段获取,避免一次传输过大的数据。
- 实现方式:
-
-
- 使用分页参数设计 RESTful API。
- 客户端按需加载数据,并按页发起请求。
-
less 代码解读复制代码@FeignClient(name = "data-service")
public interface DataServiceClient {
@GetMapping("/data?page={page}&size={size}")
Page getPagedData(@RequestParam("page") int page, @RequestParam("size") int size);
}
-
- 适用场景:数据查询接口、大型列表展示、报表导出等场景。
- 选择合适的数据格式
-
- 原理:通过选择更高效的序列化方式,减少传输数据量。
- 实现方式:
-
-
- 优先使用高效的二进制协议(如 Protobuf、Avro)替代 JSON 或 XML。
- 配置 Feign 支持特定的序列化协议。
-
less 代码解读复制代码@FeignClient(name = "binary-service", configuration = ProtobufConfig.class)
public interface BinaryServiceClient {
@PostMapping("/processData")
BinaryResponse processBinaryData(@RequestBody BinaryRequest request);
}
注意事项
- 批量处理与延迟权衡:批量处理虽能减少请求频率,但可能会引入延迟,需根据实际场景权衡。
- 缓存一致性:使用缓存需注意与服务端数据的一致性,避免因缓存数据过期导致错误结果。
- 分页设计:分页过程中需要处理数据的新增或删除导致的页码漂移问题。
- 数据裁剪:裁剪数据字段时需确保不会遗漏关键信息,导致业务异常。
缓存机制
在分布式微服务系统中,缓存是一种关键的性能优化策略,能够显著提升请求响应速度、减少服务间调用次数以及降低系统压力。在 Feign 客户端中引入缓存机制,可以避免频繁地调用后端服务,从而优化整体性能和资源利用率。
缓存的基本概念
缓存是存储层中的中间层,专门用于临时存储高频访问的计算结果或数据副本,减少从原始数据源获取数据的频率。缓存通常分为以下两种类型:
- 本地缓存:存储在客户端或服务端的内存中,访问速度极快,但适合于单节点服务或不需要共享数据的场景。
- 分布式缓存:使用专门的分布式缓存系统(如 Redis、Memcached)实现数据共享和一致性,适合多节点和大规模分布式环境。
在 Feign 调用中,缓存可以缓解网络传输和后端服务的压力,提高系统的响应效率。
Feign 缓存的实现策略
- 本地缓存(Local Cache)
-
- 原理:在客户端内存中缓存 Feign 请求的结果,以减少重复请求的发生。
- 实现方式:
-
-
- 使用工具类(如
Guava Cache或Caffeine)实现本地缓存。 - 在 Feign 调用的返回结果上增加缓存逻辑。
- 使用工具类(如
-
less 代码解读复制代码@Component
public class LocalCacheService {
private final Cache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build();
public Object getFromCache(String key, Supplier
return cache.get(key, k -> fetchFunction.get());
}
}
@FeignClient(name = "user-service")
public interface UserServiceClient {
@GetMapping("/user/{id}")
User getUserById(@PathVariable("id") String id);
}
// 使用缓存包装调用
User user = localCacheService.getFromCache(userId, () -> userServiceClient.getUserById(userId));
-
- 优点:极低的访问延迟;实现简单。
- 缺点:缓存只对单节点生效,无法跨服务共享。
- 分布式缓存(Distributed Cache)
-
- 原理:将请求结果存储在分布式缓存系统中,以实现跨服务和跨节点的数据共享。
- 实现方式:
-
-
- 使用 Redis 或其他分布式缓存工具,结合 Feign 请求返回结果进行存储。
- 利用缓存工具的 TTL(Time-To-Live)机制,设置数据的有效期。
-
vbnet 代码解读复制代码@Service
public class DistributedCacheService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public Object getFromCache(String key, Supplier<Object> fetchFunction, long ttl, TimeUnit timeUnit) {
return redisTemplate.opsForValue().get(key, k -> {
Object value = fetchFunction.get();
redisTemplate.opsForValue().set(key, value, ttl, timeUnit);
return value;
});
}
}
@FeignClient(name = "order-service")
public interface OrderServiceClient {
@GetMapping("/order/{id}")
Order getOrderById(@PathVariable("id") String id);
}
// 使用分布式缓存包装调用
Order order = distributedCacheService.getFromCache(orderId, () -> orderServiceClient.getOrderById(orderId), 10, TimeUnit.MINUTES);
-
- 优点:支持多节点共享和高并发访问;支持数据持久化。
- 缺点:依赖外部缓存系统,需额外运维。
- HTTP 缓存
-
- 原理:通过 HTTP 协议的缓存头(如
Cache-Control、ETag)缓存服务端的响应结果。 - 实现方式:
- 原理:通过 HTTP 协议的缓存头(如
-
-
- 配置 Feign 使用 HTTP 缓存。
- 在后端服务中支持
ETag或Last-Modified头字段。
-
yaml 代码解读复制代码feign:
client:
config:
default:
connectTimeout: 5000
readTimeout: 5000
loggerLevel: full
followRedirects: true
-
- 优点:无需额外代码实现;遵循 HTTP 标准。
- 缺点:不灵活,缓存粒度受服务端控制。
- 结合 Spring Cache
-
- 原理:通过 Spring 提供的缓存抽象功能(
@Cacheable注解)为 Feign 方法提供透明缓存。 - 实现方式:
- 原理:通过 Spring 提供的缓存抽象功能(
-
-
- 使用 Spring Boot 的 Cache 配置与
@Cacheable注解。
- 使用 Spring Boot 的 Cache 配置与
-
less 代码解读复制代码@FeignClient(name = "product-service")
public interface ProductServiceClient {
@Cacheable("products")
@GetMapping("/product/{id}")
Product getProductById(@PathVariable("id") String id);
}
-
- 优点:与 Spring 框架深度集成,配置简单。
- 缺点:缓存实现依赖 Spring 环境。
缓存一致性与失效策略
- 缓存失效策略
-
- 配置缓存的 TTL,使得数据在一定时间后自动失效。
- 主动失效:通过事件监听(如服务更新通知)主动清理缓存。
- 基于版本号或时间戳的缓存更新策略。
- 数据一致性
-
- 最终一致性:允许缓存与服务端数据短时间不一致,适用于读取频率高但实时性要求低的场景。
- 强一致性:确保每次访问缓存时校验服务端数据,适用于交易类应用。
优化注意事项
- 缓存粒度:避免缓存过多无用数据,选择适当的缓存粒度。
- 缓存穿透:对空结果进行缓存,防止缓存层无命中时直接击穿后端服务。
- 热点缓存问题:高并发访问时,使用分布式锁或预热机制缓解缓存争抢问题。
想获取更多高质量的Java技术文章?欢迎访问 Java技术小馆官网,持续更新优质内容,助力技术成长!
评论记录:
回复评论: